Dr. J's Compiler and Translator Design Lecture Notes
(C) Copyright 2011-2019 by Clinton Jeffery and/or original authors where
appropriate. For use in Dr. J's Compiler classes only. Lots of material
in these notes originated with Saumya Debray's Compiler course notes from
the University of Arizona, for which I owe him a debt of thanks. Various
portions of his notes were in turn inspired by the ASU red dragon book.
lecture #1 began here
Syllabus
Yes, we went over the syllabus.
Why study compilers?
Computer scientists study compiler construction for the
following reasons:
- Experience with large-scale
applications development. Your compiler may be the largest
program you write as a student. Experience working with really big
data structures and complex interactions between algorithms will
help you out on your next big programming project.
- A shining triumph of CS theory.
It demonstrates the value of theory over the impulse to just "hack up"
a solution.
- A basic element of programming language research.
Many language researchers write compilers for the languages they design.
- Many applications have similar properties to one or more phases of
a compiler, and compiler expertise and tools can help an application
programmer working on other projects besides compilers.
CS 445 is labor intensive. This is a good thing: there is no way to
learn the skills necessary for writing big programs without this kind
of labor-intensive experience.
Some Tools we will use
Labs and lectures will discuss all of these, but if you do not know them
already, the sooner you go learn them, the better.
- C and "make".
- If you are not expert with these yet, you will be a lot closer
by the time you pass this class.
- lex and yacc
- These are compiler-writers tools, but they are useful for other
kinds of applications, almost anything with a complex file format
to read in can benefit from them.
- gdb
- If you do not know a source-level debugger well, start learning.
You will need one to survive this class.
- e-mail
- Regularly e-mailing your instructor is a crucial part of class
participation. If you aren't asking questions, you aren't doing
your job as a student.
- web
- This is where you get your lecture notes, homeworks, and labs,
and turnin all your work.
Compilers - What Are They and What Kinds of Compilers are Out There?
The purpose of a compiler is: to translate a program in some language (the
source language) into a lower-level language (the target
language). The compiler itself is written in some language, called
the implementation language. To write a compiler you have to be
very good at programming in the implementation language, and have to
think about and understand the source language and target language.
There are several major kinds of compilers:
- Native Code Compiler
- Translates source code into hardware (assembly or machine code)
instructions. Example: gcc.
- Virtual Machine Compiler
- Translates source code into an abstract machine code, for execution
by a virtual machine interpreter. Example: javac.
- JIT Compiler
- Translates virtual machine code to native code. Operates within
a virtual machine. Example: Sun's HotSpot java machine.
- Preprocessor
- Translates source code into simpler or slightly lower level source code,
for compilation by another compiler. Examples: cpp, m4.
- Pure interpreter
- Executes source code on the fly, without generating machine code.
Example: Lisp.
OK, so a pure interpreter is not really a compiler. Here are some more tools,
by way of review, that compiler people might be directly concerned with, even
if they are not themselves compilers.
You should learn any of these terms that you don't already know.
- assembler
- a translator from human readable (ASCII text) files of machine
instructions into the actual binary code (object files) of a machine.
- linker
- a program that combines (multiple) object files to make an executable.
Converts names of variables and functions to numbers (machine addresses).
- loader
- Program to load code. On some systems, different executables start at
different base addresses, so the loader must patch the executable with
the actual base address of the executable.
- preprocessor
- Program that processes the source code before the compiler sees it.
Usually, it implements macro expansion, but it can do much more.
- editor
- Editors may operate on plain text, or they may be wired into the rest
of the compiler, highlighting syntax errors as you go, or allowing
you to insert or delete entire syntax constructs at a time.
- debugger
- Program to help you see what's going on when your program runs.
Can print the values of variables, show what procedure called what
procedure to get where you are, run up to a particular line, run
until a particular variable gets a special value, etc.
- profiler
- Program to help you see where your program is spending its time, so
you can tell where you need to speed it up.
Phases of a Compiler
- Lexical Analysis:
- Converts a sequence of characters into words, or tokens
- Syntax Analysis:
- Converts a sequence of tokens into a parse tree
- Semantic Analysis:
- Manipulates parse tree to verify symbol and type information
- Intermediate Code Generation:
- Converts parse tree into a sequence of intermediate code instructions
- Optimization:
- Manipulates intermediate code to produce a more efficient program
- Final Code Generation:
- Translates intermediate code into final (machine/assembly) code
Example of the Compilation Process
Consider the example statement; its translation to machine code
illustrates some of the issues involved in compiling.
position = initial + rate * 60
|
30 or so characters, from a single line of source code, are first
transformed by lexical analysis into a sequence of 7 tokens. Those
tokens are then used to build a tree of height 4 during syntax analysis.
Semantic analysis may transform the tree into one of height 5, that
includes a type conversion necessary for real addition on an integer
operand. Intermediate code generation uses a simple traversal
algorithm to linearize the tree back into
a sequence of machine-independent three-address-code instructions.
t1 = inttoreal(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3 |
Optimization of the intermediate code allows the four instructions to
be reduced to two machine-independent instructions. Final code generation
might implement these two instructions using 5 machine instructions, in
which the actual registers and addressing modes of the CPU are utilized.
MOVF id3, R2
MULF #60.0, R2
MOVF id2, R1
ADDF R2, R1
MOVF R1, id1
|
Reading!
-
Read the Louden text chapters 1-2. Except you may SKIP the parts that
describe the TINY project. Within the Scanning chapter, there are large
portions on the finite automata that should be CS 385 review; you may
SKIM that material, unless you don't know it or don't remember it.
-
Read Sections 3-5 of the Flex manual,
Lexical Analysis With Flex.
- Read the class lecture notes
as fast as we manage to cover topics. Please ask questions about
whatever is not totally clear. You can Ask Questions in class or
via e-mail.
Although the whole course's lecture notes are ALL available to you
up front, I generally revise each lecture's notes, making additions,
corrections and adaptations to this year's homeworks, the night before each
lecture. The best time to print hard copies of the lecture notes, if you
choose to do that, is one
day at a time, right before the lecture is given. Or just read online.
Some Resources for the class Project and a Policy Statement
Class Dev+Test Linux Machine: historically we have used a generic
Linux server like "wormulon" to do (and grade) class work. This semester
our UI CS system admin, Victor, has created a virtual machine
specifically for this class (and separate ones for many other classes).
Our machine is named "cs-445.cs.uidaho.edu". Try it out
and report any problems to me.
Unlike software engineering, the compiler class project is a solo exercise,
meant to increase your skill at programming on a larger scale than in most
classes. On the one hand it is sensible to use software engineering tools
such as revision control systems (like git) on a large project like this.
On the other hand it is not OK to share your work with your classmates,
intentionally or through stupidity. If you use a revision control system,
figure out how to make it private. Various options:
- on github you setup private repositories, either for free or cheap
- you can use revision control with a local repository. setup is easy,
but if you do this, figure out how to back up your work.
- you can figure out how to do git through ssh onto a UI CS unix
account
Initial Discussion of HW#1
This one is on a tight fuse, please hit the ground running and seek
assistance if anything hinders your progress.
lecture #2 began here
Mailbag
- The vgo.html lists += and -= on both the "in VGo" and "not in VGo"
operator lists, what up with that?
- Good catch. += and -= are pretty easy and common operators so they
are in VGo and should not be on the "not in VGo" list. Fixed.
Getting Going
Last time, we ended sort of in the middle of a description of
Homework #1.
We need to finish that, but we also need some introductory material on
lexical analysis in order to understand parts of it. So we will come
back to HW#1 before the end of class.
Overview of Lexical Analysis
A lexical analyzer, also called a scanner, typically has the
following functionality and characteristics.
What is a "token" ?
In compilers, a "token" is:
- a single word of source code input (a.k.a. "lexeme")
- an integer code that refers to a single word of input
- a set of lexical attributes computed from a single word of input
Programmers think about all this in terms of #1. Syntax checking uses
#2. Error reporting, semantic analysis, and code generation require #3. In
a compiler written in C, for each token you allocate a C struct to store (3)
for each token.
Auxiliary data structures
You were presented with the phases of the compiler, from lexical and syntax
analysis, through semantic analysis, and intermediate and final code
generation. Each phase has an input and an output to the next phase.
But there are a few data structures
we will build that survive across multiple phases: the literal table,
the symbol table, and the error handler.
- lexeme table
- a table that stores lexeme values, such as strings and variable
names, that may occur in many places. Only one copy of each
unique string and name needs to be allocated in memory.
- symbol table
- a table that stores the names defined (and visible with) each
particular scope. Scopes include: global, and procedure (local).
More advanced languages have more scopes such as class (or record)
and package.
- error handler
- errors in lexical, syntax, or semantic analysis all need a common
reporting mechanism, that shows where the error occurred (filename,
line number, and maybe column number are useful).
Reading Named Files in C using stdio
In this class you are opening and reading files. Hopefully this is review
for you; if not, you will need to learn it quickly. To do any "standard
I/O" file processing, you start by including the header:
#include <stdio.h>
This defines a data type (FILE *) and gives prototypes for
relevant functions. The following code opens a file using a string filename,
reads the first character (into an int variable, not a char, so that it can
detect end-of-file; EOF is not a legal char value).
FILE *f = fopen(filename, "r");
int i = fgetc(f);
if (i == EOF) /* empty file... */
Command line argument handling and file processing in C
The following example is from Kernighan & Ritchie's "The C Programming
Language", page 162.
#include <stdio.h>
/* cat: concatenate files, version 1 */
int main(int argc, char *argv[])
{
FILE *fp;
void filecopy(FILE *, FILE *);
if (argc == 1)
filecopy(stdin, stdout);
else
while (--argc > 0)
if ((fp = fopen(*++argv, "r")) == NULL) {
printf("cat: can't open %s\n", *argv);
return 1;
}
else {
filecopy(fp, stdout);
fclose(fp);
}
return 0;
}
void filecopy(FILE *ifp, FILE *ofp)
{
int c;
while ((c = getc(ifp)) != EOF)
putc(c, ofp);
}
Warning: while using and adapting the above code would be fair game in this
class, the yylex() function is very different than the filecopy() function!
It takes no parameters! It returns an integer every time it finds a token!
So if you "borrow" from this example, delete filecopy() and write yylex()
from scratch. Multiple students have fallen into this trap before you.
A Brief Introduction to Make
It is not a good idea to write a large program like a compiler as a single
source file. For one thing, every time you make a small change, you would
need to recompile the whole program, which will end up being many thousands
of lines. For another thing, parts of your compiler may be generated by
"compiler construction tools" which will write separate files. In any case,
this class will require you to use multiple source files, compiled
separately, and linked together to form your executable program. This
would be a pain, except we have "make" which takes care of it for us.
Make uses an input file named "makefile", which stores in ASCII text form
a collection of rules for how to build a program from its pieces. Each
rule shows how to build a file from its source files, or dependencies.
For example, to compile a file under C:
foo.o : foo.c
gcc -c foo.c
The first line says to build foo.o you need foo.c, and the second line,
which must being with a tab, gave a command-line to
execute whenever foo.o should be rebuilt, i.e. when it is missing or
when foo.c has been changed and need to be recompiled.
The first rule in the makefile is what "make" builds by default, but
note that make dependencies are recursive: before it checks whether
it needs to rebuild foo.o from foo.c it will check whether foo.c needs
to be rebuilt using some other rule. Because of this post-order
traversal of the "dependency graph", the first rule in your makefile
is usually the last one that executes when you type "make". For a
C program, the first rule in your makefile would usually be the
"link" step that assembles objects files into an executable as in:
compiler: foo.o bar.o baz.o
gcc -o compiler foo.o bar.o baz.o
There is a lot more to "make" but we will take it one step at a time.
You can read or skim the
GNU make
manual, particularly section 2, to learn more about make.
You can find useful on-line documentation
on "make" (manual page, Internet reference guides, etc) if you look.
lecture #3 began here
Mailbag
- I've heard of malloc(), but I haven't had any real experience
working with it.
- malloc(), calloc() and realloc() are a flexible memory management
API for C that corresponds roughly to
new keyword in C++.
They let you
allocate memory generically by # of bytes, independent of the type
system. This capability is powerful but dangerous.
- My experience with flex and bison was way back in the
Programming Languages course.
- Same goes for most everybody; this background is what is expected.
You are to read and learn flex and bison from scratch if you don't
remember it. Your reading assignment should be pretty well finished
by now, and you should be ready for me to lecture on flex. We will
teach what is needed of them for this course, in this course.
- What should the lexical analyzer look like? where do I start?
- Homework #1 is about learn to use a declarative language called
Flex which does almost all the work for you. The only design
issue is how does it interact with the rest of the compiler, i.e.
its public interface. This is partly hardwired/designed for you
by flex, your only customization option is how to make token
information available to the later phases of the compiler.
- How should our output be visible?
- One human readable output line, per token, as shown in hw1.html
Build the linked list first, then walk it (visit all nodes) to
print the output. Figure out how to do this so output is in the
correct order and not reversed!
- Are there any comments in VGo?
- Yes, VGo supports //. You are also required to recognize, handle,
and emit an error message if you find any /* ... */ comments.
- You mention storing the int and double as binary. That just means
storing them in int and double variables, correct?
- It means for constants you have to convert from the lexeme string
that actually appears in the source code to the value (int, double)
and then store the result in the corresponding lexical attribute
variable.
- When do you use
extern and when do you use
#include in C programming?
-
extern can be done without an #include,
to tell one module
about global variables defined in another module. But if you are
going to share that extern with multiple modules, it
is best to put it in an #include.
More generally, use #include in order to share types,
externs, function prototypes,
and symbolic #define's across multiple files. That is all.
No code, which is to say, no function bodies.
- Can I add parameters to
yylex()?
- No, you can't add your own parameters,
yylex() is a
public interface.
You might be tempted to return a token structure pointer, or
add some parameters to tell it what filename it is reading from.
But you can't. Leave yylex()'s interface alone,
the parser will call it with its current interface.
- Do you want us to have a .h file for enumerating all the different
kind of tokens for HW 1? I was looking into flex and bison and it
looks like bison creates a tab.h file that does this automatically.
- Yes. In HW1 you create a .h file for these defines; plan to throw it
away in favor of the one Bison creates for you in HW#2.
- Are you going to provide us the list of tokens required, or the .h file?
- No, I am providing a language reference, from which you are to make the
list. But by asking the right questions, you are making me add details
to the language reference. Out of mercy, I went and dug out the list
of integer codes used in an early version of the Go compiler, and put it
in a vgo.tab.h that you may use. It is not
guaranteed to be complete or correct. Specifically, it does not seem to
include built-in type names, which almost surely have to be distinguished
from identifiers (variable names)...
- Will you always call "make" on our submissions?
- Yes. I expect you to use make and provide a makefile in each
homework. Turn in the whole source, not just "changed" or
"new" files for some assignments. My script will
unpack your .zip file by saying "unzip" in some new test directory
and then run "make" and then run your executable. If
anything goes wrong (say, you unzipping into a subdirectory the script
does not know the name of) you will lose a few points.
On the other hand, I do not want the tool-generated files
(lex.yy.c, cgram.tab.c) or .o or executables. The makefile should
contain correct dependencies to rerun flex (and later, bison) and
generate these files whenever source (.l, .y , etc.) files are changed.
Regular Expressions
The notation we use to precisely capture all the variations that a given
category of token may take are called "regular expressions" (or, less
formally, "patterns". The word "pattern" is really vague and there are
lots of other notations for patterns besides regular expressions).
Regular expressions are a shorthand notation
for sets of strings. In order to even talk about "strings" you have
to first define an alphabet, the set of characters which can
appear.
- Epsilon (ε) is a regular expression denoting the set
containing the empty string
- Any letter in the alphabet is also a regular expression denoting
the set containing a one-letter string consisting of that letter.
- For regular expressions r and s,
r | s
is a regular expression denoting the union of r and s
- For regular expressions r and s,
r s
is a regular expression denoting the set of strings consisting of
a member of r followed by a member of s
- For regular expression r,
r*
is a regular expression denoting the set of strings consisting of
zero or more occurrences of r.
- You can parenthesize a regular expression to specify operator
precedence (otherwise, alternation is like plus, concatenation
is like times, and closure is like exponentiation)
Lex/Flex Extended Regular Expressions
Although the basic regular expression operators given earlier
are sufficient to describe all regular languages,
in practice everybody uses extensions:
- For regular expression r,
r+
is a regular expression denoting the set of strings consisting of
one or more occurrences of r. Equivalent to rr*
- For regular expression r,
r?
is a regular expression denoting the set of strings consisting of
zero or one occurrence of r. Equivalent to r|ε
- The notation [abc] is short for a|b|c. [a-z] is short for a|b|...|z.
[^abc] is short for: any character other than a, b, or c.
What is a "lexical attribute" ?
A lexical attribute is a piece of information about a token. These typically
include:
| category | an integer code used to check syntax
|
| lexeme | actual string contents of the token
|
| line, column, file | where the lexeme occurs in source code
|
| value | for literals, the binary data they represent
|
Avoid These Common Bugs in Your Homeworks!
- yytext or yyinput were not declared global
- main() does not have its required argc, argv parameters!
- main() does not call yylex() in a loop or check its return value
- getc() EOF handling is missing or wrong! check EVERY all to getc() for EOF!
- opened files not (all) closed! file handle leak!
- end-of-comment code doesn't check for */
- yylex() is not doing the file reading
- yylex() does not skip multiple spaces, mishandles spaces at the front
of input, or requires certain spaces in order to function OK
- extra or bogus output not in assignment spec
- = instead of ==
lecture #4 began here
Mailbag
-
When creating the linked list I see that you have a struct token and a
struct tokenlist. Should I create my linked list this way or can I eliminate
the struct tokenlist and add a next pointer inside struct token(struct token
*next) and use that to connect my linked list?
-
The organization I specified - with two separate structs - was very
intentional. Next homework, we need the struct tokens that we allocate from
inside yylex(), but not the struct tokenlist that you allocate from outside
yylex(). You can do anything you want with the linked list structure, but
the struct token must be kept more-or-less as-is, and allocated inside
yylex() before it returns each time.
- I was wondering if we should have a different code for each keyword or just have a 'validkeyword' code and an 'invalidkeyword' code.
- Generally, you need a different code for two keywords if and when they are used in different positions in the syntax. For example, int and float are type names and are used in the same situations, but the keywords func and if, denoting the beginning of a function and the beginning of a conditional expression, have different syntax rules and need different integer codes.
Before we dive back in to regular expressions, let's waltz through some VGo,
and btw, take a peek at a possibly-perfect HW#1 makefile.
Some Regular Expression Examples
Regular expressions are the preferred notation for
specifying patterns of characters that define token categories. The best
way to get a feel for regular expressions is to see examples. Note that
regular expressions form the basis for pattern matching in many UNIX tools
such as grep, awk, perl, etc.
What is the regular expression for each of the different lexical items that
appear in C programs? How does this compare with another, possibly simpler
programming language such as BASIC? What are the corresponding rules for our
language this semester, are they the same as C?
| lexical category | BASIC | C | Go |
| operators | the characters themselves | For operators that are regular expression operators we need mark them
with double quotes or backslashes to indicate you mean the character,
not the regular expression operator. Note several operators have a
common prefix. The lexical analyzer needs to look ahead to tell
whether an = is an assignment, or is followed by another = for example.
| ??
|
| reserved words | the concatenation of characters; case insensitive |
Reserved words are also matched by the regular expression for identifiers,
so a disambiguating rule is needed.
| ??
|
| identifiers | no _; $ at ends of some; 2 significant letters!?; case insensitive | [a-zA-Z_][a-zA-Z0-9_]*
| Same a C; only difference is that starting with a Capital specifies
public members of a package.
|
| numbers | ints and reals, starting with [0-9]+ | 0x[0-9a-fA-F]+ etc.
| Go has C literals, plus imaginary/complex numbers.
|
| comments | REM.* | C's comments are tricky regexp's
| ??
|
| strings | almost ".*"; no escapes | escaped quotes
| ??
|
| what else?
| ??
|
lex(1) and flex(1)
These programs generally take a lexical specification given in a .l file
and create a corresponding C language lexical analyzer in a file named
lex.yy.c. The lexical analyzer is then linked with the rest of your compiler.
The C code generated by lex has the following public interface. Note the
use of global variables instead of parameters, and the use of the prefix
yy to distinguish scanner names from your program names. This prefix is
also used in the YACC parser generator.
FILE *yyin; /* set this variable prior to calling yylex() */
int yylex(); /* call this function once for each token */
char yytext[]; /* yylex() writes the token's lexeme to an array */
/* note: with flex, I believe extern declarations must read
extern char *yytext;
*/
int yywrap(); /* called by lex when it hits end-of-file; see below */
The .l file format consists of a mixture of lex syntax and C code fragments.
The percent sign (%) is used to signify lex elements. The whole file is
divided into three sections separated by %%:
header
%%
body
%%
helper functions
The header consists of C code fragments enclosed in %{ and %} as well as
macro definitions consisting of a name and a regular expression denoted
by that name. lex macros are invoked explicitly by enclosing the
macro name in curly braces. Following are some example lex macros.
letter [a-zA-Z]
digit [0-9]
ident {letter}({letter}|{digit})*
A friendly warning: your UNIX/Linux/MacOS Flex tool is NOT
good at handling input files saved in MS-DOS/Windows format, with
carriage returns before each newline character. Some browsers,
copy/paste tools, and text editors might add these carriage returns
without you even seeing them, and then you might end up in Flex Hell
with cryptic error messages for no visible reason. Download with
care, edit with precision. If you need to get rid of carriage returns
there are lots of tools for that. You can even build them into your
makefile. The most classic UNIX tool for that task is tr(1), the
character translation utility
lecture #5 began here
- What up with Blackboard?
- I didn't make Blackboard available until recently. It and the submission
zone entry for HW#1 should be up now. Let me know if it is not.
- One of the examples uses the reserved word float, which is not in our
list. Do I need to support the reserved word float?
- No. You should only support float64, which is proper Go.
If you spot any improper Go in any example, please point me at it so I
can fix it.
- When will our Midterm be?
- The week of October 14-18. Let's vote on whether to hold the exam on
Oct 14, 15, 16, or 17 soon, like maybe tomorrow.
- In the specification for assignment 1 it says that we should accept
.go files and if there is no extension given add a .go to the filename.
Should we still accept and run our compiler on other file extensions
that could be provided or should we return an error of some sort?
- Accept no other extensions. If any file has an extension other than .go,
you can stop with a message like: "Usage: vgo [options] filename[.go] ..."
- When I add .go to filenames, my program is messing up its subsequent
command line arguments. What up with that?
- Well, I could make an educated guess, but if this machine has putty,
why don't we take a look?
- how am i supposed to import the lexor into my main.c file?
- Do not import or #include your lexer. Instead,
link your lexer into the executable, and tell
main()
how to call it, by providing a prototype for yylex().
If yylex()
sets any global variables (it does), you'd declare those as
extern. You can do prototypes and externs in main.c,
but these things are exactly what header (.h) files were invented for.
- Is the
struct token supposed to be in our
main()? Do we use yylex()
along with other variables within lex.yy.c to fill the "struct token" with
the required information?
- Rather than overwriting a global struct each time, a pointer
to a struct token should be in
main().
Function yylex() should allocate a struct token, fill it,
and make it visible to main(), probably by assigning its
address to some global pointer variable. Function main()
should build the linked list in a loop, calling yylex() each
time through the loop. It should then print the output by looping through
the linked list.
What are the Best Regular Expressions you can Write For VGo?
| Category | Regular Expression
|
| Variable names | [a-zA-Z_][a-zA-Z0-9_]*
|
| Integer constants | "-"?[0-9]+ | "0x"[0-9A-Fa-f]+
|
| Real # Constants | [0-9]*"."[0-9]+
|
| String Constants | \"([^"\n]|("\\\""))*\"
|
| Rune Constants |
|
| Complex # Constants |
|
Q: Why consider doing some of the harder ones in Go but not in VGo?
Q: What other lexical categories in VGo might give you trouble?
Flex Body Section
The body consists of of a sequence of regular expressions for different
token categories and other lexical entities. Each regular expression can
have a C code fragment enclosed in curly braces that executes when that
regular expression is matched. For most of the regular expressions this
code fragment (also called a semantic action consists of returning
an integer that identifies the token category to the rest of the compiler,
particularly for use by the parser to check syntax. Some typical regular
expressions and semantic actions might include:
" " { /* no-op, discard whitespace */ }
{ident} { return IDENTIFIER; }
"*" { return ASTERISK; }
"." { return PERIOD; }
You also need regular expressions for lexical errors such as unterminated
character constants, or illegal characters.
The helper functions in a lex file typically compute lexical attributes,
such as the actual integer or string values denoted by literals. One
helper function you have to write is yywrap(), which is called when lex
hits end of file. If you just want lex to quit, have yywrap() return 1.
If your yywrap() switches yyin to a different file and you want lex to continue
processing, have yywrap() return 0. The lex or flex library (-ll or -lfl)
have default yywrap() function which return a 1, and flex has the directive
%option noyywrap which allows you to skip writing this function.
You can avoid a similar warning for an unused unput() function by saying
%option nounput.
Note: some platforms with working Flex installs (I am told this includes
cs-445.cs.uidaho.edu, which runs CENTOS)
might not have a flex library, neither -ll or -lfl. Using %option directives
or providing your own dummy library functions are a solution to having
no flex library -lfl available.
Lexical Error Handling
- Really, two kinds of lexical errors: nonsense, and stuff in Go that's
not in VGo.
- Include file name and line number in your error messages.
- Avoid cascading error messages -- only print the first one you see
on a given line/function/source file.
- You can write regular expressions for common errors, in order
to give a better message than "lexical error" or "unrecognized character".
(This is how you should approach stuff in Go that's not in VGo.)
lecture #6 began here
Mailbag
- Are we going to talk about Multi-Line Comments, or what?
- Sure, let's talk about multi-line comments. Go recognizes C-style
/* comments */ like this. If we let you off the hook, we will surely
see .go input files with these comments where you will emit weird bogus
error messages. So we either allow these comments, or recognize and
specifically disallow them. We could take a vote. But how do you
write the regular expression for them? The regular expression for
these may be harder than you think. Many flex books will have
sneaky answers instead of just writing the regular expression.
I am a pragmatist.
- Do we really have to write our compilers in C? That's so lame!
- Despite its grievous flaws, C is by far the most powerful and
influential programming language ever invented.
Mastering C is more valuable than learning compiler construction,
otherwise I would surely be making you write your compiler in Unicon,
which would be WAYYYY easier.
That said, I have allowed students to write their compiler in
C++ or Python on the past, usually with poor results. If you have a
compelling story, I will listen to proposals for alternatives to C.
- When I compile my homework, my executable is named a.out, not vgo!
What do I do?
- Some of you who are less familiar with Linux should read the
"manual pages" for gcc, make, etc. gcc has a -o option, that would work.
Or in your makefile you could rename the file after building it.
- Can I use flex start conditions?
- Yes, if you need to, feel free.
- Can I have an extension?
- Yeah, but the further you fall behind, the more zeroes you end up with
for assignments that you don't do.
Late homeworks are accepted with a penalty per day (includes
weekend days) except in the case of a valid excused absence.
The penalty starts at 10% per day (HW#1), and reduces by 2% per
assignment (8%/day for HW#2, 6%/day for HW#3, 4%/day for HW#4,
and 2%/day for HW#5). I reserve the right to underpenalize.
- Do you accept and regrade resubmissions?
- Submissions are normally graded by a script in a batch.
Generally, if an initial submission was fail, I might accept a
resubmission for partial credit up to a passing (D) grade. If a
submission fails for a trivial reason such as a missing file, I might
ask you to resubmit with a lighter penalty.
- Just tried to download the example VGo programs and the link is broken
- Yeah, have to create example programs before the links will exist.
Working on it. If necessary, google a bunch of Go sample programs or
write your own.
- Should the extension be .g0 or .go?
- The extension is .go. ".g0" was the extension last year, for a language
that was not based on Go syntax. If you see links I need to update feel
free to provide pointers. But refresh your web browser cache first,
and make sure you are not looking at an old copy of the class page.
- I have not been able to figure out how sscanf() will help me. Could you
point me to an example or documentation.
- Yes. Note that sscanf'ing into a double calls
for a %lg.
- What is wrong with my commandline argument code.
- If it is not that you are overwriting the existing arrays with strcat()
instead of allocating new larger arrays in order to hold new longer
strings, then it is probably that you are using sizeof() instead of
strlen().
- Can you go over using the %array vs. the standard %pointer option
and if there are any potential benefits of using %array?
I was curious to see if you could use YYLMAX in junction
with %array to limit the size of identifiers, but there is
a probably a better way.
- After yylex() returns,
the actual input characters matched are available as a string named
yytext, and the number of input symbols matched are in yyleng. But is
yytext a char * or an array of char? Usually it doesn't matter in C,
but I personally have worked on a compiler where declaring an extern
for yytext in my other modules, and using the wrong one, caused a crash.
Flex has both pointer and array implementations available via %array
and %pointer declarations, so your compiler can use either. YYLMAX
is not a Flex thing, sorry, but how can we limit
the length of identifiers? Incidentally: I am astonished, to read
claims that the Flex scanner buffer doesn't automatically increase
in size as needed, and might be limited by default to 8K or so regexes.
If you write open-ended regular expressions, but might be advisable
in this day of big memory to say something like
i=stat(filename,&st);
yyin=fopen(filename,"r");
yy_current_buffer = yy_create_buffer(yyin, st.st_size);
to set flex so that it cannot experience buffer overrun. By the way,
Be sure to
check ALL your C library calls for error returns in this class!
- The O'Reilly book recommended using Flex states instead of that big
regular expression for C comments. Is that reasonable?
- Yes, you may implement the most elegant correct answer you can
devise, not just what you see in class.
- Are we free to explore non-optimal solutions?
- I do not want to read lots of extra pages of junk code, but you are free
to explore alternatives and submit the most elegant solution you come
up with, regardless of its optimality. Note that there are some parts
of the implementation that I might mandate. For example, the symbol table
is best done as a hash table. You could use some other fancy data
structure that you love, but if you give me a linked list I will be
disappointed. Then again, a working linked list implementation would get
more points than a failed complicated implementation.
- Is it OK to allocate a token structure inside main() after yylex()
returns the token?
- No. In the next phase of your compiler, you will not call
yylex(), the Bison-generated parser will call
yylex(). There is a way for
the parser to grab your token if you've stored it in a global variable,
but there is not a way for the parser to build the token structure itself.
However you are expected to allocate the linked list nodes in main(), and
in the next homework that linked list will be discarded. Don't get attached.
- My tokens' "text" field in my linked list are all messed up when I go
back through the list at the end. What do I do?
- Remember to make a physical copy of
yytext each token,
because it overwrites itself each time it matches a regular expression
in yylex(). Typically a physical copy of a C string is
made using strdup(), which is a malloc()
followed by strcpy().
- C++ concatenates adjacent string literals, e.g. "Hello" " world"
Does our lexer need to do that?
-
No, you do not have to do it.
But if you did, can you think of a way to get the job done without too
much pain?
It could be done in the lexer, in the parser, or sneakily in-between.
Be careful to consider 3+ adjacent string literals
("Hello" " world, " "how are you" and so on)
- How do I handle escapes in svals? Do I need to worry about more than
\n \t \\ and \r?
-
You replace the two-or-more characters with a single, encoded character.
'\\' followed by 'n' become a control-J character. We need
\n \t \\ and \" -- these are ubiquitous.
You can do additional ones like \r but they are not required and
will not be tested.
- What about ++ and -- ?
- Good point. I removed them from the not implemented
Go operators section, but didn't get them put in to
the table of VGo operators. Let's do increment/decrement.
On Go's standard library functions
I started with just Println, but it is pretty hard to write toy Go
programs if you can't read in input, and Go's input is almost as bad
as Java's. As you can see, it is pretty hard to get away from Go's
love of multiple assignment. What should we do?
reader = bufio.NewReader(os.Stdin)
text, _ = reader.ReadString('\n')
|

|
Lexing Reals
C float and double constants have to have at least one digit, either
before or after the required decimal. This is a pain:
([0-9]+.[0-9]* | [0-9]*.[0-9]+) ...
You might almost be happier if you wrote
([0-9]*.[0-9]*) { return (strcmp(yytext,".")) ? REAL : PERIOD; }
Starring: C's ternary operator e1 ? e2 : e3 is an if-then-else
expression, very slick. Note that if you have to support
scientific/exponential real numbers (JSON does), you'll need a bigger regex.
Lex extended regular expressions
Lex further extends the regular expressions with several helpful operators.
Lex's regular expressions include:
- c
- normal characters mean themselves
- \c
- backslash escapes remove the meaning from most operator characters.
Inside character sets and quotes, backslash performs C-style escapes.
- "s"
- Double quotes mean to match the C string given as itself.
This is particularly useful for multi-byte operators and may be
more readable than using backslash multiple times.
- [s]
- This character set operator matches any one character among those in s.
- [^s]
- A negated-set matches any one character not among those in s.
- .
- The dot operator matches any one character except newline: [^\n]
- r*
- match r 0 or more times.
- r+
- match r 1 or more times.
- r?
- match r 0 or 1 time.
- r{m,n}
- match r between m and n times.
- r1r2
- concatenation. match r1 followed by r2
- r1|r2
- alternation. match r1 or r2
- (r)
- parentheses specify precedence but do not match anything
- r1/r2
- lookahead. match r1 when r2 follows, without
consuming r2
- ^r
- match r only when it occurs at the beginning of a line
- r$
- match r only when it occurs at the end of a line
Lexical Attributes and Token Objects
Besides the token's category, the rest of the compiler may need several
pieces of information about a token in order to perform semantic analysis,
code generation, and error handling. These are stored in an object instance
of class Token, or in C, a struct. The fields are generally something like:
struct token {
int category;
char *text;
int linenumber;
int column;
char *filename;
union literal value;
}
The union literal will hold computed values of integers, real numbers, and
strings. In your homework assignment, I am requiring you to compute
column #'s; not all compilers require them, but they are easy. Also: in
our compiler project we are not worrying about optimizing our use of memory,
so am not requiring you to use a union.
lecture #7 began here
Mailbag
- Does VGo use a colon operator? The spec says no, but then it says yes.
- At present colon is not in VGo, thanks for the catch.
- Does HW#1 expect semi-colon insertion? It is not mentioned in the hw1
description but is in the VGo spec.
- We will need semi-colon insertion for HW#2 but it is not required for HW#1. Let's discuss.
- I was trying to come up with a regular expression for runes that are accepted in VGo.
I am having trouble finding what a rune looks like, and especially what the difference looks like for VGo vs Go.
Do you have any examples of Go vs VGo runes?
- The full Go literals spec is here.
VGo rune literals are basically C/C++ char literals. A VGo lexical
analyzer might want to start with a regex for a char literal, and then
add regex'es for things that are legal Go and not legal VGo. Here are
examples. There are also octal and hex escapes legal in Go but not in VGo.
| Regex | Interpretation
|
|---|
"'"[^\\\n]"'" | initial attempt at normal non-escaped runes
|
"'\\"[nt\\']"'" | a few legal VGo escaped runes
|
"'\\"[abfrv]"'" | legal in Go not in VGo escaped runes
|
"'\\u"[0-9a-fA-F]{4}"'" | legal in Go not in VGo
|
"'\\U"[0-9a-fA-F]{8}"'" | legal in Go not in VGo
|
- You mentioned that the next homework assignment, we won't be calling
yylex() from main() (which is why you previously
mentioned you cannot allocate the token structure in main()).
I have followed that rule,
but I question how will linked lists be set up in Homework #2 then?
- In HW#2 the linked list will be subsumed (that is, replaced) by you
building a tree data
structure. If you built a linked list inside
yylex(), that
would be a harmless waste of time and space and could be left in place.
If you malloc'ed the token structs inside yylex() but
built the linked list in your main(), your linked list
will just go away in HW#2 when we modify main() to call
the Bison parser function yyparse() instead of the loop
that repeatedly calls yylex().
- Can you test my scanner and see if I get an "A"?
- No.
- Can you post tests so I can see if my scanner gets an "A"?
- See these vgo sample files.
If you share additional tests that you devise, for example
when you have questions, I will add them to this collection
for use by the class.
- So if I run OK on these files, do I get an "A"?
- Maybe.
You should devise "coverage tests" to hit all described features.
-
Are we required to be using a lexical analysis error function lexerr()?
-
-
Whether you have a helper function with that particular name is up to you.
- You should report lexical errors in a manner that is helpful to the user.
Include line #, filename, and nature of the error if possible.
- Many lexical errors could consist of "Go token X is not legal in vgo".
- You are allowed to stop with an error exit status when you find an error.
-
The HW1 Specification says we are to use at least 2 separately compiled
.c files. Does Flex's generated lex.yy.c count as one of them,
or are you looking for yet another .c file, aside from lex.yy.c?
-
lex.yy.c counts. You may have more, but you should at least have a lex.yy.c
or other lex-compatible module, and a main function in a separate .c file
- For numbers, should we care about their size? What if an integer in
the .go file is greater than 2^64 ?
- We could ask: what does the Go compiler do. Or we could just say:
good catch, the VGo compiler would ideally range check and emit an error
if a value that doesn't fit into 64-bits occurs, for either the integer
or (less likely) float64 literals. Any ideas on how to detect an out
of range literal?
- I was using valgrind to test memory leaks and saw that there is a
leak-check=full option. Should I be testing that as well, or
just standard valgrind output with no options?
- You are welcome to use valgrind's memory-leak-finding capabilities, but
you are only being graded on whether your compiler performs illegal reads or
writes, including reads from uninitialized memory.
Playing with a Real Go Compiler
One way to tell what your compiler should do in VGo is to compare it with
what a real Go compiler does on any given input. I think we will have one
of these on the cs-445 machine for you to play with soon. I played with
one and immediately learned some things:
What to do about Go's standard library functions, cont'd
We will do a literal, minimalist interpretation of what is necessary
to support functions like reader.ReadString(). VGo will support two kinds of
calls: ones that return a single value, and ones that return a single value
plus a boolean flag that indicates whether the function succeeded or failed.
Flex Manpage Examplefest
To read a UNIX "man page", or manual page, you type "man command"
where command is the UNIX program or library function you need information
on. Read the man page for man to learn more advanced uses ("man man").
It turns out the flex man page is intended to be pretty complete, enough
so that we can draw some examples from it. Perhaps what you should figure
out from these examples is that flex is actually... flexible. The first
several examples use flex as a filter from standard input to standard
output.
- Line Counter/Word Counter
int num_lines = 0, num_chars = 0;
%%
\n ++num_lines; ++num_chars;
. ++num_chars;
%%
main()
{
yylex();
printf( "# of lines = %d, # of chars = %d\n",
num_lines, num_chars );
}
- Toy compiler example
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {
printf( "An integer: %s (%d)\n", yytext,
atoi( yytext ) );
}
{DIGIT}+"."{DIGIT}* {
printf( "A float: %s (%g)\n", yytext,
atof( yytext ) );
}
if|then|begin|end|procedure|function {
printf( "A keyword: %s\n", yytext );
}
{ID} printf( "An identifier: %s\n", yytext );
"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );
"{"[^}\n]*"}" /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
main( argc, argv )
int argc;
char **argv;
{
++argv, --argc; /* skip over program name */
if ( argc > 0 )
yyin = fopen( argv[0], "r" );
else
yyin = stdin;
yylex();
}
On the use of character sets (square brackets) in lex and similar tools
A student recently sent me an example regular expression for comments that read:
COMMENT [/*][[^*/]*[*]*]]*[*/]
One problem here is that square brackets are not parentheses, they do not nest,
they do not support concatenation or other regular expression operators. They
mean exactly: "match any one of these characters" or for ^: "match any one
character that is not one of these characters". Note also that you
can't use ^ as a "not" operator outside of square brackets: you
can't write the expression for "stuff that isn't */" by saying (^ "*/")
Finite Automata
Efficiency in lexical analyzers based on regular expressions is all about
how to best implement those wonders of CS 385: the finite automata. Today
we briefly review some highlights from theory of computation with an eye
towards implementation. Maybe I will accidentally describe something
differently than how you heard it before.
A finite automaton (FA) is an abstract, mathematical machine, also known as a
finite state machine, with the following components:
- A set of states S
- A set of input symbols E (the alphabet)
- A transition function move(state, symbol) : new state(s)
- A start state S0
- A set of final states F
The word finite refers to the set of states: there is a fixed size
to this machine. No "stacks", no "virtual memory", just a known number of
states. The word automaton refers to the execution mode: there is
no brain, not so much as a instruction set and sequence of instructions.
The entire logic is just a hardwired short loop that executes the same
instruction over and over:
while ((c=getchar()) != EOF) S := move(S, c);
What this "finite automaton algorithm" lacks in flexibility,
it makes up in speed.
lecture #8 began here
Mailbag
- My HW#1 grade sucked and I worked quite a bit on it.
- Yes. Let's discuss the grading scale. First, here's the distribution
of HW#1 grades:
10 10 10
9 9 9 9 9
8 8
7 7 7 7
6 6 6
5 5
4 4
1 1 1 1
- You are graded relative to your peers
- I do not use a 90/80/70/60 scale
- If your score was 6+ you are "fine"
- If your score was below 6, you could (and maybe should) fix and resubmit
for partial credit.
- Excused absences and negotiated circumstances may allow you to resubmit
or submit late, so long as that isn't abused.
- My C compiles say "implicit declaration of function"
- The C compiler requires a prototype (or actual function definition)
before it sees any calls to each function, in order to generate
correct code. On 64-bit platforms, treat this warning as an error.
DFAs
The type of finite automata that is easiest to understand and simplest to
implement is called a deterministic finite
automaton (DFA). The word deterministic here refers to the return
value of
function move(state, symbol), which goes to at most one state.
Example:
S = {s0, s1, s2}
E = {a, b, c}
move = { (s0,a):s1; (s1,b):s2; (s2,c):s2 }
S0 = s0
F = {s2}
Finite automata correspond in a 1:1 relationship to transition diagrams;
from any transition diagram one can write down the formal automaton in
terms of items #1-#5 above, and vice versa. To draw the transition diagram
for a finite automaton:
- draw a circle for each state s in S; put a label inside the circles
to identify each state by number or name
- draw an arrow between Si and Sj, labeled with x
whenever the transition says to move(Si, x) : Sj
- draw a "wedgie" into the start state S0 to identify it
- draw a second circle inside each of the final states in F
The Automaton Game
If I give you a transition diagram of a finite automaton, you can hand-simulate
the operation of that automaton on any input I give you.
DFA Implementation
The nice part about DFA's is that they are efficiently implemented
on computers. What DFA does the following code correspond to? What
is the corresponding regular expression? You can speed this code
fragment up even further if you are willing to use goto's or write
it in assembler.
state := S0
for(;;)
switch (state) {
case 0:
switch (input) {
'a': state = 1; input = getchar(); break;
'b': input = getchar(); break;
default: printf("dfa error\n"); exit(1);
}
case 1:
switch (input) {
EOF: printf("accept\n"); exit(0);
default: printf("dfa error\n"); exit(1);
}
}
Flex has extra complications. It accepts multiple regular expressions, runs
them all in parallel in one big DFA, and adds semantics to break ties. These
extra complications might be viewed as "breaking" the strict rules of DFA's,
but they don't really mess up the fast DFA implementation.
Deterministic Finite Automata Examples
A lexical analyzer might associate different final states with different
token categories. In this fragment, the final states are marked by
"return" statements that say what category to return. What is incomplete
or wrong here?
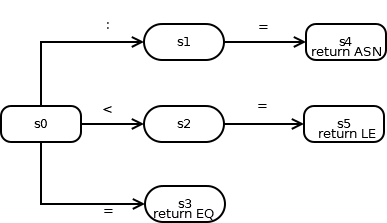
C Comments:
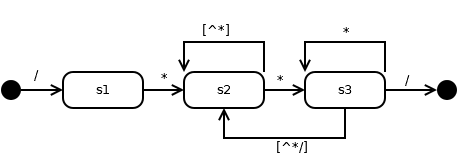
C Comments Redux
Nondeterministic Finite Automata (NFA's)
Notational convenience motivates more flexible machines in which function
move() can go to more than one state on a given input symbol, and some
states can move to other states even without consuming an input symbol
(ε-transitions).
Fortunately, one can prove that for any NFA, there is an equivalent DFA.
They are just a notational convenience. So, finite automata help us get
from a set of regular expressions to a computer program that recognizes
them efficiently.
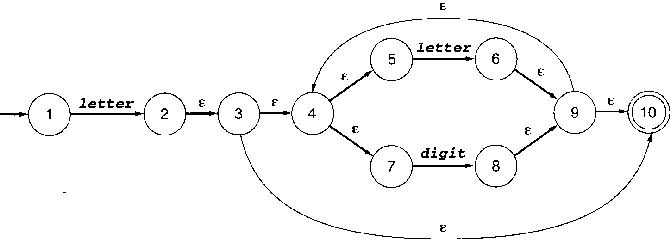
NFA Examples
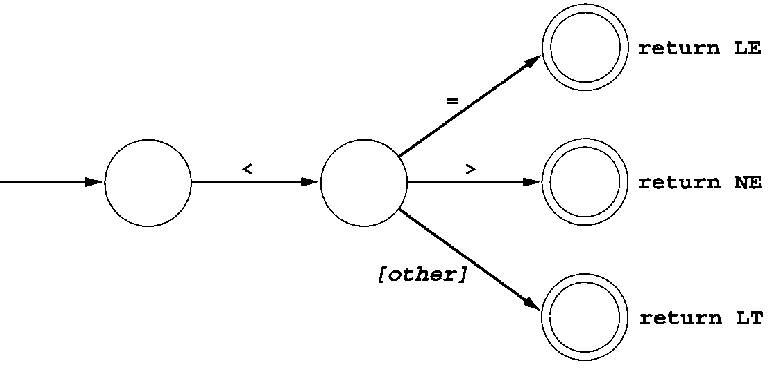
ε-transitions make it simpler to merge automata:
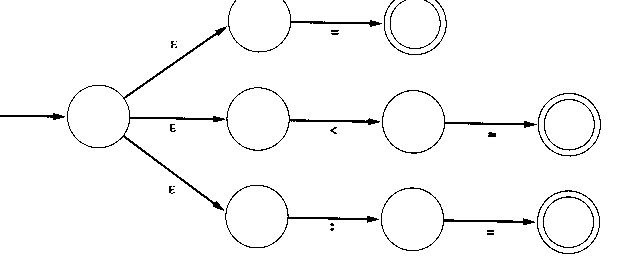
multiple transitions on the same symbol handle common prefixes:
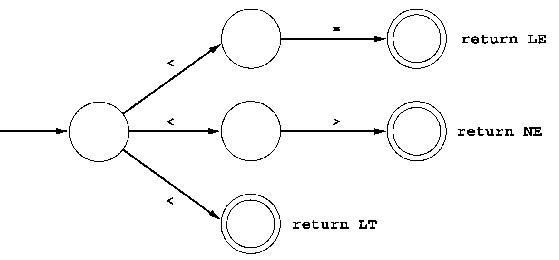
factoring may optimize the number of states. Is this picture OK/correct?
C Pointers, malloc, and your future
For many of you success as a computer scientist may boil down to what it
will take for you to master the concept of dynamically allocated memory,
and whether you are willing to do that. In C this means pointers and the
malloc() family of functions. Here are some tips:
- Draw "memory box" pictures of your variables. Pencil and paper
understanding of memory leads to correct running programs.
- Always initialize local pointer variables. Consider this code:
void f() {
int i = 0;
struct tokenlist *current, *head;
...
foo(current)
}
Here, current is passed in as a parameter to foo, but it is a
pointer that hasn't been pointed at anything. I cannot tell you how many
times I personally have written bugs myself or fixed bugs in student code,
caused by reading or writing to pointers that weren't pointing at anything
in particular. Local variables that weren't initialized point at random
garbage. If you are lucky this is a coredump, but you might not be lucky,
you might not find out where the mistake was, you might just get a wrong answer.
This can all be fixed by
struct tokenlist *current = NULL, *head = NULL;
- Avoid this common C bug:
struct token *t = (struct token *)malloc(sizeof(struct token *)));
This compiles, but causes coredumps during program execution. Why?
- Check your
malloc() return value to be sure it is not
NULL. Sure, modern programs have big memories so you think they will "never
run out of memory". Wrong. malloc() can return NULL even on
big machines. Operating systems often place limits on memory far beneath
the hardware capabilities. wormulon (or cs-course42) is likely a conspicuous
example. Machine shared across 40 users? You may have a lower memory
limit than you think.
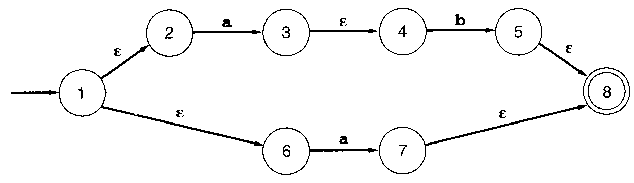
NFA examples - from regular expressions
Can you draw an NFA corresponding to the following?
(a|c)*b(a|c)*
(a|c)*|(a|c)*b(a|c)*
(a|c)*(b|ε)(a|c)*
Regular expressions can be converted automatically to NFA's
Each rule in the definition of regular expressions has a corresponding
NFA; NFA's are composed using ε transitions. This is called
"Thompson's construction" ).
We will work
examples such as (a|b)*abb in class and during lab.
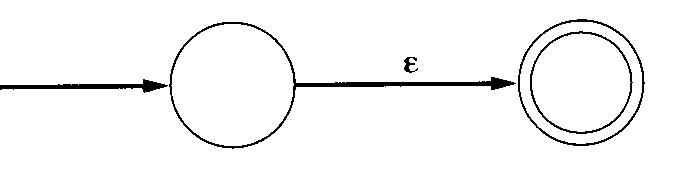
- For ε, draw two states with a single ε transition.
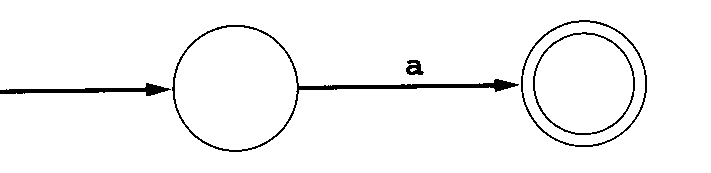
- For any letter in the alphabet,
draw two states with a single transition labeled with that letter.
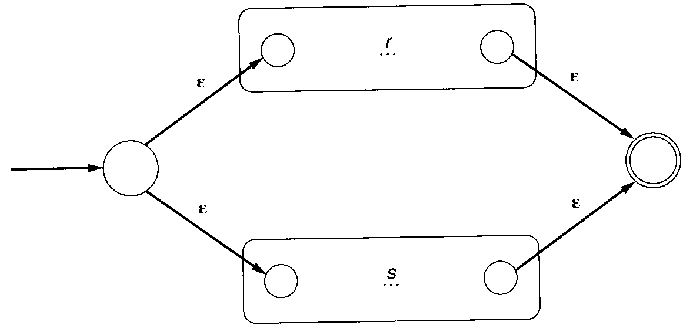
- For regular expressions r and s, draw r | s
by adding a new start state with ε transitions to the start
states of r and s, and a new final state with ε transitions
from each final state in r and s.
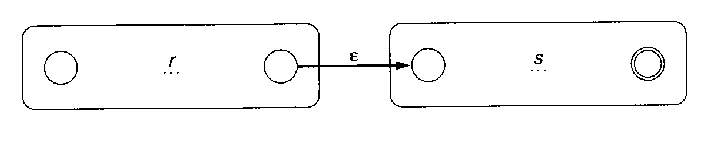
- For regular expressions r and s, draw rs
by adding ε transitions from the final states of r to the
start state of s.
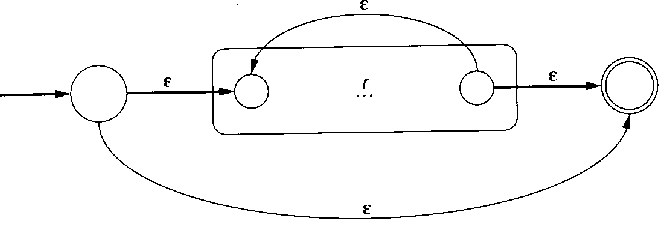
- For regular expression r, draw r*
by adding new start and final states, and ε transitions
- from the start state to the final state,
- from the final state back to the start state,
- from the new start to the old start and from the old final
states to the new final state.
- For parenthesized regular expression (r) you can use the NFA for r.
lecture #9 began here
Mailbag
- Go has four different kinds of literal constants, but for HW#2,
the grammar one thing, LLITERAL, what up?
- You are correct. If you return four different codes for four different
types of literals, you have to modify the grammar to replace LLLITERAL
with a grammar rule that allows your four integer codes. Alternatively,
you can have your four (or more) different flex regular expressions for
different kinds of literal constants, all return the LLITERAL integer.
- How do I deal with semi-colons?
- For HW#1, hopefully you just added an integer token category for them,
and returned that integer if you
saw one, even though explicit semi-colons are infrequent
in source code. For HW#2 your options are to write a grammar
that doesn't need semi-colons and works anyhow, or write a grammar that
needs semi-colons, and perform semi-colon insertion.
- What do you mean, for ival/dval/sval, by telling us to
"store binary value here"
- A binary value is the actual native representation that corresponds to
the string of ASCII codes that is the lexeme, for example what you get when
you call atoi("1234") for the token "1234".
- I am getting a lot of "unrecognized rule" errors in my .l file
- Look for problems with regular expressions or semantic actions prior to
the first reported error. If you need better diagnosis, find a way to
show me your code. One student saw these errors because they omitted
the required space between their regular expressions and their C semantic
actions.
- Do you have any cool tips to share regarding the un-escaping of special
characters?
- Copy character-by-character from the yytext into
a newly allocated array. Every escape sequence of multiple characters in yytext
represents a single character in
sval. Inside your loop copying characters from yytext into sval,
if you see a backslash in yytext, skip it and use a switch statement
on the next character. See below for additional discussion.
-
How can we represent and print out the binary value in ival and dval?
Wouldn't both ival and dval need to be char arrays types to actually display
a "binary representation"?
-
You do NOT have to convert to a binary string representation or output anything
in 0b010101010000 format.
-
Is a function name also an identifier?
-
Yes.
The Go designers probably had good reason to include semi-colons in the Go
grammar, to facilitate parsing, but they didn't want code to require them
99% of the time, so they introduced semi-colon insertion, an idea that they
borrowed from other languages.
- At a newline, semi-colon is inserted if the last token was
- identifier
- literal (number, rune, or string)
- break, continue, fallthrough, or return
- ++ -- ) ] or }
- "a semi-colon may be omitted before a closing ) or }"
What does (2) even mean? Automatic ; insertion before every ) or }?
Or just that the grammar handles an optional semi-colon in those spots?
Ways to Implement Semi-colon Insertion
- preprocessor
- you could write a pre-pass that does nothing but semi-colon insertion
- layered in between yylex() and yyparse()
- you could rename the yylex() generated by flex to be yylex2(), and
write a new yylex() that returns a semi-colon if conditions are right,
and otherwise just calls yylex2(). You'd have to have some global or
static memory for (1) what was the last token and (2) whether we saw
a newline
- within the regular expression for newline?
- not quite general enough, but you could return a semi-colon integer
when you see a newline whose previous token met the conditions
- layered inside yylex's C semantic actions
- a student figured out that one can do semi-colon insertion inside
a helper function called from each flex semantic action. The function,
if it substitutes a semi-colon for what is normally returned, has to
save/remember what it was going to return, and return it later. The
trick here is: if you inserted a semi-colon and saved your found token,
you return the saved token after you have scanned your next
token. In that case, you need to save thattoken somehow;
one way is to tell flex to back up via yyless(0).
NFA's can be converted automatically to DFA's
In: NFA N
Out: DFA D
Method: Construct transition table Dtran (a.k.a. the "move function").
Each DFA state is a set of
NFA states. Dtran simulates in parallel all possible moves N can make
on a given string.
Operations to keep track of sets of NFA states:
- ε_closure(s)
- set of states reachable from state s via ε
- ε_closure(T)
- set of states reachable from any state in set T via ε
- move(T,a)
- set of states to which there is an NFA transition from states in T on symbol a
NFA to DFA Algorithm:
Dstates := {ε_closure(start_state)}
while T := unmarked_member(Dstates) do {
mark(T)
for each input symbol a do {
U := ε_closure(move(T,a))
if not member(Dstates, U) then
insert(Dstates, U)
Dtran[T,a] := U
}
}
HW #1 Tips
These comments are based on historical solutions. I learned a lot from my
older siblings when I was young. Consider this your opportunity to learn
from your Vandal forebears' mistakes.
- better solutions' lexer actions looked like
...regex... { return token(TERMSYM); }
-
where token() allocates a token structure, sets a global variable to
point to it, and returns the same integer category that it is passed
from yylex(), so yylex() in turn returns this value.
- Put in enough line breaks.
-
Use <= 80 columns in your code, so that it prints readably.
- Comment non-trivial helper functions. Comment non-trivial code.
- Comment appropriate for a CS professional reader, not a newbie tutorial.
I know what i++ does, you do not have to tell me.
- Do not leave in commented-out debugging code or whatever.
- I might miss, and misgrade, your good output if I can't see it.
- Fancier formatting might calculate field widths from actual data
and use a variable to specify field widths in the printf.
- You don't
have to do this, but if you want to it is not that hard.
- Remind yourself of the difference between NULL and '\0' and 0
- NULL is used for pointers. The NUL byte '\0' terminates strings. 0
is a different size from NULL on many 64-bit compilers. Beware.
- Avoid O(n2) or worse, if at all possible
- It is possible to write bad algorithms that work, but it is better
to write good algorithms that work.
- Avoid big quantities of duplicate code
- You will have to use and possibly extend this code all semester.
- Use a switch when appropriate instead of long chain of if-statements
- Long chains of if statements are actually slow and less readable.
- On strings, allocate one byte extra for NUL.
- This common 445 problem causes valgrind trouble, memory violations etc.
- On all pointers, don't allocate and then just point the pointer
someplace else
- This common student error results in, at least, a memory leak.
- Don't allocate the same thing over and over unless copies may need
to be modified.
- This is often a performance problem.
- Check all allocations and fopen() calls for NULL return (good to have helper functions).
- C library functions can fail. Expect and check for that.
- Beware losing the base pointer that you allocated.
- You can only free()
if you still know where the start of what you allocated was.
- Avoid duplicate calls to strlen()
- especially in a loop! (Its O(n2))
- Use strcpy() instead of strncpy()
- unless you are really copying only part of a string, or
copying a string into a limited-length buffer.
- You can't
malloc() in a global initializer
-
malloc() is a runtime allocation from a memory
region that does not
exist at compile or link time. Globals can be initialized, but not to
point at memory regions that do not exist until runtime.
- Don't use raw constants like 260
- use symbolic names, like LEFTPARENTHESIS or LP
- The vertical bar (|) means nothing inside square brackets!
- Square brackets are an implicit shortcut for a whole lot of ORs
- If you don't allocate your token inside yylex() actions...
- You'll have to go back and do it, you need it for HW#2.
- If your regex's were broken
- If you know it, and were lazy, then fix it. If you don't know it,
then good luck on the midterm and/or final, you need to learn these,
and devise some (hard) tests!
On resizing arrays in C
The sval attribute in the homework is a perfect example of a problem which a
Business (MIS) major might not be expected to solve well, but a CS major
should be able to do by the time they graduate. This is not to encourage
any of you to consider MIS, but rather, to encourage you to learn how to
solve problems like these.
The problem can be summarized as: step through yytext, copying each character
out to sval,
looking for escape sequences.
Space allocated with malloc() can be increased in size by realloc().
realloc() is awesome. But, it COPIES and MOVES the old chunk of
space you had to the new, resized chunk of space, and frees the old
space, so you had better not have any other pointers pointing at
that space if you realloc(), and you have to update your pointer to
point at the new location realloc() returns.
There is one more problem: how do we allocate memory for sval, and how big
should it be?
- Solution #1: sval = malloc(strlen(yytext)+1) is very safe, but wastes
space.
- Solution #2: you could malloc a small amount and grow the array as
needed.
sval = strdup("");
...
sval = appendstring(sval, yytext[i]); /* instead of sval[j++] = yytext[i] */
where the function appendstring could be:
char *appendstring(char *s, char c)
{
i = strlen(s);
s = realloc(s, i+2);
s[i] = c;
s[i+1] = '\0';
return s;
}
Note: it is very inefficient to grow your array one character at
a time; in real life people grow arrays in large chunks at a time.
- Solution #3: use solution one and then shrink your array when you
find out how big it actually needs to be.
sval = malloc(strlen(yytext)+1);
/* ... do the code copying into sval; be sure to NUL-terminate */
sval = realloc(sval, strlen(sval)+1);
Practice converting NFA to DFA
OK, you've seen the algorithm, now can you use it?
...
...did you get:

OK, how about this one:
lecture #10 began here
Syntax Analysis
Parsing is the act of performing syntax analysis to verify an input
program's compliance with the source language. A by-product of this process
is typically a tree that represents the structure of the program.
Context Free Grammars
A context free grammar G has:
- A set of terminal symbols, T
- A set of nonterminal symbols, N
- A start symbol, s, which is a member of N
- A set of production rules of the form A -> ω,
where A is a nonterminal and ω is a string of terminal and
nonterminal symbols.
A context free grammar can be used to generate strings in the
corresponding language as follows:
let X = the start symbol s
while there is some nonterminal Y in X do
apply any one production rule using Y, e.g. Y -> ω
When X consists only of terminal symbols, it is a string of the language
denoted by the grammar. Each iteration of the loop is a
derivation step. If an iteration has several nonterminals
to choose from at some point, the rules of derviation would allow any of these
to be applied. In practice, parsing algorithms tend to always choose the
leftmost nonterminal, or the rightmost nonterminal, resulting in strings
that are leftmost derivations or rightmost derivations.
Context Free Grammar Examples
Well, OK, so how much of the C language grammar can we come up
with in class today? Start with expressions, work on up to statements, and
work there up to entire functions, and programs.
Context Free Grammar Example (from BASIC)
How many terminals and non-terminals does the grammar below use?
Compared to the little grammar we started last time, how does this rate?
What parts make sense, and what parts seem bogus?
Program : Lines
Lines : Lines Line
Lines : Line
Line : INTEGER StatementList
StatementList : Statement COLON StatementList
StatementList : Statement
Statement: AssignmentStatement
Statement: IfStatement
REMark: ... BASIC has many other statement types
AssignmentStatement : Variable ASSIGN Expression
Variable : IDENTIFIER
REMark: ... BASIC has at least one more Variable type: arrays
IfStatement: IF BooleanExpression THEN Statement
IfStatement: IF BooleanExpression THEN Statement ELSE Statement
Expression: Expression PLUS Term
Expression: Term
Term : Term TIMES Factor
Term : Factor
Factor : IDENTIFIER
Factor : LEFTPAREN Expression RIGHTPAREN
REMark: ... BASIC has more expressions
Mailbag
Really, I want to thank all of you who are sending me juicy questions
by e-mail.
- I am trying to get a more basic picture of the communication that happens between Flex and Bison. From my understanding:
- main() calls yyparse()
- yyparse() calls yylex()
- yylex() returns tokens from the input as integer values which are enumerated to text for readability to the .y file
- yyparse() tries to match these integers against rules of our grammar
(if it unsuccessful it errors (shift/reduce, reduce/reduce, unable to parse))
Is this correct?
- 1-3 are correct. 3 also includes: yylex() sets a global variable so that
yyparse() can pickup the lexical attributes, e.g. a pointer to struct token.
4 is correct except that shift/reduce and reduce/reduce conflicts are found
at bison time, not at yyparse() runtime. But yes yyparse() can find syntax
errors and we have to report them meaningfully.
- Does
yylval have any use to us? In CS 210 we did a
calculator and it was used to bring the value of the token into the parser.
- Yes,
yylval is how yyparse() picks up lexical attributes.
We will talk about it more in class.
- How would we add artificial tokens, like the semi-colon, without skipping
real tokens when we return?
- Save the real, found token in a global or static, or figure out a way to
push it back onto the input stream. Easiest is a one-token saved (pointer to
a) token struct.
- Since we are adding semi-colons without knowledge
of the grammar how do we avoid simply putting a semi-colon at the end of
every line? Is there a set group of tokens that can't add semi-colons?
- You make an interesting point that one could maybe do semi-colon
insertion with guidance from the parser, but it is intended that it be
done in the way described previously in class: classify every token as
to whether it is a legal statement-beginner, and whether it is a legal
statement-ender. Insert semi-colons at newlines between an ender and
a beginner. Example classification (via an array of booleans or whatever):
| token | Beginner? | Ender?
|
|---|
| x | yes | yes
|
| 1 | no? | yes
|
| if | yes | no
|
| ( | yes | no
|
| ) | no | yes
|
| + | no? | no
|
| - | no? | no
|
- How can I make Bison use a different yylex in order to allow for
semi-colon insertion?
- Two possibilities come to mind:
- Modify output of bison to replace the call to yylex() with myyylex(),
- Modify output of flex to change its declaration of yylex to realyylex()
A traditional Linux tool for sneaky stuff like this is
sed(1), which could be invoked from your makefile.
- Does VGo support both statements with semi-colons and statements without
semi-colons?
- Go does. VGo probably should, but if you figured out a way to hack
the grammar to not use semi-colons and still recognize all of VGo,
it would be pretty OK to only support statements without semicolons.
- Does VGo support empty statements?
- Most C-based grammars allow these. Occasionally I find them handy.
I would say they are optional for your compiler.
Grammar Ambiguity
The grammar
E -> E + E
E -> E * E
E -> ( E )
E -> ident
allows two different derivations for strings such as "x + y * z".
The grammar is ambiguous, but the semantics of the language dictate
a particular operator precedence that should be used. One way to
eliminate such ambiguity is to rewrite the grammar. For example,
we can force the precedence we want by adding some nonterminals and
production rules.
E -> E + T
E -> T
T -> T * F
T -> F
F -> ( E )
F -> ident
Given the arithmetic expression grammar from last lecture:
How can a program figure that x + y * z is legal?
How can a program figure out that x + y (* z) is illegal?
YACC
YACC ("yet another compiler compiler") is a popular tool which originated at
AT&T Bell Labs. YACC takes a context free grammar as input, and generates a
parser as output. Several independent, compatible implementations (AT&T
yacc, Berkeley yacc, GNU Bison) for C exist, as well as many implementations
for other popular languages. There also exist other more "modern" parser
generators, but they are often less portable and are
heavily inspired/influenced by YACC so it is what we will study.
YACC files end in .y and take the form
declarations
%%
grammar
%%
subroutines
The declarations section defines the terminal symbols (tokens) and
nonterminal symbols. The most useful declarations are:
- %token a
- declares terminal symbol a; YACC can generate a set of #define's
that map these symbols onto integers, in a y.tab.h file. Note: don't
#include your y.tab.h file from your grammar .y file, YACC generates the
same definitions and declarations directly in the .c file, and including
the .tab.h file will cause duplication errors.
- %start A
- specifies the start symbol for the grammar (defaults to nonterminal
on left side of the first production rule).
The grammar gives the production rules, interspersed with program code
fragments called semantic actions that let the programmer do what's
desired when the grammar productions are reduced. They follow the
syntax
A : body ;
Where body is a sequence of 0 or more terminals, nonterminals, or semantic
actions (code, in curly braces) separated by spaces. As a notational
convenience, multiple production rules may be grouped together using the
vertical bar (|).
Bottom Up Parsing (How Does Bison's yyparse() Work?)
Bottom up parsers start from the sequence of terminal symbols and work
their way back up to the start symbol by repeatedly replacing grammar
rules' right hand sides by the corresponding non-terminal. This is
the reverse of the derivation process, and is called "reduction".
Example. For the grammar
(1) S->aABe
(2) A->Abc
(3) A->b
(4) B->d
the string "abbcde" can be parsed bottom-up by the following reduction
steps:
abbcde
aAbcde
aAde
aABe
S
Handles
Definition: a handle is a substring that
- matches a right hand side of a production rule in the grammar and
- whose reduction to the nonterminal on the left hand side of that
grammar rule is a step along the reverse of a rightmost derivation.
Shift Reduce Parsing
A shift-reduce parser performs its parsing using the following structure
Stack Input
$ ω$
At each step, the parser performs one of the following actions.
- Shift one symbol from the input onto the parse stack
- Reduce one handle on the top of the parse stack. The symbols
from the right hand side of a grammar rule are popped off the
stack, and the nonterminal symbol is pushed on the stack in their place.
- Accept is the operation performed when the start symbol is alone
on the parse stack and the input is empty.
- Error actions occur when no successful parse is possible.
lecture #11 began here
Reading Assignment
Clarifying the reading assignment from last lecture:
- (maybe previously assigned) Read Louden Chapter 3, section 1-6.
You can skip the Tiny language description in 3.7.
- It was suggested that you read the Louden section on YACC or the
Bison chapter from the optional text.
- Additionally or alternatively, you may read sections
1, 3, 4, 5 and 6 of the Bison Manual
Mailbag
- The grammar file uses '{' and such as terminal symbols,
instead of names like LCURLY. Is that going to cause a problem?
'{' is just a small integer.
- Yes it does, no it does not cause a problem.
- What element types can be used in arrays and maps? Can I have an
array of arrays? A map of maps?
- For VGo, legal map index types are: int, string. Element types
also include float64 and structs.
Array of arrays and map of maps are awesome but not in VGo.
Note that structs can have arrays or maps as member variables.
- What about no-op statements like 2+2?
- Go and VGo do not allow no-op statements like 2+2. You have to use
the value somehow, like by writing it out or assigning it to a variable.
- The grammar you gave us has many symbols that have not been mentioned.
Should we support them, or not? If we don't
have to support them does that mean we don't have to include all the
grammar rules that use them?
- Feel free to ask about specifics.
The supplied grammar is for the whole language not our subset. You
would need to delete from it en masse to get down to our subset.
While that might be helpful from a code-management perspective,
it would also leave you saying a more vague "parse error" message
for many legal Go constructs for which a more helpful message is
"this Go feature is not supported by VGo".
- How about a tool that would generate #define numbers for grammar rules
automatically from our .y files?
- I wrote a cheap hack version 0
of such a tool awhile back. I have not tested it on go.y, it might be buggy.
- Will we get marked off for any reduce/reduce conflicts we have?
- Yes you will lose points if you turn in a HW#2 with reduce/reduce
conflicts.
- How are we supposed to integrate the token names we created in the
lexer with those token names in the Bison .y file?
- Any which way you can. Probably, you
either rename yours to use their names, or rename theirs to
use your names.
- what action should be taken in the case of epsilon statements
- HW#2 spec says to use $$=NULL. I could also imagine using
$$=alctree(EPSILON, 0) to build an explicit epsilon leaf,
for people who don't like to have to check for NULL everywhere.
- Will I be setting myself up for failure if I attempt to write
my own grammar from scratch?
- Go right ahead and ignore the provided grammar if you want; feel free to
instead derive your grammar from the reference manual.
Midterm Exam Date Discussion
We will need to have a midterm on Oct 17.
The YACC Value Stack
- YACC's parse stack contains only "states"
- YACC maintains a parallel set of values
- $ is used in semantic actions to name elements on the value stack
- $$ denotes the value associated with the LHS (nonterminal) symbol
- $n denotes the value associated with RHS symbol at position n.
- Value stack typically used to construct the parse tree
- Typical rule with semantic action: A : b C d { $$ = tree(R,3,$1,$2,$3); }
YACC Value Stack's Element Type: YYSTYPE
- The default value stack is an array of integers
- The value stack can hold arbitrary values in an array of unions
- The union type is declared with %union and is named YYSTYPE
lecture #12 began here
Mailbag
- During my "make" the linker complains about redefinition of yyparse()
and missing main(). What's going on?
- If your main is in vgo.c, beware renaming go.y as vgo.y -- the "make"
program has default rules that assume if a .c file has the same name
as a .y file, it is supposed to build the .c from the .y by running
yacc and renaming the foo.tab.c as foo.c!
- My vgo parser always dies on the first LBODY, what gives?
- Wow, this opened an awesome can of worms! go.y as delivered
by the go 1.2.2 compiler used two different codes for '{' in
the grammar! In their lexical analyzer, which we are not using,
they wrote:
* to implement rule that disallows
* if T{1}[0] { ... }
* but allows
* if (T{1}[0]) { ... }
* the block bodies for if/for/switch/select
* begin with an LBODY token, not '{'.
*
* when we see the keyword, the next
* non-parenthesized '{' becomes an LBODY.
* loophack is normally 0.
* a keyword makes it go up to 1.
* parens push loophack onto a stack and go back to 0.
* a '{' with loophack == 1 becomes LBODY and disables loophack.
We will have to devise a strategy to deal with this.
- "Just for fun" I changed all LBODY in go.y into '{' to see the fuss.
- result was: 2 shift-reduce conflicts. Presumably these are not the kind
of shift-reduce conflicts I am used to ignoring.
- I looked at the conflicts details using
bison -v, which
writes a *.output file
- Deleting a couple of production rules under non-terminal pexpr_no_paren
would "fix" the problem...
- One of the conflicting rules was actually already an error
("cannot parenthesize type in compusite literal")
- The other one might be for struct initializers. We can live without those
in VGo.
- Summary: go.y was updated, it is recommended that you change all LBODY to
'{' and delete a couple grammar production rules.
- What is
%prec NotParen about?
- Great question. %prec TERM directs Bison to apply the
current grammar rule with the precedence of TERM. In go.y, three
fake terminal symbols are introduced as their secret to avoid
shift/reduce conflicts.
Note that neither %prec nor TERM are symbols on the righthand side of
whatever production rule is being given -- if there aren't any other
symbols then that precedence is being applied to an epsilon rule.
%prec is used to apply some precedence rules specified via %left,
%right etc. to production rules in the Bison grammar where there is
not a symbol that can be declared as %left or %right. %left and
%right are in turn, Bison's way of tie-breaking ambiguous grammar
rules that would otherwise generate shift/reduce or reduce/reduce
conflicts.
- I am working on the tree but I am confused as to how to approach it. For
example package has the following rule:
package: LPACKAGE sym ';'
The tree struct shown on the hw2 assignment sheet has kids which
are of type struct tree and a leaf which is of struct token. Since package
has two tokens the LPACKAGE and ';' how should I approach saving this
to the tree struct. Should everything be saved under kids? With how I have
my %union right now, LPACKAGE and ';' are tokens and sym is struct tree.
- The example in HW#2, which you are not required to follow, illustrates
one possible way to incorporate terminal symbols as leaves. If you follow
it, separate from your struc token for each leaf you allocate a struct tree,
with 0 children, whose prodrule is the token's terminal symbol #, and for
a treenode with 0 children and a terminal symbol as a prodrule, the code that
goes back through the tree afterwards would know to not visit the children
array, but instead look at the leaf field for a token.
To do all this with your current %union with pointer to struct token on the
tree for terminal symbols, every time you are about to insert a tree node
with terminal symbols, you would allocate a leaf node to hold the token *.
So your rule for a package would allocate three tree nodes total, one for
the parent and two for the two terminal symbols being placed into leaves.
There are other ways that one can get it done, but this would work.
Getting Lex and Yacc to talk
- YACC uses a global variable named
yylval, of type YYSTYPE,
to receive lexical information from the scanner.
- Whatever is in this variable
yylval gets copied onto the
top of the value stack each time yylex() returns to the parser
Options:
- Declare that struct token may appear in the %union.
In that case the value stack is a mixture of struct node
and struct token. You still have to have a mechanism for
how do tokens get wired into your tree. Are all children
of type union YYSTYPE, and you use the prodrule R
to tell which are which?
- For each terminal symbol, allocate a "leaf" tree node with 0 children
and point its "leaf" field at your struct token. 0 children implies
"don't use the kids field" and "a non-null leaf might be present"
- declare a tree type that allows tokens to include
their lexical information directly in the tree nodes, perhaps tree nodes
contain a union that provides EITHER an array of kids OR a struct token.
If you have more than one %union type possible, be prepared to see type
conflicts and to declare the types of all your nonterminals.
Getting all this straight takes some time; you can plan on it. Your best
bet is to draw pictures of how you want the trees to look, and then make the
code match the pictures. Given pictures, I can help you make the code do
what the pictures say. No pictures == "Dr. J will ask to see your
pictures and not be able to help if you can't describe your trees."
Declaring value stack types for terminal and nonterminal symbols
Unless you are going to use the default (integer) value stack, you will
have to declare the types of the elements on the value stack. Actually,
you do this by declaring which
union member is to be used for each terminal and nonterminal in the
grammar.
Example: in the cocogram.y that I gave you we could add a %union declaration
with a union member named treenode:
%union {
nodeptr treenode;
}
This will produce a compile error if you haven't declared a nodeptr type
using a typedef, but that is another story. To declare that a nonterminal
uses this union member, write something like:
%type < treenode > function_definition
Terminal symbols use %token to perform the corresponding declaration.
If you had a second %union member (say struct token *tokenptr) you
might write:
%token < tokenptr > SEMICOL
Mailbag
- My compiler is complaining about strdup being missing. What up?
- It turns out -std=c99 removes strdup() because it is not part of that
standard. Possibly solutions include: not using -std=c99 when compiling
files that call strdup(), or writing/providing your own strdup().
- When I compile my .y file, bison complains spitting out a bunch of
warnings about useless nonterminals and rules. how much attention
should I pay to this?
- "Useless" warnings sound innocuous, but they mean what they say.
You probably have something wrong that will have to be fixed.
Everything but shift/reduce conflicts is potentially serious, until
you determine otherwise. If you can't figure out what some Bison error
is after giving it the reasonable college try, send it to me by e-mail
or schedule an appointment. If I am not available or you are remote,
we may schedule a Zoom meeting. You might have to learn some Zoom.
I might have to setup a camera on my many machines, and remember my
Zoom credentials.
- I've been trying to implement implicit concatenation in the grammar
and I'm getting reduce/reduce errors. Do you have any tips for
implementing implicit concatenation? Should I make specific rules
for concatenating strings and lists and stop trying to integrate
it into my expression syntax?
- If you can't get implicit concatenation working, you might resort
to explicit concatenation via (perhaps) the + operator. Tips to avoid
reduce/reduce errors include: avoid epsilon rules. MERGE rules that
look like the same thing (in Ada, functions and arrays both used the
same syntax! sad!). Incidentally, neither Unicon nor Java have
implicit concatenation, so in g0 it is a "can we do it?" question.
I would be happy to consult with folks on your grammarly endeavors
in office hours and additional appointments.
- It seems after HW#2 we will have to implement a hash table.
If this is the case, what would be a reasonable size (# buckets) of
the table? n=20?
- Fixed-size tables should use a prime. For the size of inputs
I will ever manage in this class, probably a prime less than 100 would do.
How about n=41 ?
Conflicts in Shift-Reduce Parsing
"Conflicts" occur when an ambiguity in the grammar creates a situation
where the parser does not know which step to perform at a given point
during parsing. There are two kinds of conflicts that occur.
- shift-reduce
- a shift reduce conflict occurs when the grammar indicates that
different successful parses might occur with either a shift or a reduce
at a given point during parsing. The vast majority of situations where
this conflict occurs can be correctly resolved by shifting.
- reduce-reduce
- a reduce reduce conflict occurs when the parser has two or more
handles at the same time on the top of the stack. Whatever choice
the parser makes is just as likely to be wrong as not. In this case
it is usually best to rewrite the grammar to eliminate the conflict,
possibly by factoring.
Example shift reduce conflict:
S->if E then S
S->if E then S else S
In many languages two nested "if" statements produce a situation where
an "else" clause could legally belong to either "if". The usual rule
(to shift) attaches the else to the nearest (i.e. inner) if statement.
Example reduce reduce conflict:
(1) S -> id LP plist RP
(2) S -> E GETS E
(3) plist -> plist, p
(4) plist -> p
(5) p -> id
(6) E -> id LP elist RP
(7) E -> id
(8) elist -> elist, E
(9) elist -> E
By the point the stack holds ...id LP id
the parser will not know which rule to use to reduce the id: (5) or (7).
lecture #13 began here
Mailbag
- Can I put a string label in my tree nodes, saying what nonterminal it is?
- You could have a string, you could have an integer; you could have both
for all I care. Actually, both is a pretty good idea. The string makes
for human-readable tree output, while the integer is superior for writing
tree traversals and doing different behavior depending on what kind of
tree node you are dealing with.
- I haven't been able to find a way to edit the yylex() that's generated
(in order to semi-colon insertion).
- You aren't supposed to do this manually, you are supposed to do it
automatically with a computer program whenever you (re)make it. Per
a previous class discussion, there are several UNIX tools that could
do this, including the option of writing a C program or a flex program
to do it. But one of the simplest options may be something like the
following in your makefile:
lex.yy.c: lex.l
flex lex.l
sed -i 's/yylex/myyylex/g' lex.yy.c
- In the example
A : b C d {$$ = tree(R,3,$1,$2,$3);} ;
Suppose C is a terminal and b and d are non-terminals. Then $2 will be
OK, but when will I be able to get the data that $1 and $3 need to
be set to?
- Bison parsers are bottom up. You don't reduce this grammar rule
or execute this code until sometime after the handle
b C d
has already been parsed, and in that process the production rules for
b and d have already executed, just as surely as the shift of C which
placed whatever yylval held at that time onto the value stack in $2.
If the rules for b and d had actions that said {$$=...} at that point
in the past, then $1 and $3 now will be holding what was assigned to $$
back in those rules' semantic actions.
- In the example
A : b C d {$$ = tree(R,3,$1,$2,$3);} ;
to what doth R refer?
- R was intended to be an integer code that allows you to tell, when
walking through the tree later on, what production rule built that node.
I would typically do a code for each nonterminal, gapped large enough
that R can be (nonterminal+rule#forthatnonterminal). Suppose this was
the first of three production rules that build an A. The integer might
be (__A__ + 1) to denote the first A rule.
- I'm considering having some sort of stack that keeps track of the parent
you should currently be attaching children to.
- You can do anything you want, but bison's value stack is that stack and
and at each level you should allocate a node for $$ and attach all of its
children. That is it.
- Should we be defining our own integer codes for token types or just use
the ones in our *.tab.h file from HW#1?
- You can't define your own codes, you have to use the codes that bison
generates. You'll have to modify your lexer to use bison's integers, or your
flex and bison will not work together.
- Are yylval's types defined in the %union?
- Yes, yylval is of type YYSTYPE, the type bison generates for the %union.
- What is the actual value of a $n variable?
- Before your bison grammar's semantic action code triggers, $1, $2, ...
etc. will be holding either (A) whatever you put in yylval if the
corresponding symbol is a terminal, or (B) whatever you put in $$
for its rule if the symbol is a non-terminal.
- Do we have to implicitly concatenate substrings?
- Yes, substrings are strings.
- Since we're not doing initializers, what is required of a for-statement?
- You don't have to do a declaration of a variable in a for initializer.
Saying
for(int i=1; ...) was a C++ thing.
Further Discussion of Reduce Reduce and Shift Reduce Conflicts
The following grammar, based loosely on our expression grammar from
last time, illustrates a reduce reduce conflict, and how you have to
exercise care when using epsilon productions. Epsilon productions
were helpful for some of the grammar rewriting methods, such as removing
left recursion, but used indiscriminately, they can cause much trouble.
T : F | F T2 ;
T2 : p F T2 | ;
F : l T r | v ;
The reduce-reduce conflict occurs after you have seen an F. If the next
symbol is a p there is no question of what to do, but if the next symbol
is the end of file, do you reduce by rule #1 or #4 ?
Back to Bison Conflicts and Ambiguity
A slightly different grammar is needed to demonstrate a shift-reduce conflict:
T : F g;
T : F T2 g;
T2 : t F T2 ;
T2 : ;
F : l T r ;
F : v ;
This grammar is not much different than before, and has the same problem,
but the surrounding context (the "calling environments") of F cause the
grammar to have a shift-reduce instead of reduce-reduce. Once again,
the trouble is after you have seen an F and dwells on the question of
whether to reduce the epsilon production, or instead to shift, upon
seeing a token g.
The .output file generated by "bison -v" explains these conflicts in
considerable detail. Part of what you need to interpret them are the
concepts of "items" and "sets of items" discussed below.
YACC precedence and associativity declarations
YACC headers can specify precedence and associativity rules for otherwise
heavily ambiguous grammars. Precedence is determined by increasing order
of these declarations. Example:
%right ASSIGN
%left PLUS MINUS
%left TIMES DIVIDE
%right POWER
%%
expr: expr ASSIGN expr
| expr PLUS expr
| expr MINUS expr
| expr TIMES expr
| expr DIVIDE expr
| expr POWER expr
| IDENT
;
YACC error handling and recovery
- Use special predefined token
error where errors expected
- On an error, the parser pops states until it enters one that has an
action on the error token.
- For example: statement: error ';' ;
- The parser must see 3 good tokens before it decides it has recovered.
- yyerrok tells parser to skip the 3 token recovery rule
- yyclearin throws away the current (error-causing?) token
- yyerror(s) is called when a syntax error occurs (s is the error message)
lecture #14 began here
Mailbag
- I have spent 30 hours and am not close to finishing adding the
hundreds of grammar rules and tree construction semantic actions
required for HW#2!
- As a professional programmer, you should invest time to master
a powerful programmer's editor with a key-memorizing macro facility
that can let you insert semantic actions (for example)
very rapidly. If you've been typing them in by hand, ouch!
Paste the right thing 500 times and then just tweak. Or paste all
the constructors with the same number of children in batches, so
you have less to tweak because you already pasted in the right number
of kids.
- Do I need to add
%type <treeptr> nonterm for every
non-terminal symbol in the grammar in order to have everything work
- yes. If you are lucky, the %type's are in there in a comment, and all
you have to do is uncomment them and add the
<treeptr>
(or whatever) part.
- Are we supporting (syntactically) nested classes/structs?
- no
- What do I do with epsilon rules? Empty tree nodes?
- I previously said to use either $$ = NULL or
$$ = alctree(RULE, 0).
Whether the latter is preferable depends on what will make your
tree traversals easier later on, in HW#3, and maybe whether the
encoding of an empty leaf with RULE would help you in reading the
tree and knowing what to do with it. Saying $$=NULL
implies you will have to check children to see if they are NULL
before you try to visit them. Never setting $$ to NULL means you
can "blindly" traverse child pointers if a parent has nkids > 0.
-
All of the leaves in the tree structure are/can be made of lex tokens. To
that point then, what are the non-leaves supposed to be? I think I may have
over thought this point so I am not quite sure.
- Non-leaves (i.e. internal nodes) correspond to non-terminal symbols,
built from particular production rules.
- For the structure of the tree, HW#2 provides a possible "setup".
struct tree {
int prodrule;
int nkids;
struct tree *kids[9];
struct token *leaf;
}
While I understand nkids (number of kids this node has), *kids[9] (a pointer
array to up to 9 kids), and leaf (the lex token), what exactly is the
prodrule? I am fairly certain that this is the production rule, but I am
not exactly sure what it associates with.
- The prodrule integer encodes what production rule was used
to build this node, which includes (of course) what non-terminal it represents,
and what syntactic role its children played. By the way, *kids[9] is
an array of 9 pointers to kids, not a pointer to an array of nine kids.
-
What exactly is in $1 or $2 or ... when I am at a reduction building a
tree node in $$ for some non-terminal?
-
- If the rule's first righthandside symbol is a terminal, what is in
$1 is whatever you assigned to yylval when that terminal was matched in yylex.
- If the rule's first righthandside symbol is a non-terminal, what
is in $1 is whatever you assigned to $$ when that non-terminal was reduced.
-
I was wondering if it is ok to have a linked list of syntax trees, where the
syntax tree for the current source file be inserted into a linked list (of
syntax trees), then at the end of main(), after generating syntax trees for
each file in command line argument, walk through the linked list and print
out each syntax tree.
-
What is expected is that for each file, you build the tree,
return to main(), print it out, and then move on to the next filename. But
building a linked list of trees and looping again over that to print things
out would be fine. The main thing between each file on the command line is to
clear out the type name table; each file is being compiled independently of
whatever came before them during that compilation process.
Improving YACC's Error Reporting
yyerror(s) overrides the default error message, which usually just says either
"syntax error" or "parse error", or "stack overflow".
You can easily add information in your own yyerror() function, for example
GCC emits messages that look like:
goof.c:1: parse error before '}' token
using a yyerror function that looks like
void yyerror(char *s)
{
fprintf(stderr, "%s:%d: %s before '%s' token\n",
yyfilename, yylineno, s, yytext);
}
You could instead, use the error recovery mechanism to produce better messages.
For example
lbrace : LBRACE | { error_code=MISSING_LBRACE; } error ;
Where LBRACE is an expected token {
This uses a global variable error_code to pass parse information to yyerror().
Improving YACC's Error Reporting, cont'd
Another related option is to call yyerror() explicitly with a better message
string, and tell the parser to recover explicitly:
package_declaration: PACKAGE_TK error
{ yyerror("Missing name"); yyerrok; } ;
But, using error recovery to perform better error reporting runs against
conventional wisdom that you should use error tokens very sparingly.
What information from the parser determined we had an error in the first
place? Can we use that information to produce a better error message?
LR Syntax Error Messages: Advanced Methods
The pieces of information that YACC/Bison use to determine that there
is an error in the first place are the parse state (yystate) and the
current input token (yychar). These are exactly the pieces of information
one might use to produce better diagnostic error messages without
relying on the error recovery mechanism and mucking up the grammar
with a lot of extra production rules that feature the error token.
Even just the parse state is enough to do pretty good error messages.
yystate is not part of YACC's public interface, though, so you may
have to play some tricks to pass it as a parameter into yyerror() from
yyparse(). Say, for example:
#define yyerror(s) __yyerror(s,yystate)
Inside __yyerror(msg, yystate) you can use a switch statement or a global
array to associate messages with specific parse states. But, figuring
out which parse state means which syntax error message would be by trial
and error.
A tool called Merr is available that let's you generate this yyerror
function from examples: you supply the sample syntax errors and messages,
and Merr figures out which parse state integer goes with which message.
Merr also uses the yychar (current input token) to refine the diagnostics
in the event that two of your example errors occur on the same parse state.
See the Merr web page.
Recursive Descent Parsing
Perhaps the simplest parsing method, for a large subset of context free
grammars, is called recursive descent. It is simple because the algorithm
closely follows the production rules of nonterminal symbols.
- Write 1 procedure per nonterminal rule
- Within each procedure, a) match terminals at appropriate positions,
and b) call procedures for non-terminals.
- Pitfalls:
- left recursion is FATAL
- must distinguish between several
production rules, or potentially, one has to
try all of them via backtracking.
lecture #15 began here
Mailbag
- I have mysterious syntax errors, what do I do?
-
- make sure that your lexer is including the .tab.h that corresponds to
your bison file
- #define YYDEBUG and set yydebug=1 and read the glorious output, especially
the last couple shifts or reduces before the syntax error.
- implement semi-colon insertion
- I can't fix some of the shift/reduce conflicts, what do I do?
- Nothing. You do not have to fix shift/reduce conflicts.
- I can't fix some of the reduce/reduce conflicts, what do I do?
- These generally reflect a real bug and will cost you a few points on HW,
but they mighty or might not cost you more points on test cases.
It is only
a deal breaker and has to be fixed if it prevents us from parsing
correctly and building our tree. Sometimes epsilon
rules can be removed successfully by adding grammar rules in a
parent non-terminal that omit an epsilon-deriving child, and then
modifying the child to not derive epsilon. This might or might not
help reduce your number of reduce/reduce conflicts.
- With the default error handling, I am getting an error on the last line of
the file: syntax error before '' token. It looks like an EOF error, but I
cannot figure out how to fix it, as when I add an <<EOF>> rule to my lexer,
it just hangs there, and still produces this error.
- Error on EOF might be because the grammar expects one more semi-colon,
maybe your EOF regex should return one the first time it hits in each
file. By the way, I usually don't have to write a <<EOF>>
regex, yylex() returns the value on EOF that yyparse() expects.
If you enable YYDEBUG and turn on yydebug you will get a detailed
explanation of the parse and where it is failing when you run your
parser, which may help you. Feel free to schedule a Zoom session.
Recursive Descent Parsing Example #1
E -> E + T
E -> T
T -> T * F
T -> F
F -> ( E )
F -> ident
Consider the grammar we gave above. There will be functions for
E, T, and F. The function for F() is the "easiest" in some sense: based
on a single token it can decide which production rule to use. The
parsing functions return 0 (failed to parse) if the nonterminal in
question cannot be derived from the tokens at the current point.
A nonzero return value of N would indicate success in parsing using
production rule #N.
int F()
{
int t = yylex();
if (t == IDENT) return 6;
else if (t == LP) {
if (E() && (yylex()==RP) return 5;
}
return 0;
}
Comment #1: if F() is in the middle of a larger parse of E() or T(), F()
may succeed, but the subsequent parsing may fail. The parse may have
to backtrack, which would mean we'd have to be able to put
tokens back for later parsing. Add a memory (say, a gigantic array or
link list for example) of already-parsed tokens
to the lexical analyzer, plus backtracking logic to E() or T() as needed.
The call to F() may get repeated following a different production rule
for a higher nonterminal.
Comment #2: in a real compiler we need more than "yes it parsed" or
"no it didn't": we need a parse tree if it succeeds, and we need a
useful error message if it didn't.
Question: for E() and T(), how do we know which production rule to try?
Option A: just blindly try each one in turn.
Option B: look at the first (current) token, only try those rules that
start with that token (1 character lookahead). If you are lucky, that
one character will uniquely select a production rule. If that is always
true through the whole grammar, no backtracking is needed.
Question: how do we know which rules start with whatever token we are
looking at? Can anyone suggest a solution, or are we stuck?
Below is an industrious start of an implementation of the
corresponding recursive descent parser for non-terminal T.
Now is student-author time, what is our next step? What is wrong with
this picture?
int T()
{ // save where the current token is
if (T() && (yylex()==ASTERISK) && F()) return 3;
// restore the current input pointer to the saved location
if (F()) return 4;
return 0;
}
Removing Left Recursion
E -> E + T | T
T -> T * F | F
F -> ( E ) | ident
We can remove the left recursion by introducing new nonterminals
and new production rules.
E -> T E'
E' -> + T E' | ε
T -> F T'
T' -> * F T' | ε
F -> ( E ) | ident
Getting rid of such immediate left recursion is not enough, one must
get rid of indirect left recursion, where two or more nonterminals are
mutually left-recursive.
One can rewrite any CFG to remove left recursion (Algorithm 4.19).
for i := 1 to n do
for j := 1 to i-1 do begin
replace each Ai -> Aj γ with productions
Ai -> δ1γ | δ2γ | ... | δkγ, where
Aj -> δ1 | δ2 | ... | δk are all current Aj-productions
end
eliminate immediate left recursion
Where We Are
- We started in on recursive descent parsing by observing that for some
grammar rules, we could just write the code easy peasy by matching
the first token and then calling nonterminal functions.
- Then we hit a wall, because the other nonterminals were left recursive,
we had to solve the infinite recursion problem, which is detailed in your
dragon book.
- If we ever clear the left recursion hurdle, THEN we can worry about the
backtracking problem: if we try to parse rule 1, and get into it a ways, and
find that it doesn't work, we have to "undo" all our parsing (and possibly
lexing) back to the starting point in order to try subsequent grammar rules
for a given nonterminal.
Removing Left Recursion, part 2
Left recursion can be broken into three cases
case 1: trivial
A : A α | β
The recursion must always terminate by A finally deriving β so you
can rewrite it to the equivalent
A : β A'
A' : α A' | ε
Example:
E : E op T | T
can be rewritten
E : T E'
E' : op T E' | ε
case 2: non-trivial, but immediate
In the more general case, there may be multiple recursive productions
and/or multiple non-recursive productions.
A : A α1 | A α2 | ... | β1 | β2
As in the trivial case, you get rid of left-recursing A and introduce an A'
A : β1 A' | β2 A' | ...
A' : α1 A' | α2 A' | ... | ε
case 3: mutual recursion
- Order the nonterminals in some order 1 to N.
- Rewrite production rules to eliminate all
nonterminals in leftmost positions that refer to a "previous" nonterminal.
When finished, all productions' right hand symbols start with a terminal
or a nonterminal that is numbered equal or higher than the nonterminal
no the left hand side.
- Eliminate the direct left recusion as per cases 1-2.
Left Recursion Versus Right Recursion: When does it Matter?
A student came to me once with what they described as an operator precedence
problem where 5-4+3 was computing the wrong value (-2 instead of 4). What
it really was, was an associativity problem due to the grammar:
E : T + E | T - E | T
The problem here is that right recursion is forcing right associativity, but
normal arithmetic requires left associativity. Several solutions are:
(a) rewrite the grammar to be left recursive, or (b) rewrite the grammar
with more nonterminals to force the correct precedence/associativity,
or (c) if using YACC or Bison, there are "cheat codes" we will discuss later
to allow it to be majorly ambiguous and specify associativity separately
(look for %left and %right in YACC manuals).
Recursive Descent Parsing Example #2
The grammar
S -> A B C
A -> a A
A -> ε
B -> b
C -> c
maps to pseudocode like the following. (:= is an assignment operator)
procedure S()
if A() & B() & C() then succeed # matched S, we win
end
procedure A()
if yychar == a then { # use production 2
yychar := scan()
return A()
}
else
succeed # production rule 3, match ε
end
procedure B()
if yychar == b then {
yychar := scan()
succeed
}
else fail
end
procedure C()
if yychar == c then {
yychar := scan()
succeed
}
else fail
end
Backtracking?
Could your current token begin more than one of your possible production rules?
Try all of them, remember and reset state for each try.
S -> cAd
A -> ab
A -> a
Left factoring can often solve such problems:
S -> cAd
A -> a A'
A'-> b
A'-> (ε)
One can also perform left factoring to reduce or
eliminate the lookahead or backtracking needed to tell which production rule
to use. If the end result has no lookahead or backtracking needed, the
resulting CFG can be solved by a "predictive parser" and coded easily in a
conventional language. If backtracking is needed, a recursive descent
parser takes more work to implement, but is still feasible.
As a more concrete example:
S -> if E then S
S -> if E then S1 else S2
can be factored to:
S -> if E then S S'
S'-> else S2 | ε
lecture #16 began here
Mailbag
- I got my trees printing for the tests you gave us for HW#1, am I done?
- You are responsible for thoroughly testing your code, including constructing
test cases. You might want to specifically make sure that each tree-constructor
code fragment that you write gets used by at least one test case (this is called
statement-level coverage). Having said that constructing tests is on you,
I went and looked at what was lying around handy, and came up with the
go 1.2.2 test suite. Can we use it as is? Almost every
test will use features in Go but not in VGo (things like :=), so we have to translate
them into VGo to use them. We can either leave this all up to you, or we can
collaborate on it, your choice.
- I get syntax errors on
else. What up?
- By running code samples on the real Go compiler ("go build foo.go") one
can tell whether a given test case was legal Go or not. It turns out, if you
do an else, it has to be on the same line as the closing curly brace that
precedes it. I have adjusted the VGo Specification
accordingly.
Some More Parsing Theory
Automatic techniques for constructing parsers start with computing some
basic functions for symbols in the grammar. These functions are useful
in understanding both recursive descent and bottom-up LR parsers.
First(α)
First(α) is the set of terminals that begin strings derived from α,
which can include ε.
- First(X) starts with the empty set.
- if X is a terminal, First(X) is {X}.
- if X -> ε is a production, add ε to First(X).
- if X is a non-terminal and X -> Y1 Y2 ... Yk is a production,
add First(Y1) to First(X).
for (i = 1; if Yi can derive ε; i++)
add First(Yi+1) to First(X)
First(a) examples
by the way, this stuff is all in section 4.3 in your text.
Last time we looked at an example with E, T, and F, and + and *.
The first-set computation was not too exciting and we need more
examples.
stmt : if-stmt | OTHER
if-stmt: IF LP expr RP stmt else-part
else-part: ELSE stmt | ε
expr: IDENT | INTLIT
What are the First() sets of each nonterminal?
Follow(A)
(The helper function that goes along with First(X))
Follow(A) for nonterminal A is the set of terminals that can appear
immediately to the right of A in some sentential form S -> aAxB...
To compute Follow, apply these rules to all nonterminals in the grammar:
- Add $ to Follow(S)
- if A -> aBβ then add First(b) - ε to Follow(B)
- if A -> aB or A -> aBβ where ε is in First(β), then add
Follow(A) to Follow(B).
Follow() Example
For the grammar:
stmt : if-stmt | OTHER
if-stmt: IF LP expr RP stmt else-part
else-part: ELSE stmt | ε
expr: IDENT | INTLIT
It can get pretty muddy on the Follow() function, for even this simple grammar.
It helps if you follow the algorithm, instead of just "eyeballing it".
For all non-terminals X in the grammar do
1. if X is the start symbol, add $ to Follow(X)
2. if N -> αXβ then add First(β) - ε to Follow(X)
3. if N -> αX or N -> αXβ where ε is in
First(β) then add Follow(N) to Follow(X)
Since the algorithm depends on First(), what are First sets again?
First(stmt) = {IF, OTHER}
First(if-stmt) = {IF}
First(else-part) = {ELSE, ε}
First(expr) = {IDENT, INTLIT}
Because each non-terminal has three steps, and our toy grammar has
4 non-terminals, there are 12 steps.
When you just apply these twelve steps, brute force, it is clear
that the statement of what to do to compute them was not an algorithm,
it was only a declarative specification, and there is an ordering needed
in order to compute the result.
1. stmt is the start symbol, add $ to Follow(stmt)
2. if N -> α stmt β then add First(β) - ε to Follow(stmt)
---- add First(else-part)-ε to Follow(stmt)
3. if N -> α stmt or N -> α stmt β where ε
is in First(β) then add Follow(N) to Follow(stmt)
---- add Follow(else-part) to Follow(stmt)
4. if-stmt is not the start symbol (noop)
5. if N -> αif-stmtβ then add First(β) - ε to Follow(if-stmt)
---- n/a
6. if N -> αif-stmt or N -> αif-stmtβ where ε is in
First(β) then add Follow(N) to Follow(if-stmt)
---- add Follow(stmt) to Follow(if-stmt)
7. else-part is not the start symbol (noop)
8. if N -> αelse-partβ then add First(β) - ε to Follow(else-part)
---- n/a
9. if N -> αelse-part or N -> αelse-partβ where ε is in
First(β) then add Follow(N) to Follow(else-part)
--- add Follow(if-stmt) to Follow(else-part)
10. expr is not the start symbol (noop)
11. if N -> αexprβ then add First(β) - ε to Follow(expr)
---- add RP to Follow(expr)
12. if N -> αexpr or N -> αexprβ where ε is in
First(β) then add Follow(N) to Follow(expr)
---- n/a
What is the dependency graph? Does it have any cycles? If it has cycles,
you will have to iterate to a fixed point.
Follow(stmt) depends on Follow(else-part)
Follow(if-stmt) depends on Follow(stmt)
Follow(else-part) depends on Follow(if-stmt)
If I read this right, there is a 3-way mutual recursion cycle.
Can we First/Follow Anything Else
Like preferably, a real-world grammar example? Please remember that real
world grammars for languages like ANSI C are around 400+ production rules,
so in-class examples will by necessity be toys. If I pick a random* (*LOL)
YACC grammar, can we First/Follow any of its non-terminals?
LR vs. LL vs. LR(0) vs. LR(1) vs. LALR(1)
The first char ("L") means input tokens are read from the left
(left to right). The second char ("R" or "L") means parsing
finds the rightmost, or leftmost, derivation. Relevant
if there is ambiguity in the grammar. (0) or (1) or (k) after
the main lettering indicates how many lookahead characters are
used. (0) means you only look at the parse stack, (1) means you
use the current token in deciding what to do, shift or reduce.
(k) means you look at the next k tokens before deciding what
to do at the current position.
lecture #17 began here
Mailbag
- VGo spec says no colons, but then the map constructor uses colons
- Good catch. VGo has maps but not "map literals". You should have
a colon token in your lexer, even though colons are a Go-not-VGo thing.
Here's a Pepsi Challenge question: is it right and good to just die if
you see a colon, or should you return the colon as a token, and in the
syntax check, distinguish between legal uses of Go that VGo doesn't
handle, versus crazy non-Go uses of a colon operator.
- ...
LR Parsers
LR denotes a class of bottom up parsers that is capable of handling virtually
all programming language constructs. LR is efficient; it runs in linear time
with no backtracking needed. The class of languages handled by LR is a proper
superset of the class of languages handled by top down "predictive parsers".
LR parsing detects an error as soon as it is possible to do so. Generally
building an LR parser is too big and complicated a job to do by hand, we use
tools to generate LR parsers.
The LR parsing algorithm is given below.
ip = first symbol of input
repeat {
s = state on top of parse stack
a = *ip
case action[s,a] of {
SHIFT s': { push(a); push(s') }
REDUCE A->β: {
pop 2*|β| symbols; s' = new state on top
push A
push goto(s', A)
}
ACCEPT: return 0 /* success */
ERROR: { error("syntax error", s, a); halt }
}
}
Constructing SLR Parsing Tables:
Definition: An LR(0) item of a grammar G is a production
of G with a dot at some position of the RHS.
Example: The production A->aAb gives the items:
A -> . a A b
A -> a . A b
A -> a A . b
A -> a A b .
Note: A production A-> ε generates
only one item:
A -> .
Intuition: an item A-> α . β denotes:
- α - we have already seen a string
derivable from α
- β - we hope to see a string derivable
from β
Functions on Sets of Items
Closure: if I is a set of items for a grammar G, then closure(I)
is the set of items constructed as follows:
- Every item in I is in closure(I).
- If A->α . Bβ
is in closure(I) and B->γ
is a production, then add B-> .γ
to closure(I).
These two rules are applied repeatedly until no new items can
be added.
Intuition: If A -> α . B β is in
closure(I) then we hope to see a string derivable from B in the
input. So if B-> γ is a production,
we should hope to see a string derivable from γ.
Hence, B->.γ is in closure(I).
Goto: if I is a set of items and X is a grammar symbol, then goto(I,X)
is defined to be:
goto(I,X) = closure({[A->αX.β] | [A->α.Xβ]
is in I})
Intuition:
- [A->α.Xβ]
is in I => we've seen a string derivable
from α; we hope to see a string derivable
from Xβ.
- Now suppose we see a string derivable from X
- Then, we should "goto" a state where we've seen
a string derivable from αX, and where
we hope to see a string derivable from β.
The item corresponding to this is [A->αX.β]
- Example: Consider the grammar
E -> E+T | T
T -> T*F | F
F -> (E) | id
Let I = {[E -> E . + T]} then:
goto(I,+) = closure({[E -> E+.T]})
= closure({[E -> E+.T], [T -> .T*F], [T -> .F]})
= closure({[E -> E+.T], [T -> .T*F], [T -> .F], [F-> .(E)], [F -> .id]})
= { [E -> E + .T],[T -> .T * F],[T -> .F],[F -> .(E)],[F -> .id]}
lecture #18 began here
Mailbag
- What-all do you see in this example?
It gives me errors on Vertex at the bottom.
-
- In general, if you have to debug something, simplify it to the simplest
possible version that produces the error. In this example, Vertex
would not be legal unless it was previous declared via a
type
declaration. Is that semantic analysis, or does it impact our parsing?
- In debugging VGo, using the Go compiler is a primary sanity check.
Running the Go compiler, it sees a syntax error on line 69 unrelated to
your question about Vertex. See rule #1.
I then boiled the Vertex part of your example down to the following, which
does compile with "go build":
package main
type Vertex struct {x, y float64}
func main() {
var m map[string]Vertex
m["Bell Labs"] = Vertex{ 40.68433, -74.39967 }
m["Google"] = Vertex{37.42202, -122.08408 }
}
As far as I can see, this parsed successfully with my reference VGo
lexer/parser, without Vertex posing any special problems. If my
interpretation of this is correct, the lexer returning LNAME for Vertex
is OK as a type name according to the go grammar, so the part of HW#2
that reads "Resolve matters regarding type names" is a no-op this semester
thanks to our reference grammar. It has kicked the can down the road on
the question of legal type names, deferring that to semantic analysis
(i.e. HW#3-4) where arguably, it belongs. If you get syntax errors, maybe
you have changed the grammar in some way that you may want to fix.
The Set of Sets of Items Construction
- Given a grammar G with start symbol S, construct the augmented
grammar by adding a special production S'->S where S' does
not appear in G.
- Algorithm for constructing the canonical collection of
sets of LR(0) items for an augmented grammar G':
begin
C := { closure({[S' -> .S]}) };
repeat
for each set of items I in C:
for each grammar symbol X:
if goto(I,X) != 0 and goto(I,X) is not in C then
add goto(I,X) to C;
until no new sets of items can be added to C;
return C;
end
Valid Items: an item A -> β
1. β 2
is valid for a viable prefix α
β 1 if
there is a derivation:
S' =>*rm αAω =>*rmα β1β 2ω
Suppose A -> β1.β 2 is valid for αβ1,
and αB1 is on the parsing
stack
- if β2 != ε,
we should shift
- if β2 = ε,
A -> β1 is the handle,
and we should reduce by this production
Note: two valid items may tell us to do different things for the
same viable prefix. Some of these conflicts can be resolved using
lookahead on the input string.
Constructing an SLR Parsing Table
- Given a grammar G, construct the augmented grammar by adding
the production S' -> S.
- Construct C = {I0, I1, … In},
the set of sets of LR(0) items for G'.
- State I is constructed from Ii, with parsing action
determined as follows:
- [A -> α.aB] is in
Ii, where a is a terminal; goto(Ii,a) = Ij
: set action[i,a] = "shift j"
- [A -> α.] is in
Ii : set action[i,a] to "reduce A -> x"
for all a ∈ FOLLOW(A), where A != S'
- [S' -> S .] is in Ii :
set action[i,$] to "accept"
- goto transitions constructed as follows: for all non-terminals:
if goto(Ii, A) = Ij, then goto[i,A] = j
- All entries not defined by (3) & (4) are made "error".
If there are any multiply defined entries, grammar is not SLR.
- Initial state S0 of parser: that constructed from
I0 or [S' -> S]
Constructing an SLR Parsing Table: Example
S -> aABe FIRST(S) = {a} FOLLOW(S) = {$}
A -> Abc FIRST{A} = {b} FOLLOW(A) = {b,d}
A -> b FIRST{B} = {d} FOLLOW{B} = {e}
B -> d FIRST{S'}= {a} FOLLOW{S'}= {$}
I0 = closure([S'->.S]
= closure([S'->.S],[S->.aABe])
goto(I0,S) = closure([S'->S.]) = I1
goto(I0,a) = closure([S->a.ABe])
= closure([S->a.ABe],[A->.Abc],[A->.b]) = I2
goto(I2,A) = closure([S->aA.Be],[A->A.bc])
= closure([S->aA.Be],[A->A.bc],[B->.d]) = I3
goto(I2,b) = closure([A->b.]) = I4
goto(I3,B) = closure([S->aAB.e]) = I5
goto(I3,b) = closure([A->Ab.c]) = I6
goto(I3,d) = closure([B->d.]) = I7
goto(I5,e) = closure([S->aABe.]) = I8
goto(I6,c) = closure([A->Abc.]) = I9
Fun with Parsing
Let's play a "new fun game"* and see what we can do with the following subset
of the C grammar:
| C grammar subset | First sets
|
|---|
ats : INT | TYPEDEF_NAME | s_u_spec ;
s_u_spec : s_u LC struct_decl_lst RC |
s_u IDENT LC struct_decl_lst RC |
s_u IDENT ;
s_u : STRUCT | UNION ;
struct_decl_lst : s_d | struct_decl_lst s_d ;
s_d : s_q_l SM |
s_q_l struct_declarator_lst SM ;
s_q_l : ats | ats s_q_l ;
struct_declarator_lst:
declarator |
struct_declarator_list CM declarator ;
declarator: IDENT |
declarator LB INTCONST RB ;
|
First(ats) = { INT, TYPEDEF_NAME, STRUCT, UNION }
First(s_u_spec) = { STRUCT, UNION }
First(s_u) = { STRUCT, UNION }
First(struct_decl_lst) = { INT, TYPEDEF_NAME, STRUCT, UNION }
First(s_d) = { INT, TYPEDEF_NAME, STRUCT, UNION }
First(s_q_l) = { INT, TYPEDEF_NAME, STRUCT, UNION}
First(struct_declarator_lst) = { IDENT }
First(declarator) = { IDENT }
|
Follow(ats) = { $, INT, TYPEDEF_NAME, STRUCT, UNION, IDENT, SM }
Follow(s_u_spec) = { $, INT, TYPEDEF_NAME, STRUCT, UNION, IDENT, SM }
Follow(s_u) = { LC, IDENT }
Follow(struct_decl_lst) = { RC, INT, TYPEDEF_NAME, STRUCT, UNION }
Follow(s_d) = { RC, INT, TYPEDEF_NAME, STRUCT, UNION }
Follow(s_q_l) = { IDENT, SM }
Follow(struct_declarator_lst) = { CM, SM }
Follow(declarator) = { LB , CM, SM }
Now, Canonical Sets of Items for this Grammar:
I0 = closure([S' -> . ats]) =
closure({[S' -> . ats], [ ats -> . INT ],
[ ats -> . TYPEDEF_NAME ], [ ats -> . s_u_spec ],
[ s_u_spec -> . s_u LC struct_decl_lst RC],
[ s_u_spec -> . s_u IDENT LC struct_decl_lst RC],
[ s_u_spec -> . s_u IDENT ],
[ s_u -> . STRUCT ],
[ s_u -> . UNION ]
})
goto(I0, ats) = closure({[S' -> ats .]}) = {[S' -> ats .]} = I1
goto(I0, INT) = closure({[ats -> INT .]}) = {[ats -> INT .]} = I2
goto(I0, TYPEDEF) = closure({[ats -> TYPEDEF_NAME .]}) = {[ats -> TYPEDEF_NAME .]} = I3
goto(I0, s_u_spec) = closure({[ats -> s_u_spec .]}) = {[ats -> s_u_spec .]} = I4
goto(I0, s_u) = closure({
[ s_u_spec -> s_u . LC struct_decl_lst RC],
[ s_u_spec -> s_u . IDENT LC struct_decl_lst RC],
[ s_u_spec -> s_u . IDENT ]}) = I5
goto(I0, STRUCT) = closure({[ s_u -> STRUCT .]}) = I6
goto(I0, UNION) = closure({[ s_u -> UNION .]}) = I7
goto(I5, LC) = closure({[ s_u_spec -> s_u LC . struct_decl_lst RC],
[ struct_decl_lst -> . s_d ],
[ struct_decl_lst -> . struct_decl_lst s_d ],
[ s_d -> . s_q_l SM],
[ s_d -> . s_q_l struct_declarator_lst SM],
[ s_q_l -> . ats ],
[ s_q_l -> . ats s_q_l ],
[ ats -> . INT ],
[ ats -> . TYPEDEF_NAME ],
[ ats -> . s_u_spec ],
})
* Arnold Schwartzenegger. Do you know the movie?
lecture #19 began here
Mailbag
-
What exactly gives the
shape of the tree? I know that it is formed from the rules defined in bison,
but I am having trouble visualizing it.
-
At each node of the tree, the shape (a.k.a. "fan-out", or # of children)
is defined by the # of symbols on the
righthand side of the production rule used to construct that node.
For go.y, the ~273 rules after we've deleted a lot of "hidden" things,
the distribution is about as follows:
| Size of RHS | # of Rules of that size
|
|---|
| 0 | 19
|
| 1 | 98
|
| 2 | 46
|
| 3 | 67
|
| 4 | 17
|
| 5 | 21
|
| 6 | 2
|
| 7 | 1
|
| 8 | 2
|
- I totally have an example where a shift-reduce conflict was a Real
Problem even though you said we could ignore shift-reduce conflicts!
- Ouch! When you showed me this in my office, you found that you could
fix it by simply changing a right recursion to a left recursion!
Very cool, we finally know why Bison warns of this kind of ambiguity
in the grammar: sometimes it is really a problem. I have taken the
liberty of reducing your example to just about its simplest form:
%%
Program: DeclarationList ProgramBody ;
ProgramBody: Function SEMICOLON ProgramBody | ;
Function: Declaration OPEN_PAREN CLOSE_PAREN ;
DeclarationList:Declaration SEMICOLON DeclarationList | ;
Declaration: INT IDENTIFIER ;
The corresponding input that dies on this is:
int x;
int main();
- How about a tool that would generate numbers
automatically from our grammar .y files? It should perhaps use negative
numbers (to avoid overlap/conflicts with Bison-generated numbers for
terminal symbols).
- We looked again to see if Bison had an option to generate that, but I
am not aware of one. Awhile back
I wrote a cheap hack version 0
of such a tool...feel free to adapt it or rewrite something similar.
Status of HW#2
- As of ~2pm I have received about 21 submissions, i.e. about 2/3rds
of the class has turned something in.
- The late fee on HW#2 is 8% per day.
- I may sometimes charge a lower late fee, depending on individual
circumstances.
- If you have not submitted HW#2 yet, you are not alone. If you are in
this boat, you are encouraged to continue to work on it, seek help from
me as needed, and turn HW#2 in when it is working.
We need to wrap up discussion of parsing and move lectures on to
semantic analysis. Read the corresponding chapters in your text.
On Trees
Trees are classic data structures.
- Trees have nodes and edges; they are
a special case of graphs.
- Tree edges are directional, with roles "parent"
and "child" attributed to the source and destination of the edge.
- A tree has the property that every node has zero or one parent.
- A node with no parents is called a root.
- A node with no children is called a leaf.
- A node that is neither a root nor a leaf is an "internal node".
- Trees have a size (total # of nodes), a height (maximum count
of nodes from root to a leaf),
and an "arity" (maximum number of children in any one node).
Parse trees are k-ary, where there is a
variable number of children bounded by a value k determined by the grammar.
You may wish to consult your old data structures book, or look at some books
from the library, to learn more about trees if you are not totally
comfortable with them.
#include <stdarg.h>
struct tree {
short label; /* what production rule this came from */
short nkids; /* how many children it really has */
struct tree *child[1]; /* array of children, size varies 0..k */
/* Such an array has to be the LAST
field of a struct, and "there can
be only ONE" for this to work. */
};
struct tree *alctree(int label, int nkids, ...)
{
int i;
va_list ap;
struct tree *ptr = malloc(sizeof(struct tree) +
(nkids-1)*sizeof(struct tree *));
if (ptr == NULL) {fprintf(stderr, "alctree out of memory\n"); exit(1); }
ptr->label = label;
ptr->nkids = nkids;
va_start(ap, nkids);
for(i=0; i < nkids; i++)
ptr->child[i] = va_arg(ap, struct tree *);
va_end(ap);
return ptr;
}
Having Trouble Debugging?
To save yourself on the semester project in this class, you should
learn gdb (or some other source level debugger) as well as you can.
Sometimes it can help you find your bug in seconds where you would have
spent hours without it. But only if you take the time to read the manual
and learn the debugger.
To work on segmentation faults: recompile all .c files with -g and run your
program inside gdb to the point of the segmentation fault. Type the gdb
"where" command. Print the values of variables on the line mentioned in the
debugger as the point of failure. If it is inside a C library function, use
the "up" command until you are back in your own code, and then print the
values of all variables mentioned on that line.
After gdb, the second tool I recommend strongly is valgrind. valgrind
catches some kinds of errors that gdb misses. It is a non-interactive
tool that runs your program and reports issues as they occur, with a big
report at the end.
Reading Tree Leaves
In order to work with your tree, you must be able to tell, preferably
trivially easily, which nodes are tree leaves and which are internal nodes,
and for the leaves, how to access the lexical attributes.
Options:
- encode in the parent what the types of children are
- encode in each child what its own type is (better)
How do you do option #2 here?
There are actually nonterminal symbols with 0 children (nonterminal with
a righthand side with 0 symbols) so you don't necessarily want to use
an nkids of 0 is your flag to say that you are a leaf.
Perhaps the best approach to all this is to unify the tokens and parse tree
nodes with something like the following, where perhaps an nkids value of -1
is treated as a flag that tells the reader to use
lexical information instead of pointers to children:
struct node {
int code; /* terminal or nonterminal symbol */
int nkids;
union {
struct token { ... } leaf; // or: struct token *leaf;
struct node *kids[9];
}u;
} ;
Tree Traversals
Besides a function to allocate trees, you need to write one or more recursive
functions to visit each node in the tree, either top to bottom (preorder),
or bottom to top (postorder). You might do many different traversals on the
tree in order to write a whole compiler: check types, generate machine-
independent intermediate code, analyze the code to make it shorter, etc.
You can write 4 or more different traversal functions, or you can write
1 traversal function that does different work at each node, determined by
passing in a function pointer, to be called for each node.
void postorder(struct tree *t, void (*f)(struct tree *))
{
/* postorder means visit each child, then do work at the parent */
int i;
if (t == NULL) return;
/* visit each child */
for (i=0; i < t-> nkids; i++)
postorder(t->child[i], f);
/* do work at parent */
f(t);
}
You would then be free to write as many little helper functions as you
want, for different tree traversals, for example:
void printer(struct tree *t)
{
if (t == NULL) return;
printf("%p: %d, %d children\n", t, t->label, t->nkids);
}
Parse Tree Example
Let's do this by way of demonstrating what yydebug=1 does for you, on a
very simple example such as:
int fac(unsigned n)
{
return !n ? 1 : n*fac(n-1);
}
Short summary: yydebug generates 1100 lines of tracing output
that explains the parse in Complete Detail. From which we ought
to be able to build our parse tree example.
Observations on Debugging the ANSI C++ Grammar to be more YACC-able
- Expectation
- not that you pick it up by magic and debug it all yourself,
but rather that you spend enough time monkeying with yacc grammars
to be familiar with the tools and approach, and to ask the right questions.
- Tools
- YYDEBUG/yydebug, --verbose/--debug/y.output
- Approach
-
- Run with yydebug=1 to study current behavior
- Do the minimum number of edits necessary to fix*
- reduce obvious epsilon vs. epsilon
- Examine y.output to understand remaining reduce/reduce conflicts.
- Delete the causes if they are not in 120++
- Refactor the causes if they are in 120++
*why? why not?
On the mysterious TYPE_NAME
This may have been covered earlier, it is here for review.
Soule's 120++ text introduces struct's and typedef in passing (interlude 3).
For Fall 2017 you do not
have to handle typedef but DO have to handle class names similarly.
The C/C++ typedef construct is an example where all the beautiful
theory we've used up to this point breaks down. Once a typedef is
introduced (which can first be recognized at the syntax level), certain
identifiers should be legal type names instead of identifiers. To make
things worse, they are still legal variable names: the lexical analyzer
has to know whether the syntactic context needs a type name or an
identifier at each point in which it runs into one of these names. This
sort of feedback from syntax or semantic analysis back into lexical
analysis is not un-doable but it requires extensions added by hand to
the machine generated lexical and syntax analyzer code.
typedef int foo;
foo x; /* a normal use of typedef... */
foo foo; /* try this on gcc! is it a legal global? */
void main() { foo foo; } /* what about this ? */
Suggestions on HW
- Did you Test your Work on cs-445 a.k.a. cs-course42?
- Lots of folks doing work on lots of OSes, but if it doesn't run well
on the test machine, you won't get many points.
- Warnings are seldom OK
- shift/reduce warnings are "usually" OK (not
always). Get rid of other warnings so that when warning of a real
issue shows up, you don't ignore it like "the boy who cried Wolf!".
- Using
{ $$ = $4; } is probably a bad idea
- Q: Why? Q: under what circumstances is this fine?
- Using
{ $$ = $1; } goes without saying
- It is the default... but epsilon rules had better not try it.
- passing an fopen() or a malloc() as a parameter into a function is
probably a bad idea
- usually, this is a resource leak. It gives you no clean and safe
way to close/free.
- Some of you are still not commenting to a minimum professional level
needed for you to understand your own code in 6 months
Semantic Analysis
Semantic ("meaning") analysis refers to a phase of compilation in which the
input program is studied in order to determine what operations are to be
carried out. The two primary components of a classic semantic analysis
phase are variable reference analysis and type checking. These components
both rely on an underlying symbol table.
What we have at the start of semantic analysis is a syntax tree that
corresponds to the source program as parsed using the context free grammar.
Semantic information is added by annotating grammar symbols with
semantic attributes, which are defined by semantic rules.
A semantic rule is a specification of how to calculate a semantic attribute
that is to be added to the parse tree.
So the input is a syntax tree...and the output is the same tree, only
"fatter" in the sense that nodes carry more information.
Another output of semantic analysis are error messages detecting many
types of semantic errors.
Two typical examples of semantic analysis include:
- variable reference analysis
- the compiler must determine, for each use of a variable, which
variable declaration corresponds to that use. This depends on
the semantics of the source language being translated.
- type checking
- the compiler must determine, for each operation in the source code,
the types of the operands and resulting value, if any.
lecture #20 began here
Mailbag
- You marked me down for Valgrind, but I didn't have illegal memory
reads or writes! What gives?
- From hw1.html:
For the purposes of this class, a "memory error" is a
message from valgrind indicating a
read or write of one or more bytes of illegal, out-of-bounds,
or uninitialized memory.
The uninitialized memory part includes messages such as:
==25504== Conditional jump or move depends on uninitialised value(s)
You've been told that the valgrind header and summary,
including memory leaks, are not going to cost you points, I am only
interested in valgrind error messages reported for behavior at runtime.
Any stuff you see in between the valgrind header and summary is either
your output, or valgrind messages that may point at bugs in your code.
Notations used in semantic analysis:
- syntax-directed definitions
- high-level (declarative) specifications of semantic rules
- translation schemes
- semantic rules and the order in which they get evaluated
In practice, attributes get stored in parse tree nodes, and the
semantic rules are evaluated either (a) during parsing (for easy rules) or
(b) during one or more (sub)tree traversals.
Two Types of Attributes:
- synthesized
- attributes computed from information contained within one's children.
These are generally easy to compute, even on-the-fly during parsing.
- inherited
- attributes computed from information obtained from one's parent or siblings
These are generally harder to compute. Compilers may be able to jump
through hoops to compute some inherited attributes during parsing,
but depending on the semantic rules this may not be possible in general.
Compilers resort to tree traversals to move semantic information around
the tree to where it will be used.
Attribute Examples
Isconst and Value
Not all expressions have constant values; the ones that do may allow
various optimizations.
| CFG | Semantic Rule
|
|
E1 : E2 + T
|
E1.isconst = E2.isconst && T.isconst
if (E1.isconst)
E1.value = E2.value + T.value
|
|
E : T
|
E.isconst = T.isconst
if (E.isconst)
E.value = T.value
|
|
T : T * F
|
T1.isconst = T2.isconst && F.isconst
if (T1.isconst)
T1.value = T2.value * F.value
|
|
T : F
|
T.isconst = F.isconst
if (T.isconst)
T.value = F.value
|
|
F : ( E )
|
F.isconst = E.isconst
if (F.isconst)
F.value = E.value
|
|
F : ident
|
F.isconst = FALSE
|
|
F : intlit
|
F.isconst = TRUE
F.value = intlit.ival
|
|
HW Code Sharing Policy Reminder
- You can share ideas but are not to share code with your classmates.
- If you used an external source, be sure to cite it and make clear
the scope/extent of code that is not your own.
- If anything is shared in this class (e.g. yacc grammars, or donuts) it must
be shared with the whole class. Otherwise, it ruins the level playing field
and makes grading impossible...
- On anything else that gives me excessive deja vu in this class,
I will give zeros, or refer you to the
appropriate university committee.
Symbol Table Module
Symbol tables are used to resolve names within name spaces. Symbol
tables are generally organized hierarchically according to the
scope rules of the language. Although initially concerned with simply
storing the names of various that are visible in each scope, symbol
tables take on additional roles in the remaining phases of the compiler.
In semantic analysis, they store type information. And for code generation,
they store memory addresses and sizes of variables.
- mktable(parent)
- creates a new symbol table, whose scope is local to (or inside) parent
- enter(table, symbolname, type, offset)
- insert a symbol into a table
- lookup(table, symbolname)
- lookup a symbol in a table; returns structure pointer including type and offset. lookup operations are often chained together progressively from most local scope on out to global scope.
- addwidth(table)
- sums the widths of all entries in the table.
- "widths" = #bytes.
- The sum of widths is the #bytes needed for the entire memory region
reserved for this scope.
- Examples: activation record (for a function call),
global data section, or class/struct instance.
Worry not about this method until code generation you wish to implement.
- enterproc(table, name, newtable)
- enters the local scope of the named procedure
Note: finish discussing addwidth() and enterproc().
lecture #21 began here
Mailbag
- I was wondering if we should be printing anything out for this assignment
like the symbol table or anything like that
- Historically, the assignment has only required that students print error
messages of various types. However, you almost certainly need to print
out your symbol tables in order to debug things, and I have no great
objection to adding that requirement. Thanks for the request. Let's
revisit HW#3.
Variable Reference Analysis
The simplest use of a symbol table would check:
- for each variable, has it been declared? (undeclared error)
- for each declaration, is it already declared? (redeclared error)
Semantic Analysis in Concrete Terms
Broadly, we can envision the semantic analysis as two passes:
- Pass 1: Symbol Table Population
- Symbol table population is a syntax tree traversal in which
we look for nodes that introduce symbols, including the creation
and population of local scopes and their associated symbol tables.
As you walk the tree, we look for specific nodes that indicate
symbols are introduced, or new local scopes are introduced. What
are the tree nodes that matter (from cgram.y)
in this particular example?
- create a global symbol table (initialization)
- each function_declarator introduces a symbol.
- each init_declarator introduces a symbol.
- oh by the way, we have to obtain the types for these.
- "types" for functions include parameter types and return type
- "types" for init_declarators come from declaration_specifiers,
which are "uncles" of init_declarators
- Pass 2: Type Checking
- Type checking occurs during a bottom up traversal of the expressions
within all the statements in the program.
lecture #22 began here
Mailbag
- I was wondering if it would be better for the hash table to build
it based on the terminals I find in the tree or the non-terminals?
- the keys you are inserting and looking up in hash tables are
the variable names declared in the program you are parsing --
those names came into your tree as terminals/leaves, and not
all the leaves -- only leaves that are names of things (identifier, or
LNAME, or whatever you are calling them), and only when those leaves
appear in particular subtrees/production rules where new variables or
functions (or type names) are being introduced.
- So as I am traversing the tree should I be looking for LNAMEs
and other terminal symbols then to determine if I should insert
or should I look for nonterminals and then as I see those
non terminals grab the LNAME and the other important data
- Sorta the latter, you are usually looking for non terminals or
specific production rules, and then traversing selected children
within which you know you have a list of names being declared.
Announcement
Coeur D'Alene students: I am told your midterm must be taken at the NIC
Testing Center. Please locate that facility, and see what requirements
they will have for you to take that exam at 2:30 on October 17.
- last lecture when I went into semantic.c, I quickly went into the weeds
talking about representing type information -- we need all that, but
we need tree traversal examples worse, and symbol table examples.
- semantic.c has example tree traversals that do different tasks
during semantic analysis.
- this example's treewalks best understood in context of
cgram.y
- this was "ripped out" of a past project
- goal: give you ideas
- not meant to force you to use this code, or do things this way
lecture #23 began here
Mailbag
- So, how many symbol tables do we have to have? More than one?
- One for each package, one for each function, one for each struct type.
- How do I know what symbol table I am using?
- One could implement this as an inherited attribute, or one can
track it with an auxiliary global as one walks around the tree.
If you don't do the inherited attribut, you may have to maintain a
stack of scopes.
When you walk into something that has a more local scope, make that
scope current and use enclosing scopes when more local scopes don't
find a particular symbol you are looking for.
Symbol Table Basics
The goal of a symbol table is to allow storage and retrieval of variable
(and related) information by name. We are associating a data payload
with that name, so we need a struct with the name and the data payload, and
lookup and insert functions on it. What is the data payload?
struct symtab_entry {
char *sym;
struct typeinfo *type; /* as seen previously, two lectures ago */
/* ... more stuff added later ... */
}
We have to be able to look up stuff by name.
We could just do this with a linked list:
struct elem {
struct symtab_entry *ste; // information about a symbol
struct elem *next;
};
struct elem *theEntireSymbolTable;
struct symtab_entry *lookup(struct elem *st, char *name) {
if (st==NULL) return NULL;
if (!strcmp(st->ste->sym, name)) return st->ste;
return lookup(st->next, name);
}
struct elem *insert(struct elem *st, char *name, struct typeinfo *t) {
struct elem *n;
struct symtab_entry *ste = lookup(st, name);
if (ste != NULL) {
fprintf(stderr, "symbol is already inserted\n");
exit(3);
}
/* ste was NULL, make a new one */
ste = malloc(sizeof (struct symtab entry));
ste->sym = strdup(name);
ste->type = t;
n = malloc(sizeof (struct elem));
n->ste = ste;
n->next = theEntireSymbolTable;
theEntireSymbolTable = n;
}
- Pros: simple
- Cons: O(n) does not scale well as n gets big
Aside on malloc()
malloc() can fail and return NULL. Consider something like the following,
that you can use everywhere in place of malloc():
void *ckalloc(int n) // "checked" allocation
{
void *p = malloc(n);
if (p == NULL) {
fprintf(stderr, "out of memory for request of %d bytes\n", n)
exit(4);
}
return p;
}
Hash Functions and Hash Tables for Symbol Tables
- purpose: array-like performance for string lookups in large
collections of strings.
- will be O(1) on average iff
- you have enough buckets and if
- hash function is O(1) and if
- hash function distributes symbols perfectly across buckets
- recommended implementation: array of linked lists
- goal of hash function: produce a unique random integer for
each unique symbol. Then modulo it by # of buckets to pick array index
- How many buckets? Ideally, sized proportionally slightly larger than the
# of symbols, but number of symbols varies widely across all possible
source codes. We can certainly calculate averages and choose # of
buckets large enough to handle the average case well.
Serious/real compilers will grow the # of buckets if necessary.
int hash(char *s) { return 0; } // linked list, O(n)
int hash(char *s) { return s[0];} // hash using first char, x1 x2 x3 hash same
int hash(char *s) { // what does this one do?
int len = strlen(s);
return s[0] + (len>1 ? s[len-1] : 0);
}
int hash(char *s) { // "good enough"; what's weak here?
int i=0, sum = 0, len = strlen(s);
for( ; i<len; i++) sum += s[i];
return sum;
}
Lessons From the Godiva Project
By way of comparison, it may be useful for you to look at
some symbol tables and type representation code that were written for
the Godiva programming language project. Check out its hash function.
Being a dialect of Java, Godiva
has compile-time type checking and might provide relevant ideas for OOP
languages.
lecture #24 began here
Mailbag
- I feel like I am just starring at a wall...
I am just kinda lost as to how to start.
- Start by copying modifying your tree printer to only print
out the names of variables at the point at which they are declared.
- As I am creating new symbol tables, how should I keep track of them?
Should I include like a *next pointer?
-
There is logically a tree of symbol tables. Parent symbol tables (in our
case the symbol table for our "global" package, package main) contain
entries for symbols defined within them, such as functions, so the parent
should be able to reach the children's symbol tables by looking them up by
name within the parent symbol table. On the other hand, children's symbol
tables might want to know their parent enclosing symbol table. For general
nested programming language the child symbol table should contain a parent
pointer. For the special case that is VGo, there isn't much nesting and
you could just have a global variable that knows the root symbol table (for
package main) and every symbol table that is not the root, can rest assured
that its parent is the root.
- Does VGo require the type to be given for every parameter? It kinda
sounds like it does.
- The VGo spec mentions having to know the name and type for every
parameter. But the VGo spec also says you can omit the type of the next
item in a comma separated parameter list is the same type.
- Does VGo support calling a function inside another call, as in
fmt.Println(Compare(t1, New(99,1)));
- Yes.
- How to deal with imported packages: what does -in general- compiler do?
For example, when it imports “math” , does it copy the functions
declarations? Where can I find the “math” package file? Are there in Bison
built-in function to copy these stuff and added them to the source file, or
should I do copy content and edited the source file in C at the main
function?
- Great question. In a real compiler for Java or Go, an import is a
pretty big operation, probably reading from a database to get the declarations
of the package being imported. For VGo we are doing a hardwired special case,
treating these packages as "built-ins", so the compiler can do whatever it
wants in order to get "fmt" and "math/rand" and "time" to work, just enough to
do fmt.Println, rand.Intn, and time.Now.
- What about symbol table lookups related to structs in HW#3, Dr. J? The
homework doesn't talk about them much.
- You should catch redeclared variables in all scopes. You should catch
undeclared variables in all scopes. If you see
x.y in
the source code, how many symbol lookups is that?
- Are we supposed to create a separate symbol table for each function?
Or just a symbol table for functions in general?
- You are supposed to create one "global" symbol table for package main,
one local symbol
table for each function, and one local symbol table for each struct type.
- I am struggling on figuring out how to detect undeclared variables.
- We should talk about this in detail looking at the non-terminals used in
your grammar. With any big vague software task,
it is wise to break it up into smaller, well-defined pieces. Before you
try to find all undeclared variables, you could:
- write a tree traversal that just lists
all the uses of a variable (in expressions, where values are
read or written), showing the variable name and line number. These are
the things that must be checked.
Still too big a job? Break it into even smaller pieces:
- write a tree traversal that just lists the names of functions for
which you have a function body, and therefore a compound statement
that contains executable expressions.
- are there anything besides function bodies where you would have to
check for undeclared variables?
- write a tree traversal that inserts all the variable declarations.
print out the whole symbol table when finished, to show what you've got.
- modify the tree traversal #1 to lookup within the symbol table(s) and
print semantic errors if any lookup fails.
Discussion of "Import", and more Generally, Packages
Suggested approaches for implementing semantic analysis of packages/imports:
- treat "import" like a special "include"
-
- Pros: moderately easy to implement (fmt.go,
mathrand.go, time.go)
-
import x.y.z means class z out of
package x.y. (This is a Java thing. Not in VGo.)
-
import "math/rand" means import the rand package from
the math directory. From the official
Go site:
- a workspace contains repositories
- repositories contain packages
- packages consist of source files in a single directory
Upshot: directories in Go can contain multiple packages.
- Cons: pain to make the VGo lexer/parser do this work.
- respond to "import" by inserting some symbol table entries (hardwired
to the package name)
-
- Pro: don't have cons of the include approach
- Con: either have to reparse whole files in order to suck in types
for symbols we import OR have to write out symbol tables as external
files/repositories of info about compiled packages/classes
Representing Types
In statically-typecheck'ed languages,
the target language's type system must be represented using data
structures in the compiler's implementation language.
In the symbol table and in the parse tree attributes used in type checking,
there is a need to represent and compare source language types. You might
start by trying to assign a numeric code to each type, kind of like the
integers used to denote each terminal symbol and each production rule of the
grammar. But what about arrays? What about structs? There are an infinite
number of types; any attempt to enumerate them will fail. Instead, you
should create a new data type to explicitly represent type information.
This might look something like the following:
struct type {
/*
* Integer code that says what kind of type this is.
* Includes all primitive types: 1 = int, 2=float,
* Also includes codes for compound types that then also
* hold type information in a supporting union...
* 7 = array, 8 = struct, 9 = pointer etc. */
int base_type;
union {
struct array {
int size; /* allow for missing size, e.g. -1 */
struct type *elemtype; /* pointer to type for elements in array,
follow it to find its base type, etc.*/
} a;
struct struc { /* structs */
char *label;
int nfields;
struct field **f;
} s;
struct type *p; /* pointer type, points at another type */
} u;
}
struct field { /* members (fields) of structs */
char *name;
struct type *elemtype;
}
Given this representation, how would you initialize a variable to
represent each of the following types:
int [10][20]
struct foo { int x; char *s; }
Building a Type struct from a Syntax Tree Fragment
/*
* Build Type From Prototype (syntax tree) Example
*/
void btfp(nodeptr n)
{
if (n==NULL) return;
for(int i = 0; i < n->nkids; i++) btfp(n->child[i]);
switch (n->prodrule) {
case INT:
n->type = get_type(INTEGER);
break;
case CHAR:
n->type = get_type(CHARACTER);
break;
case IDENTIFIER:
n->type = get_type(DONT_KNOW_YET);
break;
case '*':
n->type = get_type(POINTER);
break;
case PARAMDECL_1:
n->type = n->child[0]->type;
break;
case THINGY:
n->type = n->child[0]->type;
break;
case PARAMDECL_2:
n->type = clone_type(n->child[1]->type);
n->type->u.p.elemtype = n->child[0]->type;
break;
case PARAMDECLLIST_2:
n->type = get_type(TUPLE);
n->type->u.t.nelems = 1;
n->type->u.t.elems = calloc(1, sizeof(struct typeinfo *));
n->type->u.t.elems[0] = n->child[0]->type;
break;
case PARAMDECLLIST_1:
n->type = get_type(TUPLE)
/* consider whether left child, guaranteed to be a PARAMDECLLIST,
is guaranteed to be a tuple. Maybe its not. */
n->type->u.t.nelems = n->child[0]->type->u.t.nelems + 1;
n->type->u.t.elems = calloc(n->type->u.t.nelems,
sizeof(struct typeinfo *));
for(i=0;i < n->child[0]->type->u.t.nelems; i++)
n->type->u.t.elems[i] = n->child[0]->type->u.t.elems[i];
n->type->u.t.elems[i] = n->child[1]->type;
break;
case INITIALIZER_DECL:
n->type = get_type(FUNC)
n->type->u.f.returntype = get_type(DONT_KNOW);
n->type->u.f.params = n->child[1].type;
break;
case SIMPLE_DECLARATION_1:
n->type = clone_type(n->child[1]->type);
n->type->u.f.returntype = n->child[0]->type;
}
}
lecture #25 began here
Mailbag
- How should I focus my midterm studying? There is a lot of material
in this class and I would like to try to optimize my study time.
Should I focus on the lecture notes? Should I be studying the book?
- Perhaps the best way to study for the exams in this course is to do
your homework assignments. I try to write exam questions that you
should know if you have done your assignments. Having said that,
if I were picking and choosing between the lecture notes or the book
I would hit the lecture notes the hardest, referring to the book
when more (or different) explanations are needed.
Resuming Discussion of Building Type Representation from Syntax Tree
What we saw last time:
- add a .type field to struct treenode.
- some nodes can synthesize their type from their kids
- some nodes can pass type info from one kid down into another
The class lecture went into an example parse tree for a function header.
In C it would be
int f(int x, int y, float z)
In Go the equivalent is
func f(x int, y int, z float64)
The discussion broached questions such as:
- How is the parse tree different under the (left recursive)
go grammar than it was under the (right recursive) example C grammar?
- why not just use the parse tree of the function header as the
"type information" that we store in the symbol table entry for
function f?
- how to construct type information for this function type?
lecture #26 began here
Mailbag
- I still have no idea where to start HW3! What do I?
- There is but a single, powerful magic tool at your
disposal: recursion. Start with basis cases, at leaves.
Make it work for the MOST SIMPLE CASES POSSIBLE before
you worry about anything bigger.
Work your way up the tree.
- Where do I store my symbol tables?
- well if I were you, I'd just get a single (global) symbol table working
before I worried about local scopes, but... the obvious alternative
answer to your question are:
- in the node at the top of each local scope. For example XFNDCL.
In this case, it is an attribute that can be inherited.
- in the symbol table entry for the symbol that owns the scope. For example
main's local symbol table in main's symbol table entry.
After thinking about this, I have come to the conclusion that it may
well be easier to do both, than to do either one by itself. So from now
on, I am going to pretend that you stick pointers to your symbol tables
in both places.
- Is HW#3 really still due Sunday night
- Yes. Well, I was thinking we didn't
want to stretch it out into Midterm week.
Maybe there's a couple days of stretch
possible, at the expense of midterms.
Recursing through Trees Built from go.y
- start at the beginning
- compile programs with
go tool compile foo.go
when testing Go fragments too small to link.
- In the trees, the node names ending
with _N denote production rule #N that builds that nonterminal.
If no _N is given it is presumed to be production rule #1 for
that non-terminal.
| code | tree | comments and/or symbol table
|
|---|
// empty file
| n/a
| syntax error, missing package statement
|
package main
|
FILE
|
PACKAGE_2
/ \
package LNAME
"main"
|
verify package LNAME (must be "main")
create empty symbol table
(nothing to insert)
|
package main
var x int
|
FILE
/ \
PACKAGE_2 XDCLLIST_2
/ \ | \
package LNAME ε COMMON_DCL
"main" / \
LVAR VARDCL
/ \
LNAME LNAME
"x" "int"
|
Construct a type from LNAME "int" because it is VARDCL kid #2.
Insert "x" into current (global) symbol table because it is VARDCL kid #1.
|
package main
func main() { }
|
FILE
/ \
PACKAGE_2 XDCLLIST_2
/ \ | \
package LNAME ε XFNDCL
"main" / | \
LFUNC FNDCL FNBODY_2
/ | \ \
LNAME ATL FNRES STMTLIST
"main" | | |
ε ε ε
|
Construct a FUNC type from FNDCL
- Construct an TUPLE of length 0 from empty ATL
- Construct a VOID type from empty FNRES
Insert "main" into global symbol table
Create a local symbol table
Insert parameters into local symbol table
Insert local variables into local symbol table
|
Connecting Trees to Traversals
/*
* Semantic analysis from syntax tree, VGo Edition
*/
void semantic_anal(struct symtab *current_st, nodeptr n)
{
if (n==NULL) return;
for(int i = 0; i < n->nkids; i++) semantic_anal(current_st, n->child[i]);
switch (n->prodrule) {
case XFNDCL : /* whole function */
n->symtab = n->child[1]->symtab;
populate_locals(n->symtab, n->child[2]);
/*
* visit body to check for undeclared/redeclared
*/
check_variable_uses(n->child[2]);
break;
case FNDCL : /* function header */
char *name = get_func_name(n->child[0]);
n->symtab = mk_symtab();
n->type = get_type(FUNC);
n->type->u.f.returntype = n->child[4]->type;
n->type->u.f.params = n->child[2]->type;
n->type->u.f.symtab = n->symtab;
st_insert(current_st, name, n->type);
populate_params(n->symtab, n->child[2]);
break;
}
}
Discussion of Tree Traversals that perform Semantic Tests
This example illustrates just one of the
myriad-of-specialty-traversal-functions that might be used.
This mindset is one way
to implement semantic analysis.
Suppose we have a grammar rule
AssignStmt : Var EQU Expr
We want to detect if a variable has not been initialized, before it is
used. We can add a boolean field to the symbol table entry, and set it
if we see, during a tree traversal, an initialization of that variable.
What are the limitations or flaws in this approach?
We can write traversals of the whole tree after all parsing
is completed, but for some semantic rules, another option is to
extend the C semantic action for that rule with
extra code after building our parse tree node:
AssignExpr : LorExpr '=' AssignExpr { $$ = alctree(..., $1, $2, $3);
lvalue($1);
rvalue($3);
}
- In this example,
lvalue() and rvalue()
are mini-tree traversals for the lefthand side
and righthand side of an assignment statement.
- Their missions are to
propagate information from the parent, namely, inherited attributes
that tell nodes whether their values are being assigned to (initialized)
or being read from.
- Warning: since this is happening during parsing,
it would only work if all semantic information that it depends on,
for example symbol tables, was also done during parsing.
- Side note: I might be equally or more interested in implementing a
semantic check to make sure the left-hand-side of an assignment is actually
an assignable variable. How would I check for that?
void lvalue(struct tree *t)
{
if (t->label == IDENT) {
struct symtabentry *ste = lookup(t->u.token.name);
ste->lvalue = 1;
}
for (i=0; i<t->nkids; i++) {
lvalue(t->child[i]);
}
}
void rvalue(struct tree *t)
{
if (t->label == IDENT) {
struct symtabentry *ste = lookup(t->u.token.name);
if (ste->lvalue == 0) warn("possible use before assignment");
}
for (i=0; i<t->nkids; i++) {
rvalue(t->child[i]);
}
}
lecture #27 began here
- Does VGo do prototypes?
- I told a student "no" this afternoon, because I've already
asked plenty of you all. What are the implications?
- What is wrong with the following code? It compiles in Go but not VGo!
package main
func main(){
for sum < 1000 {
sum += sum
}
}
-
Great catch. I think several folks had run into this -- I heard rumors --
but until someone gave me a concrete example it was easy to ignore as a
possible case of operator error. But here it is. Not too shockingly, it is
related to the LBRACE vs. '{' hack that was previously addressed. Due to
the syntax of compound literals, the curly brace in this for loop was being
parsed as the start of a compound literal expression, instead of the
for-loop body. I performed the following changes to the official CS 445
go.y in
order to address the problem:
- removed epsilon non-terminal
start_complit
- replaced nonterminal
lbrace with '{'
These changes got this sample program to parse OK for me. We may
yet find some other Go code that won't parse in VGo, particularly related to
the '{' vs LBRACE hack. We shall see.
- Is the following legal in VGo? It is legal Go!
func hello(int) {}
-
Interesting. Here is a discussion of the feature in Go.
No, this is not legal in VGo. Per the VGo spec, parameters are "a
comma-separated list of zero or more variable names and types".
-
What is the difference between a function declaration and a variable
declaration, when it comes to adding the symbols to the table? as far as
the tree is concerned they are almost exactly the same, with the exception
of which parent node you had. Is there (or should there be) a line in the
symbol entry which states the entry as a function vs a variable?
-
You add the symbols to the same table. For HW#3 they are thus treated
basically identically. For HW#4 you put in different type information for
functions (whose basetype says they are a function, and whose typeinfo
includes their parameters and return type) than for simple variables.
-
I have code written which (hopefully) creates the symbol table entry for
variables. This code uses a function which spins down through non-terminals
to get the identifier. Can I use this same function to get the identifier for
a function? A function is
direct_function_declarator: direct_declarator LP ... RP ...
so after the direct_declarator it has other useful things that I'm not sure
need to be in the symbol table entry.
-
You can re-use functions that work through similar subtrees, either as-is
(if the subtrees really use the same parts of the grammar) or by generalizing
or making generic the key decisions about what to do based on production rule.
For example, you might add a flag parameter to a function that spins through
nonterminals, indicating whether this was in a function
declaration or not; that might allow you to tweak the tree traversal to adjust
for minor differences.
-
You state "You do not have to support nested local scopes". Does this mean
there will only be a global scope, or will there be a global + function
scopes, but no secondary scopes inside the local functions?
- Correct, function scopes for locals and parameters, but not nested
local scopes inside those.
Real Life vs. toy lvalue/rvalue example
This example illustrated walking through subtrees looking for specific
nodes where some information was inserted into the tree. In real life...
- information passed down (i.e. inherited attributes) may be passed
as a (second or subsequent)
parameter after the tree node the traversal is visiting.
- this example might apply mainly to local variables whose definition
and use are in this same (function definition) subtree
- if you wanted to ensure a class or global variable was initialized before
use, you might build a flow graph (often used in an optimization or
final code generation phase anyhow)
- variable definition and use attributes are more reliably analyzed
using a flow graph instead of the syntax tree.
For example, if the program starts by calling
a subroutine at the bottom of code which initializes all the
variables, the flow graph will not be fooled into generating warnings
like you would if you just started at the top of the code and checked
whether for each variable, assignments appear earlier in the source
code than the uses of that variable.
(x, y, z int) vs. var a, b, c int
|
In a parameter list
|
In a variable declaration
|
|---|
ATL
/ | \
ATL , ARGTYPE
/ | \ | \
ATL , ARGTYPE LNAME LNAME
| | "z" "int"
ARGTYPE LNAME
| "y"
LNAME
"x"
|
COMMONDCL
/ \
LVAR VARDCL
/ \
DNL NTYPE
/|\ \
DNL , LNAME LNAME
/|\ "c" "int"
DNL , LNAME
| "b"
LNAME
"a"
|
OK, how do we get type information down to the tree nodes where "x"?
Specialized subtraversals and/or multiple passes. This sample is
probably a duplicate of some earlier sample code, just tied to the
non-terminal names of the go.y grammar a bit.
void populate(struct tree *n, struct symtab *st)
{ int i;
if (n==NULL) return;
for(i=0; i<n->nkids; i++)
populate(n->kids[i], st);
switch (n->prodrule) {
case VARDCL:
n->type = n->kid[1].type; // synthesiz
n->kid[0].type = n->type; // inherit
insert_w_typeinfo(n->kid[0], st);
break;
case NTYPE:
n->type = n->kid[0].type;
break;
case LNAME:
if (!strcmp(n->token->text, "int"))
n->type = T_INTEGER;
break;
case ARG_TYPE_LIST_1: /* ATL: arg_type */
break;
case ARG_TYPE_LIST_2: /* ATL: ATL ',' arg_type */
break;
case ARG_TYPE_1: /* AT: name_or_type */
break
case ARG_TYPE_2: /* AT: sym name_or_type */
break
case ARG_TYPE_3: /* AT: sym dotdotdot */
break
case ARG_TYPE_4: /* AT: dotdotdot */
break
}
}
/*
* "inherited attribute" for type could go down by copying from
* parent node to child nodes, or by passing a parameter. Which is better?
*/
void insert_w_typeinfo(struct tree *n, struct symtab *st)
{ int i;
if (n == NULL) return;
for(i=0; i<n->nkids; i++) {
if (n->kids[i]) {
n->kids[i]->type = n->type;
insert_w_typeinfo(n->kids[i], st);
}
}
switch (n->prodrule) {
case DNL: /* ?? nothing needed */
break;
case LNAME:
st_insert(st, n->token->text, n->type);
break;
}
}
lecture #28 began here
Midterm Info
- Historically I've used the day before the midterm for a midterm review.
However, some students may want to study for the midterm earlier than
that. Should I be doing the review on Tuesday instead of Wednesday?
- CDA students: although the NIC Testing Center lists 2-3pm on Thursday
as an "walk-in testing" period, it also says that's for NIC and LCSC only.
Assume you have to schedule your exam time. If you can't get an appointment
for 2:30-3:20 on Thursday, please make one for as close to that time as you
can. Friday is probably booked, so if you can't take it on Thursday you
are probably looking at taking it on Wednesday.
Mailbag
- Do we have to check whether array or map subscripts are legal (in-range)
in this homework?
- Checking "legality" is HW#4's job. In HW#3 you are hopefully getting the
full type information into the symbol table so that you can use it in HW#4.
- My tree's attributes aren't propagating from parent to child, why not?
- If there are tree nodes in the middle, they may have to copy attributes
up or down in order for the information to get from source to destination.
-
In some example code on the class site,
you have the type checking done at the same time as the symbol table entry.
Is there any reason not to break these out into 2 separate functions?
- No, no reason at all. In the old days there were reasons.
- What is wrong with this hash?
for(i=0; i < strlen(s); i++) {
sum += s[i];
sum %= ARRAYSIZE;
}
- How many potential problems can you find in this code?
Type Checking
Perhaps the primary component of semantic analysis in many traditional
compilers consists of the type checker. In order to check types, one first
must have a representation of those types (a type system) and then one must
implement comparison and composition operators on those types using the
semantic rules of the source language being compiled. Lastly, type checking
will involve adding (mostly-) synthesized attributes through those parts of
the language grammar that involve expressions and values.
Type Systems
Types are defined recursively according to rules defined by the source
language being compiled. A type system might start with rules like:
- Base types (int, char, etc.) are types
- Named types (via typedef, etc.) are types
- Types composed using other types are types, for example:
- array(T, indices) is a type. In some
languages indices always start with 0, so array(T, size) works.
- T1 x T2 is a type (specifying, more or
less, the tuple or sequence T1 followed by T2;
x is a so-called cross-product operator).
- record((f1 x T1) x (f2 x T2) x ... x (fn x Tn)) is a type
- in languages with pointers, pointer(T) is a type
- (T1 x ... Tn) -> Tn+1 is a
type denoting a function mapping parameter types to a return type
- In some language type expressions may contain variables whose values
are types.
In addition, a type system includes rules for assigning these types
to the various parts of the program; usually this will be performed
using attributes assigned to grammar symbols.
Example Semantic Rules for Type Checking
- We have previous seen: representation of types using C structs.
- We could maybe use an additional example of constructing such type
structures from a syntax tree, but we saw a basic one, for parameters.
- Now it is time to consider: using such type structures to perform
type checking.
- Type Checking is a primary example
of using synthesized semantic attributes.
- Q before we start: what-all has to be checked?
| grammar rule | semantic rule
|
| E1 : E2 PLUS E3
| E1.type = check_types(PLUS, E2.type, E3.type)
|
Where check_types() returns a (struct type *) value. One of the values
it can return is TypeError. The operator (PLUS) is passed in to
the check types function because behavior may depend on the operator --
the result type for array subscripting works different than the result
type for the arithmetic operators, which may work different (in some
languages) than the result type for logical operators that return booleans.
In-class brainstorming: what other type-check rules can we derive?
Consider the class project. What else will we need to check during semantic
analysis, and specifically during type checking?
Type Promotion and Type Equivalence
When is it legal to perform an assignment x = y? When x and y are
identical types, sure. Many languages such as C have automatic
promotion rules for scalar types such as shorts and longs.
The results of type checking may include not just a type attribute,
they may include a type conversion, which is best represented by
inserting a new node in the tree to denote the promoted value.
Example:
int x;
long y;
y = y + x;
For records/structures, some languages use name equivalence, while
others use structure equivalence. Features like typedef complicate
matters. If you have a new type name MY_INT that is defined to be
an int, is it compatible to pass as a parameter to a function that
expects regular int's? Object-oriented languages also get interesting
during type checking, since subclasses usually are allowed anyplace
their superclass would be allowed.
lecture #29 began here
Mailbag
- Am I understanding correctly that for Homework 3 we don't need any type
information? We could theoretically get full credit without storing type
details in our symbol tables?
- Yes. Well, you need the type information in the symbol table if possible,
but that is to set yourself up for HW#4.
- Is it normal to feel like my code for adding to and checking the
symbol tables is messy, gross, and more hard-coded than I'd like?
- HW#1 and HW#2 were using a declarative language. HW#3 will be
messy and gross by comparison, because from here on out we are using
the imperative paradigm. Walking trees and getting the details all in
there will require a lot of code. How gross it is, "Zis is all up to you"
(from a Geronimo Stilton book).
- Does our language really require comma-separated lists of variables in
declarations? It would be so much easier if it only did one
variable per declaration.
- Don't exaggerate. It would not be that much easier.
But it is FINE to start by just getting it working for one-variable
declarations, then detect and handle two-variable declarations
as a special case, then generalize to 3+ variables.
Midterm Exam Review
The Midterm will cover lexical analysis, finite automatas, context free
grammars, syntax analysis, parsing, and semantic analysis.
Q: What is likely to appear on the midterm?
A: questions that allow you to demonstrate that you know
- regular expressions
- the difference between an DFA and an NFA
- lex and flex and tokens and lexical attributes
- the %union and yylval interface between flex and bison
- context free grammars:
ambiguity, factoring, removing left recursion, etc.
- bison syntax and semantics
- parse trees
- symbol tables
- semantic attributes, type checking
Sample problems:
- Write a regular expression for numeric quantities of U.S. money
that start with a dollar sign, followed by one or more digits.
Require a comma between every three digits, as in $7,321,212.
Also, allow but do not require a decimal point followed by two
digits at the end, as in $5.99
- Write a non-deterministic finite
automaton for the following regular expression, an abstraction
of the expression used for real number literal values in C.
(d+pd*|d*pd+)(ed+)?
- Write a regular expression, or explain why you can't write a
regular expression, for Modula-2 comments which use (* *) as
their boundaries. Unlike C, Modula-2 comments may be nested,
as in (* this is a (* nested *) comment *)
- Write a context free grammar for the subset of C expressions
that include identifiers and function calls with parameters.
Parameters may themselves be function calls, as in f(g(x)),
or h(a,b,i(j(k,l)))
- What are the FIRST(E) and FOLLOW(T) in the grammar:
E : E + T | T
T : T * F | F
F : ( E ) | ident
- What is the ε-closure(move({2,4},b)) in the following NFA?
That is, suppose you might be in either state 2 or 4 at the time
you see a symbol b: what NFA states might you find yourself in
after consuming b?
(automata to be written on the board)
-
(20 points) (a) Explain why a compiler might be less able to recover and
continue from a lexical error than from a syntax error. (b) Explain why a
compiler might be less able to recover and continue from a syntax error than
from a semantic error.
- (30 points) (a) Write a regular expression (you may use Flex extended
regular expression operators) for declarations of the form given by the
grammar below. You may use the usual regular expression for C/C++ variable
names for IDENT. (b) Under what circumstances is it better to use regular
expressions, and under what circumstances is it better to use context free
grammars?
declaration : type_specifier decl_list ';' ;
type_specifier : INT | CHAR | DOUBLE ;
decl_list : decl | decl ',' decl_list ;
decl: IDENT | '*' IDENT | IDENT '[' INTCONST ']' ;
- (30 points) Some early UNIX utilities, like grep and lex, implemented a
non-deterministic finite automata interpreter for each regular expression,
resulting in famously slow execution. Why is Flex able to run much faster
than these early UNIX tools?
- (20 points) Perhaps the most important thing to learn in homework #2
about Flex and Bison was how the two tools communicate information between
each other. Describe this communications interface.
- (30 points) Perhaps the second most important thing to learn in homework
#2 was how and when to build internal nodes in constructing your syntax
tree.
(a) Describe how and when internal nodes need to
be constructed, in order for a Bison-based parser to end up with a tree that holds all leaves/terminal
symbols. (b) Under what circumstances might a new non-terminal node construction site be skipped?
(c) Under what circumstances might some of the leaves/terminal symbols not be needed later during
compilation?
- (40 points) Consider the following grammar for C variable declarations,
given in YACC-style syntax. sm stands for semi-colon. cm stands for
comma. id stands for identifier. lb stands for left square
bracket. intconst stands for integer constant. rb stands for right
square bracket.
VD : CL T DL sm ;
CL : static | register | /* epsilon */ ;
T : int ;
DL : D | D cm DL ;
D : id | AST D | D lb intconst rb ;
a) What are the terminal symbols? b) What are the nonterminal symbols? c) Which nonterminals have
recursive productions? d) Remove left recursive rules from this grammar if there are any.
- (30 points) Write C code that is error free and produces no warnings,
which performs the following tasks: a) declare a variable of type pointer to
struct token, where struct token has an integer category, a string lexeme,
and an integer lineno, b) allocate some memory from the heap large enough to
hold a struct token and point your variable at it, and c) initialize your
memory to all zero bits. You may assume “struct token” with its field
definitions, has already been defined earlier in the C file before your code
fragment.
- (20 points) In looking at your yydebug output, several of you noticed
that it appeared like the same terminal symbol (for example, a semi-colon)
was repeated over and over again in the output, even through sections of
parsing where no syntax error occurred. Why might the same terminal symbol
appear on the input repeatedly through several iterations of a shift-reduce
parser. (30 points) What are semantic attributes? Briefly define and give
an example of the major kinds of semantic attributes that might be used in
semantic analysis for a language such as C++.
- (30 points) Symbol tables play a prominent role in semantic
analysis. How are symbol tables used in type checking? Give an example, with
a brief explanation of how the symbol table is involved.
lecture #30 began here
CDA Midterm Exam Revised Instructions
CDA students: our CDA Associate Chair Bob Rinker went over and looked at
the NIC Testing Center, and decided it would be better for you to take the
exam on Thursday at 2:30 at the Den if possible. See Carrie Morrison there,
who will proctor your exam. If you cannot take the exam at the Den at
2:30, the NIC Testing Center is your backup plan and the midterm can be
taken there at your appointed time; in that case, your midterm grade next
Monday might or might not include your Midterm exam grade, since I might
or might not receive the exam from them before the weekend.
Implementing Structs
Some years, CS 445 implements classes, not structs. But some languages such
as C or VGo have structs. How much of this is similar, and how much needs
to be different, if you had to do classes?
- In C/C++, storing and retrieving structs by their label --
the struct label is how structs are identified.
In Go/VGo, the reserved word
type is more like
a C/C++ typedef.
If you were doing C/C++-style struct labels,
the labels can be keys in a separate hash table, similar to the global
symbol table. You can put them in the global symbol table so long as
you can tell the difference between them and regular symbol names, for
example by storing them as "struct foo" (not a legal name) instead of
just storing them as "foo".
- You have to store fieldnames and their types, from where the struct is
declared. This is conceptually a new local scope. In a production language
you would use a hash table for each struct, but in CS 445 a link list
would be OK as an alternative. Then again, if you've built a hash table
data type for the global and local symbol tables, why not just use it
for struct field scopes?
- You have to use the struct's type information to check the validity of
each dot operator like in
rec.foo. To do this you'll have
to lookup rec
in the symbol table, where you store rec's type. rec's type must be
a struct type for the dot to be legal, and that struct type should
include the hash table or link list that gives the names and types of
the fields -- where you can lookup the name foo to find
its type.
Type Checking Example
Work through a type checking example for the function call to
foo() shown in bold in the example below.
This is a C language
example. The Go/VGo would be pretty similar; how much would be
different?
| C | Go
|
int foo(int x, string y) {
return x
}
int main()
{
int z
z = foo(5, "funf")
return 0
}
|
func foo(x int, y string) int {
return x
}
func main() int {
var z int
z = foo(5, "funf")
return 0
}
|
After parsing, the symbol table (left) and syntax tree for the call (right)
looks like:
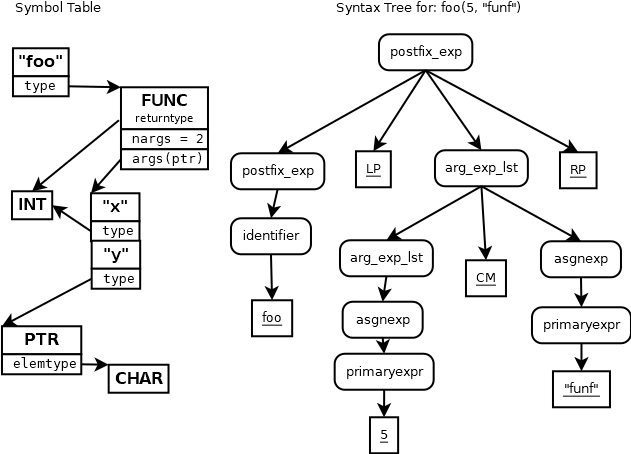
The typecheck of this tree proceeds as a post-fix traversal of the tree.
Type information starts from leaves, which either know their type if they
have one (constants) or look up their type in the symbol table (identifiers).
Can you hand-simulate this in the correct order, filling in .type fields for
each tree node?
Need Help with Type Checking?
- Implement the C Type Representation given previously
- Read the Book
- What OPERATIONS (functions) do you need, in order to check
whether types are correct? What parameters will they take?
Type Checking Function Calls
- at every node in our tree, we build a .type field
- Probably logically two separate jobs:
- Build types for declarations, insert them into symbol table(s).
Performed during the declarations pass of semantic analysis.
- Build types for expressions, lookup symbols from symbol table(s)
Performed during the typecheck pass of semantic analysis.
- For the typecheck pass, a recursive function, typecheck(n), traverses the
tree sticking types into expression nodes.
- you may choose to write a helper function check_types(OPERATOR,
operandtype, operandtype) to do the heavy lifting at each node
- What will type checking a function call need?
- Can we just check the type of the symbol against the type of the call
expression?
- Type of symbol: constructed as per last lecture. In symbol table.
- Type of call expression (built within expression part of grammar), SANS
return type.
- Type check verifies it and replaces it with return type.
void typecheck(nodeptr n)
{
if (n==NULL) return;
for(int i; i < n->nkids; i++) typecheck(n->child[i]);
switch(n->prodrule) {
...
case POSTFIX_EXPRESSION_3: {
n->type = check_types(FUNCALL, n->child[0]->type, n->child[2]->type);
}
}
}
...
typeptr check_types(int operand, typeptr x, typeptr y)
{
switch (operand) {
case FUNCALL: {
if (x->basetype != FUNC)
return type_error("function expected", x);
if (y->basetype != TUPLE)
return type_error("tuple expected", y);
if (x->u.f.nparams != y->u.t.nelems)
return type_error("wrong number of parameters", y);
/*
* for-loop, compare types of arguments
*/
for(int i = 0; i < x->u.f.nparams; i++)
if (check_types(PARAM, x->u.f.params[i], y->u.t.elems[i]) ==
TYPE_ERROR) return TYPE_ERROR;
/*
* If the call is OK, our type is the function return type.
*/
return x->u.f.returntype;
break;
}
}
}
Building Type Information
- So far, the main discussion and pseudo-code for populating
the symbol table that has been presented was for constructing
tuple types for parameter lists, as needed for the type-check
example that we then worked on.
- More generally, how do we construct type representations
from syntax trees for other kinds of declarations?
- If we had time, we could stand to do a more concrete example of
populating the symbol table
Semantic Analysis and Classes
What work is performed during the semantic analysis phase, to support classes?
- Build class-level symbol tables
- Within class member functions, three-level symbol lookup
(local first, then class, then global).
- In the implementation of
x.y (and x->y
in languages that have it),
lookup y within x's type's symbol table,
using privacy rules.
- ...what are the other issues for semantic analysis of objects in
our language, as you understand it?
How to TypeCheck Square Brackets
This is about the grammar production whose right-hand side is:
postfix_expression LB expression RB
- recursively typecheck $1 and $3 ... compute/synthesize their .type fields.
- What type(s) does $1 have to be? LIST/ARRAY (or TABLE, if a table type exists)
- What type(s) does $3 have to be? INTEGER (or e.g. STRING/ARRAY OF CHAR, for tables)
- What is the result type we assign to $$? Lookup the element type from $1
Pseudo-code fragment. Goal is to find errors and determine n's type.
int typecheck_array(struct tree *n)
{
struct tree *n1 = n->child[0];
struct tree *n3 = n->child[2];
/*
* recursively typecheck children.
*/
if (typecheck(n1) == TYPE_ERROR ||
typecheck(n3) == TYPE_ERROR) {
n->type = TYPE_ERROR;
return TYPE_ERROR;
}
/*
* Given the children's types, see whether n1[n3] is legal
*/
switch (n1->type->basetype) {
case LIST:
/* ... insert list typecheck code here */
break;
case TABLE:
/* ... insert table typecheck code here */
break;
default:
bad_type("list or table expected in [] operation", n1);
return TYPE_ERROR;
}
}
Typechecking Square Brackets Example, cont'd
Where we left off was:
/*
* Given the children's types, see whether n1[n3] is legal
*/
switch (n1->type->basetype) {
case LIST:
/* check if n3's type is integer */
if (n3->type->basetype != BT_INTEGER) {
bad_type("list must be subscripted with integers", n3);
return TYPE_ERROR;
}
/* assign n's type to be n1's element type */
n->type = n1->type->u.l.elemtype;
break;
case TABLE:
/* check if n3's type is n1's index type */
if (n3->type->basetype != n1->type->u.t.indextype->basetype) {
bad_type("table must be subscripted with its declared index type", n3);
return TYPE_ERROR;
}
/* assign n's type to be n1's element type */
n->type = n1->type->u.t.elemtype;
break;
default:
bad_type("list or table expected in [] operation", n1);
/* what does n's type field hold, then */
n->type = /* ?? */
return TYPE_ERROR;
}
Did we get something like:
if (n3->type->basetype != INTEGER) {
bad_type("index must be integer in [] operation", n3);
}
n->type = n1->type->elemtype;
and
if (n3->type->basetype != n1->type->indextype) {
bad_type("index type must be compatible in [] operation", n3);
}
n->type = n1->type->elemtype;
What other type checking examples should we be doing?
So far in lecture we have seen possibly-too-handwavy examples of
- Operators like x + y
- Parameters for a function call f(x,y) where tuple types must be checked
- Subscript operator x[y]
What else would help you wrap your brains around type checking?
lecture #m began here
Midterm Exam Discussion
lecture #31 began here
HW#3 Discussion
- As of 10/22, there are 17 submissions out of 29 enrollees.
I am working vigorously on grading them. Maybe by tomorrow.
- I will update, if possible, midterm grades to reflect HW#3;
at that point those who have a decent HW#3 score may see a boost
relative to those who do not. Midterm grades are not used for
anything, they are merely advisory.
- If you need assistance with HW, please make an appointment and come visit.
I can also do Zoom appointments. Screen sharing is great.
- I am not very concerned about "lateness"
- I am concerned about preserving enough time for you to finish
semantic analysis and write a code generator.
- HW#4 is due in a couple weeks.
"Mailbag"
- I am having a problem with a segmentation fault. Can you help?
- When sticking print statements into your program no longer cuts it,
your two best hopes are GDB and Valgrind. Yes, I can help.
- the first thing I will want to see is your valgrind run on your segfault
- the second thing I am going to want to see is your open gdb session
at the point of the segfault, with the "where" output, and the "print"
command run on each variable on the line where the segfault occurred
-
The problem is, there's just so much to type check (I mean, literally
everything has a type!); can you suggest any ways to go about this in a
quicker manner, or anything in the aforementioned list that could be
pruned/ignored?
-
- Not literally. The expression grammar.
And the subset of declarations that you must support.
-
The type checking will typically not happen on $$=$1 rules, so
the expression grammar has around 18 productions where type checking
goes.
- Feel free to rewrite the grammar to reduce the number of productions
where you do type checking.
- Type checking rules for like-minded operators are identical; use that.
- Write helper functions, share common logic.
- Hey, look how easy it is to modify our tree-print function to instead
generate a .dot file which the
dot(1) program on cs-course42
can turn into a tree that looks like this:
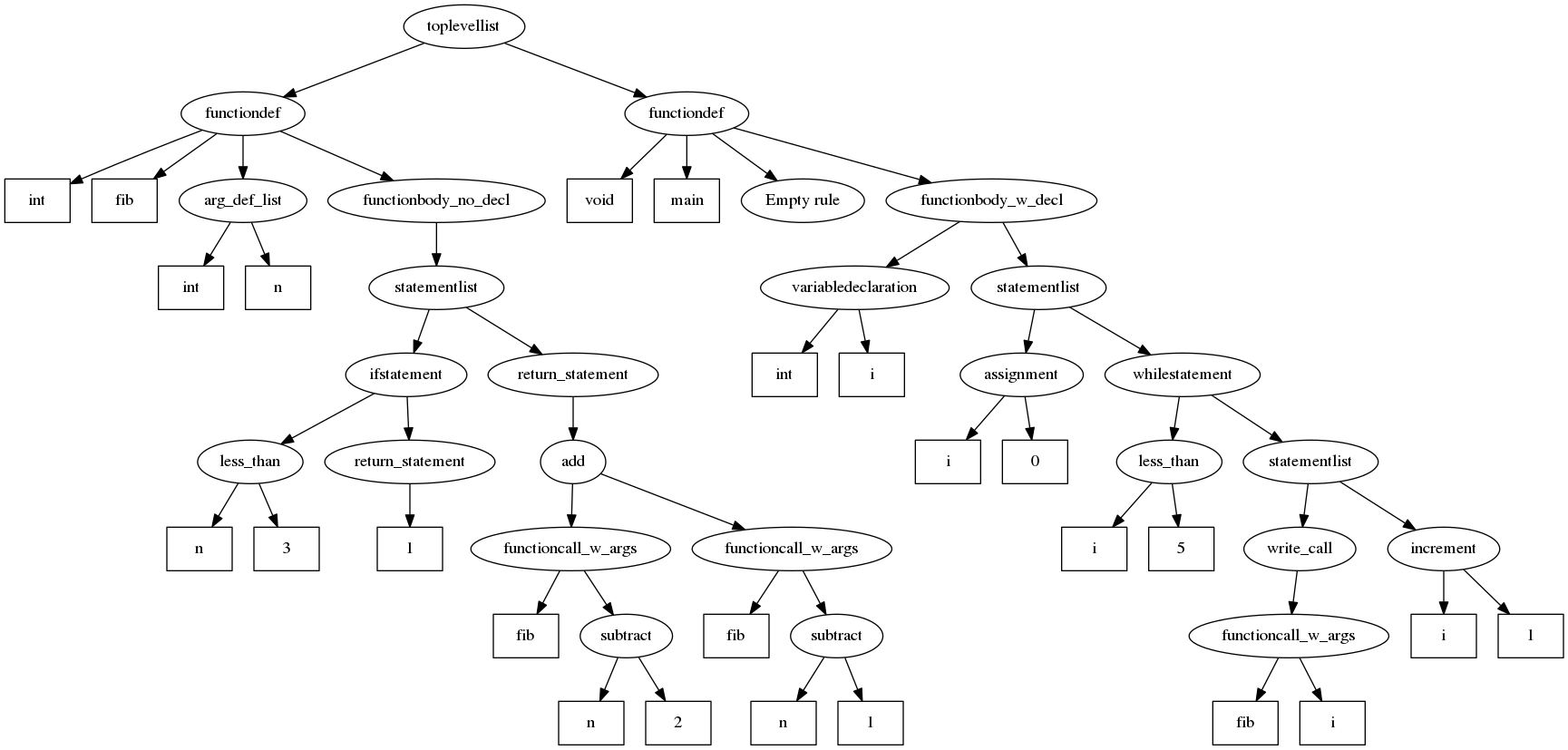
[Student shows ~110 lines of C code that writes
two .dot files with different levels of detail via a traversal function
similar to your HW#2 tree printer.]
- That is pretty darned awesome, thank you. Folks are encouraged to check
out
dot(1).
This kind of tree could be extended with type info that might be really
useful for debugging HW#4!
Another Typecheck Example
Consider the following small program.
| C | Go
|
|---|
int fib(int n)
{
if (n < 3) { return 1; }
return fib(n-2) + fib(n-1);
}
void main()
{
int i;
i = 0;
while (i < 5) {
write(fib(i));
i += 1;
}
}
|
package main
import "fmt"
func fib(n int) int {
if n < 3 { return 1 }
return fib(n-2) + fib(n-1)
}
func main() {
var i int
for i < 7 {
fmt.Println(fib(i))
i += 1
}
}
|
lecture #32 began here
HW#3 Status
- First batch graded. Later submitters will be graded real soon.
- Many in the first batch will want to resubmit, with fixes
- Run the test cases yourself on cs-445/cs-course42.
If I didn't give you points for a test case that runs OK for you,
I want to know about it so I can correct your grade.
- Some folks confused about redeclarations: a global can be redeclared
in a local scope. You can't have the same symbol defined within the
same (global or local) scope.
- Ideas regarding built-ins. Do functions like Println really have to
be in a separate (package fmt) symbol table?
fib() Type Checking Example, cont'd
For what it's worth, I did work on gearing up to use the student-suggested
parse tree generator via the dot program.
- official go.y was tweaked with some updates
- Student's graph.c hacked a bit for the purpose
- But between grading and other obligations, I have not got it all wired
up into my VGo reference implementation yet.
lecture #33 began here
Mailbag
- When creating an array VGo allows for the following:
var x []int
What should the array size be when this happens? Is this supposed to be an
all-knowing infinite array or an empty array?
- I think we discussed this in class last time -- this syntax is in Go
but not in VGo.
From Type Checking on Towards Code Generation
- We may yet want to do a larger example of type checking.
- It is fair game for you to ask more questions as you work on it.
- Main reason to compute all this type information was: we need it
for code generation. And we need it because different types are
different sizes and call for different machine instructions.
- Fancy words for adding information to the syntax tree (and symbol tables,
which are mainly used so you can look up things in the syntax tree):
decoration, annotation... basically, it is a fundamental task of computing
to turn data into information by analyzing it
and adding value.
Run-time Environments
- How does a compiler (or a linker) compute the addresses for the various
instructions and references to data that appear in the program source code?
- To generate code for it, the compiler has to "lay out" the data as it will
be used at runtime, deciding how big things are, and where they will go.
- Relationship between source code names and data objects during execution
- Procedure activations
- Memory management and layout
- Library functions
Scopes and Bindings
- Variables may be declared explicitly or implicitly in some languages
- Scope rules for each language determine how to go from names to
declarations.
- Each use of a variable name must be associated with a declaration.
This last item is generally done via a symbol table. In most compiled
languages it happens at compile time (in contrast, for example ,with LISP).
Environment and State
Environment maps source code names onto storage addresses (at compile time),
while state maps storage addresses into values (at runtime). Environment
relies on binding rules and is used in code generation; state operations
are loads/stores into memory, as well as allocations and deallocations.
Environment is concerned with scope rules, state is concerned with things
like the lifetimes of variables.
Runtime Memory Regions
Operating systems vary in terms of how the organize program memory
for runtime execution, but a typical scheme looks like this:
| code
|
|---|
| static data
|
|---|
| stack (grows down)
|
|---|
| heap (may grow up, from bottom of address space)
|
The code section may be read-only, and shared among multiple instances
of a program. Dynamic loading may introduce multiple code regions, which
may not be contiguous, and some of them may be shared by different programs.
The static data area may consist of two sections, one for "initialized data",
and one section for uninitialized (i.e. all zero's at the beginning).
Some OS'es place the heap at the very end of the address space, with a big
hole so either the stack or the heap may grow arbitrarily large. Other OS'es
fix the stack size and place the heap above the stack and grow it down.
Questions to ask about a language, before writing its code generator
- May procedures be recursive? (Duh, all modern languages...)
- What happens to locals when a procedure returns? (Lazy deallocation rare)
- May a procedure refer to non-local, non-global names?
(Pascal-style nested procedures, and object field names)
- How are parameters passed? (Many styles possible, different
declarations for each (Pascal), rules hardwired by type (C)?)
- May procedures be passed as parameters? (Not too awful)
- May procedures be return values? (Adds complexity for non-local names)
- May storage be allocated dynamically (Duh, all modern languages...
but some languages do it with syntax (new) others with library (malloc))
- Must storage by deallocated explicitly (garbage collector?)
lecture #34 began here
Mailbag
- I'm still working on hw3 since I can't get my assignment 3 working clean
enough for hw4. I know thet we are half way through hw4 time. So what should
I do? I do not wanna fail this class and its not like I haven't been putting
lots of effort into it.
- You are graded relative to your peers, and many
of your peers are also far behind. If you have been putting lots of effort,
and you are getting instructor help when you get stuck, you should be able
to make progress on your HW#3. This week is your last week to decide
whether to drop, and possibly try Dr. Heckendorn next semester, or whether
to stay in. If you stay in, and give it your best shot, odds are good
that relative to your peers, you will be OK.
"Modern" Runtime Systems
Modern languages' runtime systems have extra properties compared with
that of a traditional language like C. Here are a few examples.
- A "self" or "this" in every method call.
- Possibly implemented via a dedicated register, or an implicit,
extra parameter. Either way, OO slightly alters the activation record.
- Garbage collection.
- Automatic (heap) storage management is one of the most important features
that makes programming easier.
The Basic problem in garbage collection is: given a piece of memory, are there
any pointers to it? (And if so, where exactly are all of them please).
Approaches:
- reference counting
- traversal of known pointers (marking)
- copying (2 heaps approach)
- compacting (mark and sweep)
- generational
- conservative collection
Note that there is a fine
paper presenting a "unified theory of garbage collection
- Reflection.
- Objects can describe themselves, via a set of member functions.
This plays a central role in Visual GUI builders, IDE's,
component architectures and other uses.
- Just-in-time compilation.
- A virtual machine ("byte code") execution model...can be augmented
by a compiler built-in to the VM that converts VM instructions
to native code for frequently executed methods or code blocks.
- Security model.
- Modern languages may attempt to guarantee certain
security properties, or prevent certain kinds of attacks.
For what its worth, goal-directed programs in languages such as Unicon have
an activation tree each instant, due to suspended activations that may be
resumed for additional results. The lifetime view is a sort of
multidimensional tree, with three types of nodes.
Activation Records
Activation records organize the stack, one record per method/function call.
| return value
|
| parameter
|
| ...
|
| parameter
|
| previous frame pointer (FP)
|
| saved registers
|
| ...
|
| FP--> | saved PC
|
| local
|
| ...
|
| local
|
| temporaries
|
| SP--> | ...
|
At any given instant, the live activation records form a chain and
follow a stack (push/pop) discipline for allocation/deallocation.
Since each activation record contains a pointer to the previous one,
it is really pretty much a linked list we are talking about, with a
base pointer register holding the pointer to the top of the stack.
Over the lifetime of the program, all these activation records,
if saved, would form a gigantic tree. If you remember all
prior execution up to a current point, you have a big tree in which
its rightmost edge are live activation records, and the non-rightmost
tree nodes are an execution history of prior calls. (Program Monitoring
and Visualization could allow us to depict and inspect this history tree.)
Variable Allocation and Access Issues
Given a variable name, how do we compute its address?
- globals
- easy, symbol table lookup... once we have figured out how to
allocate addresses in a process that does not exist yet.
- locals
- easy, symbol table gives offset in (current) activation record
- objects
- Is it "easy"? If no virtual semantics*, symbol table gives offset in
object, activation record has
pointer to current object in a standard location. (This is the
reason C++ does not use virtual semantics by default.)
For virtual semantics, generate code to look up offset
in a table at runtime, based on the current object's type/class.
- locals in some enclosing block/method/procedure
- ugh. Pascal, Ada, and friends offer their own unique kind of pain.
Q: does the current block support recursion? Example: for procedures
the answer would be yes; for nested { { } } blocks in C the answer
would be no.
- if no recursion, just count back some number of frame pointers based
on source code nesting
- if recursion, you need an extra pointer field in activation record
to keep track of the "static link", follow static link back some
# of times to find a name defined in an enclosing scope
*What are "Virtual" Semantics?
C++ is (just about) the only major object-oriented language
that has to compete with C in the performance arena. For this
reason, it chose early on to be different than every other
OO language. By default, if you are working on a class Foo
object, you can find Foo's member variables and call Foo's
methods by compile-time-determinable memory offsets and
addresses. So a class is basically no worse than a struct to
generate code for.
If you say the keyword "virtual" in C++, or if you use just
about any other OOP language, subclassing and interfacing
semantics mean that the address referred to by o.x or o.m()
has to be calculated at runtime by looking up o's actual
class, using runtime type information.
Sizing up your Regions and Activation Records
Add a size field to every symbol table entry. Many types are not required
for your C445 project but we might want to discuss them anyhow.
- The size of chars is 1. We could make them use an alignment of 8,
but then arrays of char would be all...wrong.
- The size of integers is 8 (for x86_64; varies by CPU).
- The size of reals is... 8 (for x86_64 doubles; varies by CPU).
- The size of strings is... 8? (varies by CPU and language)
- The size of arrays is (sizeof (elementype)) * the number of elements.
In static languages.
The size of arrays/lists in dynamic languages might be more complicated.
- what about sizes of structs/objects? They are the size of the sum of
their members... after adding in padding to meet alignment requirements.
You do this sizing up once for each scope. The size of each scope is the
sum of the sizes of symbols in its symbol table.
lecture #35 began here
Midterm Grades
- The midterm grades have been adjusted to account for HW#3.
- Some grades went up and some went down depending on what I
have for your HW#3 grade.
- Many of you have done significant work on HW#3 but it hasn't run for me
yet, so your grade does not reflect it.
- As you get your HW#3 graded,
your midterm grade and your overall course outlook should get sunnier.
- Feel free to consult with me if you are concerned about your prospects.
- Generally, a good outcome involves you persisting, and getting help, and
making progress.
Intermediate Code Generation
Goal: list of machine-independent instructions for each procedure/method
in the program. Basic data layout of all variables.
Can be formulated as syntax-directed translation
- add new semantic attributes where necessary.
For expression E we might have
-
E.place
- the location that at run-time will hold the value of E
-
E.code
- the sequence of intermediate code statements evaluating E.
How does the compiler talk at compile-time about addresses that
will exist at runtime?
- Option (A): leave everything as names for now. "declare" the names
in intermediate code, specifying which memory region they live in, and
how many bytes big they are. assume an assembler will convert names to
addresses during final code generation.
- Option (B): designate only four names for the four memory regions:
code, global/static, stack, and heap. Specify all addresses as offsets
in one of those regions. For first two, offsets are relative to a base
pointer that is the start of the two region. For the latter two, offsets
are relative to a register (current activation record/base pointer, and
current "this/self" object pointer).
Helper Functions for Intermediate Code Generation
- new helper functions, e.g.
newtemp(n)
- returns a new temporary variable each time it is called.
Parameter
n could be #words, or #bytes. Let's say it
is the number of 8-byte words. Default is
one word (8 bytes), always out of the local region, on the stack.
newlabel()
- returns a new label each time it is called. A label is a name for
a code region address, but for practical purposes newlabel() could
just return a unique integer i by incrementing a counter each time,
or string "L"||i (e.g. "L29") each time it is called.
- actions that generate intermediate code formulated as semantic rules
These helper functions might really be best described
as returning "addresses". Intermediate code addresses
are described down below.
Semantic Rules for Intermediate Code Generation
Code for evaluating traditional expressions can be synthesized
via bottom-up traversal.
| Production | Semantic Rules |
|---|
| S -> id ASN E | S.place = id.place
S.code = E.code || gen(ASN, id.place, E.place)
|
| E -> E1 PLUS E2 | E.place = newtemp()
E.code = E1.code || E2.code || gen(PLUS,E.place,E1.place,E2.place)
|
| E -> E1 MUL E2 | E.place = newtemp()
E.code = E1.code || E2.code || gen(MUL,E.place,E1.place,E2.place)
|
| E -> MINUS E1 | E.place = newtemp()
E.code = E1.code || gen(NEG,E.place,E1.place)
|
| E -> LP E1 RP | E.place = E1.place
E.code = E1.code
|
| E -> IDENT | E.place = id.place
E.code = emptylist()
|
Three-Address Code
Basic idea: break down source language expressions into simple pieces that:
- translate easily into real machine code
- form a linearized representation of a syntax tree
- allow us to check our own work to this point
- allow machine independent code optimizations to be performed
- increase the portability of the compiler
You can literally just make up this intermediate code file format. It
should be human readable and resemble assembler code.
Instructions:
| mnemonic | C equivalent | description
|
|---|
ADD,SUB,MUL,DIV | x = y op z; | store result of binary operation on y and z to x
|
|---|
NEG | x = -y; | store result of unary operation on y to x
|
|---|
ASN | x = y | store y to x
|
|---|
ADDR | x = &y | store address of y to x
|
|---|
LCONT | x = *y | store contents pointed to by y to x
|
|---|
SCONT | *x = y | store y to location pointed to by x
|
|---|
GOTO | goto L | unconditional jump to L
|
|---|
BLT,... | if x rop y then goto L | binary conditional jump to L; rop is a "relational operator" (comparison)
|
|---|
BIF | if x then goto L | unary conditional jump to L
|
|---|
BNIF | if !x then goto L | unary negative conditional jump to L
|
|---|
PARM | param x | store x as a parameter
|
|---|
CALL | call p,n,x | call procedure p with n parameters, store result in x
|
|---|
RET | return x | return from procedure, use x as the result
|
|---|
Declarations (Pseudo instructions):
These declarations list size units as "bytes"; in a uniform-size environment
offsets and counts could be given in units of "words", where a slot (8 bytes
on 64-bit machines) holds anything.
| Declaration | Definition
|
|---|
global x,n1,n2 | declare a global named x at offset n1 having n2 bytes of space
|
proc x,n1,n2 | declare a procedure named x with n1 bytes of parameter space and n2 bytes of local variable space
|
local x,n | declare a local named x at offset n from the procedure frame.
Optional, allows you to use names in your
three-address instructions to denote the offset. Beware scope.
|
label Ln | designate that label Ln refers to the next instruction
|
end | declare the end of the current procedure
|
lecture #36 began here
Mailbag
- How do I get started on code generation?
- Start at the leaves, a.k.a. basis cases.
- Fill in attributes, possibly one at a time.
- For example, assign .place values for everything.
- Allocate all your labels and temporary variables
- Assign .true and .false fields in your condition exprs
- You can do all this in 1, 2, or 3 or more tree traversals
After you have done these things (you may need to print trees
that show), you are ready to start allocating .code
TAC for Composites/Containers and Object Oriented Code
- Arrays and structs hold multiple values.
- the address of a value is computed as an offset from a base
address for the entire composite object.
- One can use the existing TAC instructions, by
loading a base address explicitly using ADDR and then performing explicit
arithmetic on it.
- Or one can add new TAC instructions as needed e.g. for array, struct,
or map objects.
The sketchiness of the following table is pretty good evidence that we are
just making this up as we go along.
| mnemonic | equivalent | description
|
|---|
MEMBER | x = y.z | lookup field named z within y, store address to x
|
|---|
NEW | x = new Foo,n | create a new instance of class named x, store
address to x.
Constructor is called with n parameters (previously pushed
on the stack).
|
|---|
class | class x,n1,n2 | pseudoinstruction to declare a class named x with n1 bytes of class variables and n2 bytes of class method pointers
|
|---|
field | field x,n | pseudoinstruction to declare a field named x at offset n in the class frame
|
|---|
Note: no new instructions are introduced for a member function call. In a
non-virtual OO language, a member function call o.m(x) might be
translated as Foo__m(o,x), where Foo is
o's class. Other translation schemes are possible.
Variable Reference, Dereference, and Assignment Semantics
Given, say, x having a value of 2, what does the following compute?
int y = x + (x = x + 1) + x;
OK, what about
int y = x + x + (x = x + 1) + x;
In order to get the answers right, one has to understand the moment at which
a variable reference is computed versus the moment at which it is dereferenced
to obtain its value, versus the moment at which it is assigned a new value.
Operator precedence (and parentheses) determine what order the expressions
are evaluated. But evaluating something as simple as
expr+expr can give surprise results if variables' values
can change between their reference construction and dereferencing operation.
Tree Traversals for Moving Information Around
Like with semantic analysis, the intermediate code generation game is
largely one of moving information around in the tree.
- NOT a "blind" traversal that does the same thing at each node.
- often a switch statement pre- or post- the traversal of children
- switch cases are the grammar rules used to build each node
- lots of similar-but-different cases, for similar-but-different
production rules for the same non-terminal.
The alternative to writing one huge recursion
consisting of gigantic switch statements is the "swarm" model:
write a suite of mutually-recursive functions that know
how to do work for each different rule or each different type of
non-terminal node for that traversal.
Traversal code example
The following code sample illustrates a code generation tree traversal.
Note the gigantic switch statement. A student once asked the question
of whether the link lists might grow longish, and if one is usually appending
instructions on to the end, wouldn't a naive link list do a terrible
O(n2) job. To which the answer was: yes, and it would be good
to use a smarter data structure, such as one which stores both the head
and the tail of each list.
void codegen(nodeptr t)
{
int i, j;
if (t==NULL) return;
/*
* this is a post-order traversal, so visit children first
*/
for(i=0;i<t->nkids;i++)
codegen(t->child[i]);
/*
* back from children, consider what we have to do with
* this node. The main thing we have to do, one way or
* another, is assign t->code
*/
switch (t->label) {
case PLUS: {
t->code = concat(t->child[0].code, t->child[1].code);
g = gen(PLUS, t->address,
t->child[0].address, t->child[1].address);
t->code = concat(t->code, g);
break;
}
/*
* ... really, a bazillion cases, up to one for each
* production rule (in the worst case)
*/
default:
/* default is: concatenate our children's code */
t->code = NULL;
for(i=0;i<t->nkids;i++)
t->code = concat(t->code, t->child[i].code);
}
}
Codegen Example #1
- A lecture or two ago we had a request in class to do an example
of intermediate code generation.
- But we aren't ready to do any non-toy example yet, you
have to get through some more lecture material on code generation for
control flow.
- But consider the following example.
void main()
{
int i
i = 5
i = i * i + 1
write(i)
}
We want something like
proc main,0,32
ASN loc:0,const:5
MUL loc:8,loc:0,loc:0
ADD loc:16,loc:8,const:1
ASN loc:0,loc:16
PARAM loc:0
CALL write,1,loc:24
RETURN
We will do more substantive examples, in a bit.
lecture #37 began here
Mailbag
- the following is legal in Go.
var x int
var y float64
x, y = 5, 10.4
Is this legal VGo? Are they allowed to have different types in the
declaration at once such as this having both int and float64?
- I think we've said that "multiple assignment" was not in VGo. The only
possible waffle I've done was about reading input, because the most
fundamental functions for reading input in Go require multiple assignment
syntax.
Reading input in VGo
Based on current information about the alternatives, I think we
want to support fmt.Scanln(). That means that there is exactly
one kind of pointer we should allow in VGo.
Options were:
- Use the blank identifier and introduce a package bufio with a NewReader
that returns a predefined type *Reader and a package os with Stdin.
Support a very limited multiple
assignment in order to accomodate ReadString(), which returns both a string
and a failure.
var reader *bufio.Reader
reader = bufio.NewReader(os.Stdin)
text, _ = reader.ReadString('\n')
Note that if I had 445 to do over again, I might just tell us to support
multiple assignment, since it is about the same logic (type tuples) as what
you have to do for parameter passing, anyhow.
- Use a pointer:
fmt.Scanln(&text)
- ... your better option here?
While we are at it, how do you compare strings in Go?
if strings.Compare("exit", text) == 0 {
...
}
Compute the Offset of Each Variable
- Add an address field to every symbol table entry.
- The address contains a region plus an offset in that region.
- No two variables may occupy the same memory at the same time.
- At the intermediate code level, do not bother to re-use memory.
In optimization and then in final code, re-use will be a big thing.
Locals and Parameters are not Contiguous!
For each function you need either to manage two separate regions
for locals and for parameters, or else you need to track where
in that region the split between locals and parameters will be.
This may become more "interesting" if parameters are passed in registers.
Basic Blocks
A basic block is a sequence of 1+ instructions in which
there are no jumps into or out of the middle. In the most extreme
case, every instruction is a basic block. Start from that perspective
and then lump adjacent instructions together if nothing can come between
them.
What are the basic blocks in the following 3-address code?
("read" is a 3-address code to read in an integer.)
read x
t1 = x > 0
if t1 == 0 goto L1
fact = 1
label L2
t2 = fact * x
fact = t2
t3 = x - 1
x = t3
t4 = x == 0
if t4 == 0 goto L2
t5 = addr const:0
param t5 ; "%d\n"
param fact
call p,2
label L1
halt
Discussion of Basic Blocks
- Basic blocks are often used in order to talk about
specific types of optimizations.
- For example, there are optimizations that are only safe to do
within a basic block, such as "instruction reordering for superscalar
pipeline filling".
- So, why introduce basic blocks here?
- our next topic is intermediate code for control flow, which includes
gotos and labels, so maybe we ought to start thinking in terms of
basic blocks and flow graphs, not just linked lists of instructions.
- view every basic block as a hamburger
- it will be a lot easier to eat if you
sandwich it inside a pair of labels:
label START_OF_BLOCK_7031
...code for this basic block...
label END_OF_BLOCK_7031
- the label sandwich lets you:
-
- target any basic block as a control flow destination
- skip over any basic block
For example, for an if-then statement, you may need to jump to
the beginning of the statement in the then-part...or you may need
to jump over it, the choice depending on the outcome of a boolean.
Yeah, these lecture notes repeat themselves about the label sandwich, almost
immediately. That must be on purpose.
C Operators
In case you were fuzzy on the operators you need to support:
| Essential | Non-essential
|
|---|
| = += -= | *= /= %= <<= >>= &= ^= |=
|
| + - * / % | >> << ++ -- ^
|
| && || ! | & | ~
|
| < <= > >= == != | ternary x ? y : z
|
| expr[expr] x.y | &x x->y *x
|
| x:=:y; d x; y d x; #x expr[i:j]
|
Plus concatenation, which is invisible, but not unimportant.
lecture #38 began here
Fully Committed and Past the Drop Date
After last week's drop deadline, there are now 29 in the class, including
two EO and three in CDA. Congratulations on sticking it out.
HW#4 is due tonight at 11:59pm. There should be lots of juicy questions!
Mailbag
- How late is the late fee on HW#4?
- According to the complex late fee schedule I published earlier, the HW#4
late fee is 4% per day. I reserve the right to reduce that late fee if
individual circumstances (health, etc.) warrant. The bigger cost of
lateness is if you end up with goose eggs in HW#5 and HW#6 -- those can really
cost you in your final grade.
- How do I typecheck Go's
make(x) function?
- Good catch: this is not a normal function, is it? If I say
m = make(map[string]Vertex)
I am constructing a map, and the argument is not a regular value at all --
it is a type. I suggest you treat make as a special case. You can verify
that the type is a map type. You can make the return type of make() be
whatever type was passed in as its argument. To generate
code for it, we need a strategy.
- What string operations do we have to support?
- Strings are a built-in immutable type with subscript and len(s) built-in
function. Although I would really like to strings.Compare() and a few
other items from the package strings...nope you do not have to do them.
- Are we supporting comparisons of doubles with ==, !=, <=, and >=?
- Yes.
- Is it possible/legal to have variables of type void?
- No.
- To what types of variable is it legal to assign 'nil'?
- Reference types: list, tables and class instances can be nil.
But you almost never have to say 'nil' in Go because variables
all start with the value nil automatically.
Intermediate Code for Control Flow
Code for control flow (if-then, switches, and loops) consists of
code to test conditions, and the use of goto instructions and
labels to route execution to the correct code. Each chunk of code
that is executed together (no jumps into or out of it) is called
a basic block. The basic blocks are nodes in a control flow graph,
where goto instructions, as well as falling through from one basic block
to another, are edges connecting basic blocks.
Depending on your source language's semantic rules for things like
"short-circuit" evaluation for boolean operators, the operators
like || and && might be similar to + and * (non-short-circuit) or
they might be more like if-then code.
A general technique for implementing control flow code:
- add new attributes to tree nodes to hold labels that denote the
possible targets of jumps.
- The labels in question are sort of
analogous to FIRST and FOLLOW
- for any given list of instructions
corresponding to a given tree node,
add a .first attribute to the tree to hold the label for the beginning
of the list, and a
.follow attribute to hold the label for the next
instruction that comes after the list of instructions.
- The .first attribute can be easily synthesized.
- The
.follow attribute must be
inherited from a sibling.
If-Then and If-Then-Else
The labels have to actually be allocated and attached to instructions
at appropriate nodes in the tree corresponding to grammar production
rules that govern control flow. An instruction in the middle of a
basic block need neither a first nor a follow.
| C syntax | Attribute Manipulations
|
|---|
| S->if '(' E ')' S1 | E.true = newlabel();
E.false = S.follow;
S1.follow = S.follow;
S.code = E.code || gen(LABEL, E.true)||
S1.code
|
| S->if '(' E ')' S1 else S2
| E.true = newlabel();
E.false = newlabel();
S1.follow = S.follow;
S2.follow = S.follow;
S.code = E.code || gen(LABEL, E.true)||
S1.code || gen(GOTO, S.follow) ||
gen(LABEL, E.false) || S2.code
|
lecture #39 began here
Mailbag
- When we are inputting multiple files for the compiler, should we be
resetting the global table or allowing for redeclarations of global
variables to carry over to the other files? I noticed that this was the
first assignment in the specification that we should be treating all the
files as one with a very large name space and wanted to get clarification.
- I previously said in class that we would skip multi-file translation
for HW#3 and beyond, back before we understood that Go (and VGo) would
require a full separate pass to populate the symbol table.
If I had it to do over again, I would say: handle multiple files, and allow
redeclarations of packages, and leave the package main global symbol table
around across all specified files. Not sure I want to change anything to be
harder at this point, only want to change things to be easier, so at the
moment as things stand, you do not have to handle multiple files.
- I can easily fix some of my HW#3 problems. Can I turn in HW#3 to try
and grind a couple more points out of you?
- BBlearn will let you resubmit.
If you lost catastrophic points, it is definitely worth resubmitting.
If you only missed a few, I probably will assess a late fee that makes
the resubmit mostly moot. Fix issues anyhow so you don't lose points
on HW#4-6.
- Do we need separate intermediate code instructions for floating point
and for integer operations?
- Good question. What do you think?
Generating Code for Conditions
Understanding the big picture on code generation for control structures such
as if's and while's requires an understanding of how to generate code for
the boolean expressions that control these constructs.
- Consider the inherited attributes such as E.true and E.false.
- These are the destination instruction labels that say where to
go if the condition is true, or false, respectively.
- The parent statement creates or inherits (from its parent
or sibling) these destination goto labels
- They have to get passed down into boolean subexpressions
- Options for inherited attributes:
- Allocate them ahead of time and pass them down in
an extra tree-traversal before code generation, OR
- Go back into E.code afterwards and fill them in after the
information becomes known! For
that you'll have to remember/store/track spots where such labels
are missing. This implies more attributes and/or auxiliary structures.
Comparing Regular and Short Circuit Control Flow
Different languages have different semantics for booleans.
- Pascal and similar languages treat them similar to arithmetic operators.
- allocate a temporary variable to store E.place at each tree node
where a new boolean value is computed.
- compute a true or a false result into an E.place.
- The .code of the statement using the result inserts, after the E.code, a
gen(BNIF, E.place, E.false) to skip over a then-part
for an if with no else, or
gen(BIF, E.place, E.true) || gen(GOTO, E.false)
for an if with an else.
- C (and C++, and many others) specify "short-circuit"
evaluation in which operands are not evaluated once the answer to
the boolean result is known.
- add extra attributes to keep track of code locations that are
targets of jumps. The attributes store link lists of those instructions
that are targets to backpatch once a destination label is known.
Boolean expressions' results evaluate to jump instructions and program
counter values (where you get to in the code implies what the boolean
expression results were).
- at each level you have a .true target and a .false target.
- naive version may have many unnecessary goto instructions and
extra labels. This is OK in CS 445. Optimizer can simplify.
- Some ("kitchen-sink" design) languages have both
short circuit and non-short-circuit boolean operators!
(Can you name a language that has both?)
- Extra for experts: only the coolest languages utilize a
Kobayashi Maru solution: change the machine
instruction semantics to implicitly route
control from expression failure to the appropriate location. In
order to do this one might
- mark boundaries of code in which failure propagates
- maintain a stack of such marked "expression frames"
Boolean Expression Example
a<b || c<d && e<f
Compare three intermediate code solutions given below.
- The left uses the intermediate code presented earlier.
- The middle uses some new three address instructions. Is it cheating?
- Both left and middle end with E.place in t5 which must
then be tested/used in some conditional branch to do control flow.
- The right side uses short-circuits as per C/C++
| conditional branches | relop instructions | short circuit
|
|---|
100: if a<b goto 103
t1 = 0
goto 104
103: t1 = 1
104: if c<d goto 107
t2 = 0
goto 108
107: t2 = 1
108: if e<f goto 111
t3 = 0
goto 112
111: t3 = 1
112: t4 = t2 AND t3
t5 = t1 OR t4
|
t1 := a LT b
t2 := c LT d
t3 := e LT f
t4 := t2 AND t3
t5 := t1 OR t4
|
if a<b goto E.true
if c<d goto L1
goto E.false
L1: if e<f goto E.true
goto E.false
|
Short circuit semantics is short, fast, and can be used to play parlor tricks.
Q: do we know enough now to write the code generation rules for booleans?
| C syntax | Attribute Manipulations
|
| E->E1 && E2
|
E2.first = newlabel();
E1.true = E2.first;
E1.false = E.false;
E2.true = E.true;
E2.false = E.false;
E.code = E1.code || gen(LABEL, E2.first) || E2.code;
|
| E->E1 || E2
|
E2.first = newlabel();
E1.true = E.true;
E1.false = E2.first;
E2.true = E.true;
E2.false = E.false;
E.code = E1.code || gen(LABEL, E2.first) || E2.code;
|
| E->! E1
|
E1.true = E.false
E1.false = E.true
E.code = E1.code
|
| E -> x
|
gen(BIF, E.false, x.place, con:0) ||
gen(GOTO, E.true)
|
Hints: parent fill's out childrens' inherited attributes...
lecture #40 began here
Mailbag
-
I understand for hw 5 we are supposed to do intermediate code
generation. And I sorta understand that we are supposed to get label points
added at key places in our tree as semantic properties for the next
step. What I don't understand is what I will be doing in more detail. For c
what should this be looking like.
- Tree traversals that compute more attributes.
A lot of small do-able pieces of work that will be combined.
Steps to intermediate code generation include:
- Before you generate any code, implement and test the building blocks:
- Define structs for address (region and offset) and for three-address
intermediate code instructions.
- Build a linked list data type for lists of three-address instructions.
- Write a gen() function to create a linked list of length one, containing
a single 3-address instruction
- Write a copycode(L) function to copy a linked list.
- Write a concatenate function concat(L1, L2) that builds
a new linked list that consists of a copy of L1 followed by L2.
- Write a printcode(L) function that prints a list of code readably.
- Build a counter and a genlabel() function for generating labels
- Extend your symbol tables so that they track sizes of variables
inserted into them, and can report how many bytes the whole table
will need.
- straight line code
- Assign a .place for all treenodes that represent anything with a value
- Allocate temporary variables for all operators/calls.
- Probably need to extend your tree printer so you can see/debug these.
- Generate linked lists of intermediate code instructions for straight
line expressions and statements, with no control flow.
- Generate header/ender pseudoinstructions for procedure main().
- control flow
- Allocate LABEL #'s to all treenodes that can be targets of goto
instructions
- Push LABEL #'s around to where they are needed, through inherited
and/or synthesized attributes via one or more tree traversals
- Need to extend your tree printer so you can see/debug these.
- Generate linked lists of intermediate code for if's and loops.
- Generate linked lists of intermediate code for call (no params) and void return
- Generate linked lists of intermediate code for return values, and parameters.
- Traditionally, % only works on integer arguments.
Do I need to ensure that, or do I need to worry
about modulus for other types?
- % requires integer arguments.
- For structs , how do we size them?
- The size of the instances will be the sum of
the sizes of the member variables (rounding up each variable
to the next 8 byte (machine word) boundary), allocated out of the heap.
The class itself occupies no space. Variables that hold
references to instances are sized as pointers
(8 bytes) in the global or local regions.
- Do I need to give them a region/offset before I create an instance?
My thought is to give them a size, but only assign a region/offset to an
instance of the class. Does this sound right?
- Sure, size yes, location no. In fact, at compile time you can only give
the region/offset of the object reference; the address of the actual object
in the heap is not known until runtime.
- Does the size of a method include the size of the private
members that are declared inside the class but used inside the function?
- VGo is not doing methods. But if we were...
private members are allocated/sized in the instances, not the functions.
The member functions that use
class variables must do so using byte offsets relative to the beginning of an
object reference, and these byte offsets are consistent, for a given instance,
and do not vary depending on which function is called.
-
How do I designate float constants?
-
Most CPU's do not have float immediate instructions. We need an actual
constant region, we need that for string constants too. So create a region
for them, perhaps R_FLOAT and R_STRING, with byte offsets starting at word
boundaries. Or you can have one combined region, perhaps R_RODATA.
Intermediate Code for Relational Operators
- intermediate code can have either
relational operators in conditional branch statements, or
relationals as standalone instructions that compute a
boolean result.
- operands to relationals must be valid (numeric?) type.
- inherited attributes get used here, not pushed down further
to the operands
- You could analyze
whether to generate gotos to E.true/E.false or instead to
generate values that compute a boolean result. Maybe surrounding
code only sets your E.true/E.false to non-NULL if result
should be expressed as gotos?
- You might instead compute a result AND generate gotos. The gotos
might get optimized out if they are not needed.
| C syntax | gotos | bool value | both ?
|
|---|
| E-> E1 < E2
|
E.code = E1.code || E2.code ||
gen(BLT, E1.place, E2.place, E.true) ||
gen(GOTO, E.false)
|
E.place = newtemp()
E.code = E1.code || E2.code ||
gen(LT, E.place, E1.place, E2.place)
|
E.place = newtemp()
E.code = E1.code || E2.code ||
gen(LT, E.place, E1.place, E2.place) ||
gen(BIF, E.place, E.true) ||
gen(GOTO, E.false)
|
Intermediate Code for Loops
While Loops
A while loop has semantic attributes and rules for intermediate code that
are very similar to an if-statement. There is almost only one difference,
the goto back to the beginning. Is there anything else missing or wrong here?
| C syntax | Attribute Manipulations
|
|---|
| S->while '(' E ')' S1 | E.true = newlabel();
E.first = newlabel();
E.false = S.follow;
S1.follow = E.first;
S.code = gen(LABEL, E.first) ||
E.code || gen(LABEL, E.true)||
S1.code ||
gen(GOTO, E.first)
|
Finishing touches: what attributes and/or labels does this plan
need in order to support break and continue
statements?
For Loops
For-loops can be trivially transformed into while loops, so they pose just
about no new code generation issues. Notice that only some expressions
need .true/.false: the ones used as conditionals.
| C syntax | equivalent | Attribute Manipulations
|
|---|
S->for( E1; E2; E3 )
S1
|
E1;
while (E2) {
S1
E3
}
| E2.true = newlabel();
E2.first = newlabel();
E2.false = S.follow;
S1.follow = E3.first;
S.code = E1.code ||
gen(LABEL, E2.first) ||
E2.code || gen(LABEL, E2.true)||
S1.code ||
E3.code ||
gen(GOTO, E2.first)
|
Again: what attributes and/or labels does this plan
need in order to support break and continue
statements?
lecture #41 began here
Homework Status
- As of 1:20 or so this afternoon, 10 students have turned in a HW#4;
this will be my first HW#4 graded batch.
- If you aren't finished with HW#4, you are not alone, and you are graded
relative to your peers. But, please continue working on your project,
and keep me updated. Do not stay stuck for a week at a time. Do not
choose not to get help when needed.
- Discussion of HW#5
Code generation for Switch Statements
Consider the C switch statement
switch(e) of {
case v1:
S1;
case v2:
S2;
...
case vn-1:
Sn-1;
default:
Sn;
}
The intermediate code for this might look like:
code for e, storing result in temp var t
goto Test
L1:
code for S1
L2:
code for S2
...
Ln-1:
code for Sn-1
Ln:
code for Sn
goto Next
Test:
if t=v1 goto L1
if t=v2 goto L2
...
if t=vn-1 goto Ln-1
goto Ln
Next:
|
Note that C "break" statements
are implemented in S1-Sn
by "goto Next" instructions.
|
Intermediate Code Generation Examples
Consider the following small program. It would be fair game as input
to your compiler project. In order to show blow-by-blow what the code
generation process looks like, we need to construct the syntax tree and
do the semantic analysis steps.
| C | Go
|
|---|
void print(int i);
void main()
{
int i;
i = 0;
while (i < 20)
i = i * i + 1;
print(i);
}
|
package main
import "fmt"
func main() {
var i int
i = 0
for i < 20 {
i = i * i + 1
}
fmt.Println(i)
}
|
We proceeded with a discussion of how to build the .code fields.
One thing that got said was: .code fields get built via a post-order
traversal (synthetised attribute) but .true, .false etc. are inherited
and may require a previous pass through the tree, or a pre-order
traversal. If you are trying to do both in one pass it might look like
the following.
lecture #42 began here
Mailbag
- Are you calling functions like they are variables???
- No of course not. And you aren't supposed to be allowing that either.
- Is there any chance I can resubmit for extra points from hw4?
- Yeah, sure.
Discussion of HW#4
- HW#4 grades are pretty rough at present; many/most who submitted in
Batch 1 graded over the weekend will want to correct and resubmit.
- Without going into specifics, because many students haven't submitted
HW#4 yet, there are many different illegal expressions to choose from
that should generate type errors. Everything should be an error until
checked and shown to be OK.
- This is also the time in the semester when my strong sense of deja vu
is starting to make me contemplate running roboflunk on student code
solutions. Reminder: you are allowed to share ideas, but not code.
If you have shared code already, it would be better for you to come
tell me about it than to have me find out due to excessive deja vu.
lecture #43 began here
- Looking at Test case 5 you are trying to Println a float value but we
are not allowed to overload. So, should Println accept float or a string to
avoid overloading?
- So, we danced around the question of how to print numbers before.
Go seems to accept fmt.Println(i) for i being numberic, but
I am trying to avoid making you implement type casts/conversions,
and trying to avoid making you implement function overloading.
itoa(i) and ftoa(f) in VGo
| itoa(i int) string | ftoa(f float64) string
|
|---|
func itoa(i int) string {
if i == 0 { return "0"}
if i == 1 { return "1"}
if i == 2 { return "2"}
if i == 3 { return "3"}
if i == 4 { return "4"}
if i == 5 { return "5"}
if i == 6 { return "6"}
if i == 7 { return "7"}
if i == 8 { return "8"}
if i == 9 { return "9"}
...
}
|
func ftoa(f float64) string {
??
}
|
A Code Generation Function
void codegen(struct tree *t)
{
// pre-order stuff, e.g. label generation
switch (t->prodrule) {
...
case ITERATION_STMT: // inherited attributes for while loop
// push an inherited attribute to child before visiting them
t->child[2]->true = newlabel();
break;
...
}
// visit children
for(i=0; i < t->nkids; i++) codegen(t->child[0]);
// post-order stuff, e.g. code generation
switch (t->prodrule) {
...
case CONDEXPR_2: // synthesized attribs for CondExpr: Expr < Expr
t->code = concat(
t->child[0]->code,
t->child[2]->code,
gen(BLT, t->child[0]->place, t->child[2]->place, t->true),
gen(GOTO, t->false)
);
break;
case ITERATION_STMT: // synthesized attributes for while loop
t->code = concat(
gen(LABEL, t->child[2]->first),
t->child[2]->code,
gen(LABEL, t->child[2]->true),
t->child[4]->code,
gen(GOTO, t->child[2]->first));
break;
}
The code for the boolean conditional expression controlling the while
loop is a list of length 1, containing the instruction t0 = i < 20,
or more formally
| gotos | bool value
|
|---|
| opcode | dest | src1 | src2 |
|---|
| BLT | i | 20 | E.true |
| GOTO | E.false | Ø | Ø |
|
| opcode | dest | src1 | src2 |
|---|
| LT | t0 | i | 20 |
|
The actual C representation of addresses dest, src1, and src2 is a
pair, so the
picture of this intermediate code instruction really looks something like this:
| gotos | bool value
|
|---|
| opcode | dest | src1 | src2 |
|---|
| BLT | local
i.offset | const
20 | code
(E.true's label#) |
|
| opcode | dest | src1 | src2 |
|---|
| LT | local
t0.offset | local
i.offset | const
20 |
|
Regions are expressed with a simple integer encoding like:
global=1, local=2, const=3.
Note that address values in all regions are offsets from the start of the
region, except for region "const", which
stores the actual value of a single integer as its offset.
| opcode | dest | src1 | src2 |
|---|
| MUL | local
t1.offset | local
i.offset | local
i.offset |
The rest of class was spent elaborating on the linked list of instructions
for the preceding example.
.first and .follow for StmtList
- As mentioned previously, attributes
.first and .follow
are an alternative to the "label sandwich" model of code generation
-
.first holds a label denoting the first instruction to execute when
control reaches a given subtree within a function body.
-
.first is a synthesized attribute. Note that unlike
FIRST(a), there is a unique and deterministic label. But worry-warts
might want to ask if a given subtree can have epsilon code.
-
.follow holds a label denoting the instruction that comes after
a given subtree within a function body.
-
.follow would be an inherited attribute, obtained from
some ancestor's sibling.
Suppose you have grammar rules
FuncBody : '{' StatementList '}' ;
StatementList : StatementList Statement ;
StatementList : ;
What kind of .first and .follow values can we
develop and pass in to children from these rules?
| Syntax | Attribute Manipulations
|
|---|
FuncBody : '{' StatementList '}'
| StatementList.follow = newlabel();
FuncBody.code = StatementList.code ||
gen(LABEL,StatementList.follow) ||
gen(RETURN)
|
StatementList1: StatementList2 Statement
| StatementList2.follow = Statement.first;
Statement.follow = StatementList1.follow ||
StatementList1.code = StatementList2.code || Statement.code
|
StatementList : ;
| /* no need for a StatementList.follow */
StatementList.first = newlabel()
StatementList.code = gen(LABEL, StatementList.first) || gen(NOOP)
|
More Code Generation Examples
You should implement your code generation one operator at a time,
simplest expressions first.
Zero operators.
if (x) S
translates into
if x != 0 goto L1
goto L2
label L1
...code for S
label L2
or if you are being fancy
if x == 0 goto L1
...code for S
label L1
I may do this without comment in later examples, to keep them short.
One relational operator.
if (a < b) S
translates into
if a >= b goto L1
...code for S
label L1
One boolean operator.
if (a < b && c > d) S
translates into
if (a < b)
if (c > d)
...code for S
which if we expand it
if a >= b goto L1
if c <= d goto L2
...code for S
label L2
label L1
by mechanical means, we may wind up with lots of labels for the same
target (instruction), this is OK.
Beware the following. A lazy code generator doing short-circuits might be
tempted to say that
if (a < b || c > d) S
translates into
if (a < b) ...code for S
if (c > d) ...code for S
but its unacceptable to duplicate the code for S! It might be huge!
Generate labels for boolean-true=yes-we-do-this-thing, not just for
boolean-false=we-skip-this-thing.
if a < b goto L1
if c > d goto L2
goto L3
label L2
label L1
...code for S
label L3
lecture #44 began here
- Does VGo support this statement : gg=Vertex{15,199}?
- Good question. The VGo references says no map literals,
but indicates by example that object literals are supported.
It also states that the named field initializer syntax
Vertex{Y: 1} is not supported.
- The VGo reference does not have any sizes for types. What are these
sizes or where can I find this information?
- Sizes have been discussed in lectures and some information are in
lecture notes. VGo also defers to Go on all matters unspecified in
the VGo reference, so you could use Go documentation for sizes.
Here is what I remember off-hand
| type | size (bytes)
|
|---|
| bool | 1
|
| rune | 4
|
| int | 8
|
| float64 | 8
|
| Reference Types | variable is size 8 pointer, thing pointed at is:
|
|---|
| array[n] | n * elementsize, round up to a multiple of 8
|
| struct | sum of field sizes, pad field sizes if needed
to a multiple of whatever field size comes next.
|
| func | assembler will take care of code sizes of functions
|
OK, now what have I left out?
Object-Oriented Changes to Above Examples
The previous examples were assuming a C-like language semantics.
For an object-oriented language, the generated code for these examples
is more interesting. For example, the semantics of
if (x) S
if x is an object, may be defaulted to be equivalent to
if (x != NULL) S
or more generally, the different types may have (hardwired, or overrideable)
conversion rules to convert them to booleans for use in tests, such as
tempvar := x.as_boolean()
if (tempvar) S
Code Generation for Arrays
Consider first the subscript operator for C-like arrays. Then
consider how it ought to work in your compiler.
So far, we have only said, if we passed an array as a parameter we'd have to
pass its address. 3-address instructions have an "implicit dereferencing
semantics" which say all addresses' values are fetched / stored by default.
So when you say t1 := x + y, t1 gets values at addresses x and y, not the
addresses. Once we recognize arrays are basically a pointer type, we need
3-address instructions to deal with pointers.
now, what about arrays? reading an array value: x = a[i]. Draw the
picture. Consider the machine uses byte-addressing, not word-addressing.
Unless you are an array of char, you need to multiply the subscript index
by the size of each array element...
t0 := addr a
t1 := i * 8
t2 := plus t0 t1
t3 := deref t2
x := t3
What about writing an array value?
There are similar object-oriented adaptation issues for arrays: a[i]
might not be a simple array reference, it might be a call to
a method, as in
x := a.index(i)
or it might be implemented like:
x := a field i
The main issue to keep straight in both the C-like example and the
object-oriented discussion is: know when an instruction constructs an
address and stores an address in a memory location. When you want to
read or write to the address pointed to by the constructed address,
you may need to do an extra level of pointer-following. Three address
instructions have "implicit" pointer-following since all addresses are
followed when reading or writing memory, but if what is in the address
is another address, you have to be careful to keep that straight.
Supplemental Comments on Code Generation for Arrays
In order to generalize from our example last lecture,
the 3-address instructions for
expr [ expr ]
ideally should generate code that computes an address that can
subsequently be read from or written to. One can certainly write
a three address instruction to compute such an address.
With arrays this is pointer arithmetic.
With tables, the main wrinkle is: what to do
if the key is not in the table? The behavior might be different
for reading a value or writing a value:
| syntax | behavior
|
| t[x] := y | if key is not in table, insert it
|
| y := t[x] | if key is not in table, one of:
- produce a default value
- raise an exception
- ??
|
Code Generation for Maps (Dictionaries, Tables)
Consider the Go map type for a moment.
One can generate code for maps either by extending the three-address
instruction set with new instructions, or by generating function calls.
How might you implement
- map construction: make(map[string]int)
- Needs to allocate one hash table (array of buckets) from the heap.
For compiler, keys were always string. For VGo, keys can be string or int;
maybe two different opcodes/functions, or an argument that specifies this.
For other languages keys might be arbitrary type, adding complexity.
| Via 3-address Instructions | Via function call
|
|---|
MAPCREATE dest
|
CALL mapcreate,?,?
|
- insert: x[s] = s2
- Needs to compute an address into which to store s2.
| Via 3-address Instructions | Via Function call
|
|---|
MAPINSERT map,key,val
|
PARAM map
PARAM key
CALL mapinsert,?,val
|
- lookup: s = x[s2]
-
| Via 3-address Instructions | Via Function call
|
|---|
MAPLOOKUP tmp,map,key
ASN s, tmp
|
PARAM map
PARAM key
CALL maplookup,,tmp
ASN s, tmp
|
Debugging Miscellany
Prior experience suggests if you are having trouble debugging, check:
- makefile .h dependencies!
- if you do not list makefile dependencies for important .h files,
you may get coredumps!
- traversing multiple times by accident?
- at least in my version, I found it easy to accidentally re-traverse
portions of the tree. this usually had a bad effect.
- bad grammar?
- our sample grammar was adapted from good sources, but don't assume its
impossible that it could have a flaw or that you might have messed it up.
- bad tree?
- its entirely possible to build a tree and forget one of your children
A few observations from Dr. D
I went shopping for more intermediate code examples, and while I didn't find
anything as complete as I wanted, I did find updated notes from the same
Jedi Master who trained me, check it:
Dr. Debray's Intermediate Code Generation notes.
You can consider these a recommended supplemental reading material, and we
can scan through them to look and see if they add any wrinkles to our prior
discussion.
A Bit of Skeletal Assistance with Three Address Code
lecture #45 began here
Mailbag
- Do we need to specify the RET instruction at the end of a function
or does the END instruction imply that the function returns?
- I think of END in three-address code as a non-instruction
(pseudo instruction) that marks the end of a procedure. So
you should have a RET in front of it. But really, you are
allowed to define END's semantics to also do a RET; you could
call it REND.
- If we have nothing to return, can we just say RET with no parameter or
must the parameter x always be there, i.e. RET x?
- I would accept a RET with no operand. You are allowed to define new
opcodes in intermediate code. Native assemblers often have several variants
of a given instruction -- same mnemonic, different opcodes for a related
family of instructions.
- Can you give me an example of when to use the GLOBAL and LOCAL
declaration instructions?
- These are pseudo-instructions, not instructions.
Globals are listed as required; at the minimum, if your program has any
global variables you must have at least one GLOBAL declaration to give the
size of (the sum of) the global variables. You can do one big GLOBAL and
reference variables as offsets, or you can declare many GLOBAL regions,
effectively defining one named region for each variable and therefore
rendering the offsets moot.
A LOCAL pseudo-instruction is listed as optional and advisory; think of
it as debugging symbol information, or as an assist to the reader of your
generated assembler source.
- What sort of type checking is needed for a constructor?
(in C++/Java it would be
new)?
- VGo is a special subset of Go. There is always a default constructor
with all zeroes, and a non-default constructor with all fields' values
specified in order, which should be typechecked like a function call.
More generally in other languages,
a constructor has to have # and types of parameters checked.
Its return type is a reference to its operand type, and that type
is type-checked against its enclosing expression, usually an assignment.
Example of Generating .first and .follow Attributes
What nodes need these?
- probably only the statement level nodes.
- they give way to
.true and .false
within (conditional) expressions
- maybe only certain statements, like loops, and
statements that have a preceding statement that
can jump to them instead of just falling through
- ok to just blindly brute force these, as many as you want
- but it would be good to not write them if they aren't used
Call gen_firsts(root) followed by gen_follows(root) before generating code.
.first | .follow
|
|---|
What?
- synthesized attribute
- a label (#) to precede all executable instructions for a given chunk of
code
Why?
- loops may go back to their
.first.
- preceding statements'
.follow may be inherited from your .first
Sample code:
void gen_firsts(nodeptr n)
{
if (n == NULL) return;
for(i=0; inkids; i++)
gen_firsts(n->kids[i]);
switch (n->prodrule) {
case LABELED_STATEMENT:
n->first = /* ... just use the explicit label */
break;
case EXPRESSION_STATEMENT:
case COMPOUND_STATEMENT:
case SELECTION_STATEMENT:
case ITERATION_STATEMENT:
case JUMP_STATEMENT:
case DECLARATION_STATEMENT:
case TRY_BLOCK:
n->first = genlabel();
break;
default:
}
}
|
Why?
- if we skip a then-part or do a then-part and have to skip an else-part
- if we have to break out of a loop
What?
- inherited attribute
- a label to go to whatever comes after the executable instructions for
a given chunk of code.
- Could try to dodge, by blindly generating labels at the end of each
statement ("label sandwich" approach).
void gen_follows(nodeptr n)
{
if (n == NULL) return;
switch (n-<prodrule) {
case STATEMENT_SEQ + 2: /* statement_seq : statement_seq statement */
n->child[0]->follow = n->child[1]->first;
n->child[1]->follow = n->follow;
break;
case COMPOUND_STATEMENT + 1: /* compstmt : '{' statement_seq_opt '}' */
if (n->child[1] != NULL)
n->child[1]->follow = n->follow;
break;
case FUNCTION_DEFINITION + 1: /* funcdef : declarator ctor_init_opt body */
n->child[2]->follow = genlabel();
/* .code must have this label and a return at the end! */
break;
/* ... other cases? ... */
default:
}
for(i=0; i<n->nkids; i++)
gen_follows(n->kids[i]);
}
|
Labels for break and continue Statements
- As shown above, label generation of
.first and .follow isn't difficult
- propagating that information way down
into the subtrees where it is needed, across many nodes where it
is not needed, and not messing up on nested loops, can be a challenge.
- Option #1: add inherited attributes .loopfirst and
.loopfollow to the treenodes. Use them to pass a loop's
.first and .follow
down into the "break" and "continue" statements that
need them:
- Option #2: write a specialized tree traversal whose first parameter is the
tree (node) we are traversing, and whose second and third parameters
are pointers to the label (struct address) of the nearest enclosing
loop. It would be called as
do_break(root, NULL, NULL);
- Option #3: implement parent pointers within all the nodes of your
tree, and walk up the parents until you find a loop node.
Sample code for Option #2 is given below. Implied by the BREAK case is
the notion that the .place field for this node type will hold the label
that is the target of its GOTO. How would you generalize it to
handle other loop types, and the continue statement?
There may be LOTS of different production rules for which
you do something interesting, so you may add a lot of cases to this
switch statement.
void do_break(nodeptr n, address *loopfirst, address *loopfollow)
{
switch (n->prodrule) {
case BREAK:
if (loopfollow != NULL)
n->place = *loopfollow;
else semanticerror("break with no enclosing loop", n);
break;
case WHILE_LOOP:
loopfirst = &(n->first);
loopfollow = &(n->follow);
break;
...
}
for(i=0; i<n->nkids; i++)
do_break(nodeptr n, loopfirst, loopfollow);
}
TAC or die trying
We need a simple example, in which you see
- Systematic traversal to populate explicit symbol table
- Systematic traversal to assign .place (populate implicit symbols)
- Systematic traversal to assign
.first/.follow/.true/.false
- Finally, build linked list of TAC instructions (.code)
It is easy to spend too much class time on
front-end stuff before getting to a too-short and still under-explored
TAC code generation phase. Our Goal:
- manage a slightly larger ("interesting") example
- with syntax and semantic analysis already done
- for which we can go more blow by blow through the intermediate code
generation.
The perfect example would include a few statements, expressions,
control flow constructs, and function calls. Here is an such an
example. Notes for this exercise:
- We will look at a C example. Compare this with the
corresponding VGo example. Qualitatively, what is the difference?
- We will just generate the body for function main().
See if you can generate TAC code for the other functions,
and ask questions.
- we are again trying hard to use a syntax tree, not a
parse tree, i.e. generally, no internal nodes with only one child.
- We omit from the tree, tokens that are simply punctuation
and reserved words needed for syntax.
- Also as stated previously, in real life you
might not want to remove every unary tree node, some of them
have associated semantics or code to be generated, or may help
provide needed context in your tree traversal.
| C version | pseudo-VGo version
|
|---|
void printf(char *, int);
int fib(int i);
int readline(char a[]);
int atoi(char a[]);
int main() {
char s[64];
int i;
while (readline(s)!=0 && s[0]!='\004') {
i = atoi(s);
if (i <= 0) break;
printf("%d\n", fib(i));
}
}
|
func fib(int i) int {
if n <= 1 { return 1 }
else { return fib(n-1) + fib(n-2) }
}
func ctoi(string s) int {
if s == "0" {return 0}
else if s == "1" {return 1}
else if s == "2" {return 2}
else if s == "3" {return 3}
else if s == "4" {return 4}
else if s == "5" {return 5}
else if s == "6" {return 6}
else if s == "7" {return 7}
else if s == "8" {return 8}
else if s == "9" {return 9}
}
func atoi(string s) int {
var i int
for ... /* while (#s > 0) */ {
//?? string c = s[1]
//?? i = i * 10 + ctoi(c)
//?? s = s[2:0]
}
return i
}
func itoa(i int) string {
var s string
var div, rem int
if i == 0 { return "0" }
else if i == 1 { return "1" }
else if i == 2 { return "2" }
else if i == 3 { return "3" }
else if i == 4 { return "4" }
else if i == 5 { return "5" }
else if i == 6 { return "6" }
else if i == 7 { return "7" }
else if i == 8 { return "8" }
else if i == 9 { return "9" }
else if i < 0 { return "-" + itoa(-i) }
else {
div = i / 10
rem = i % 10
return itoa(div) + itoa(rem)
}
}
func main() {
var s string
var i int
for ... {
i = atoi(s)
if i <= 0 { break }
fmt.Println(itoa(fib(i)))
}
}
|
string ftoa(double d)
{
if (d == 0.0) {
return "0.0"
}
else if (d < 0.0) {
return "-real"
}
else {
return "real"
}
}
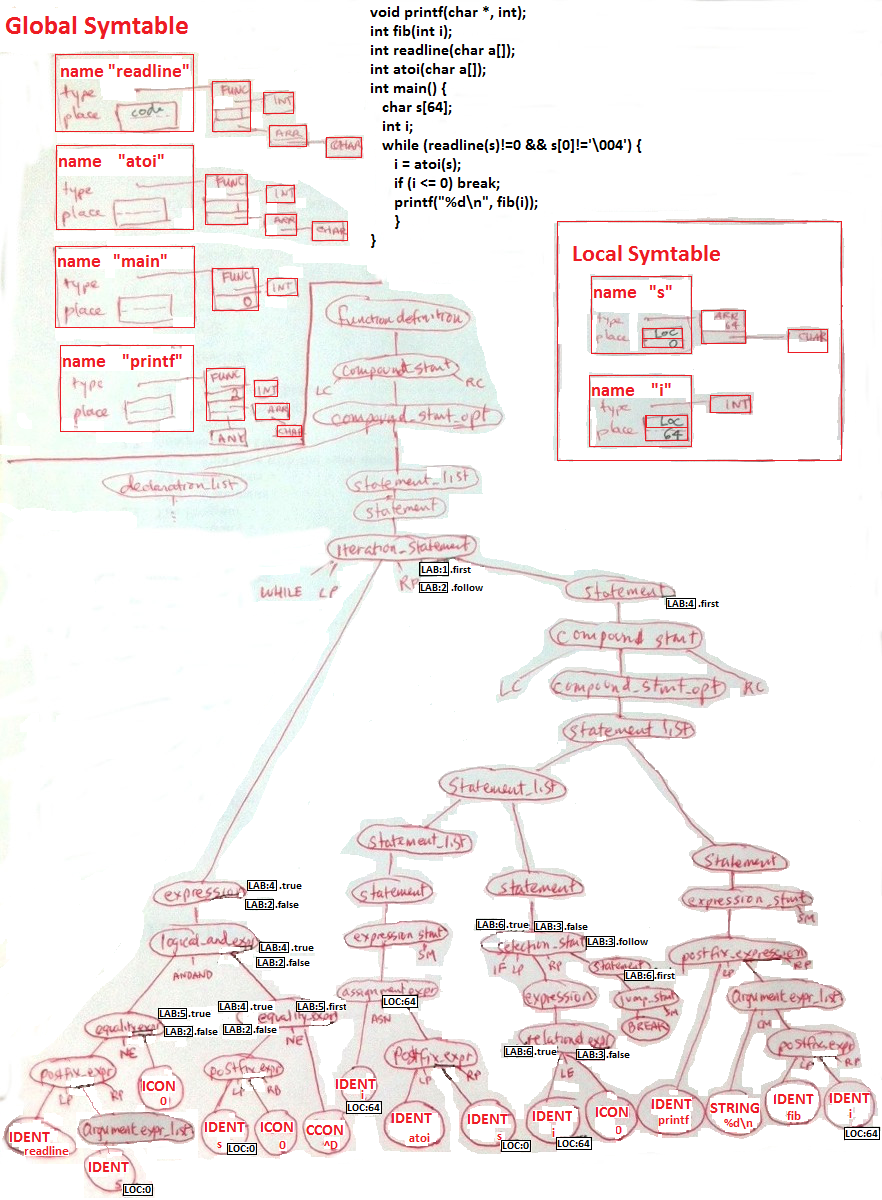
Using cgram.y nonterminal names, let's focus on
code generation for the main procedure.
TAC-or-die: the First-level
Potentially, this is a separate pass after labels have been generated.
|
|
The first tree node that TAC code hits in its bottom up traversal is
IDENTreadline (no .code), followed by IDENTs (no .code).
Above the IDENTs, argument_expression_list is one of those
non-terminals-with-only-one-child that matters and needs to be in the tree:
each time it churns out an actual parameter,
TAC code generates a PARAM instruction to copy the value of the parameter
into the parameter region. PARAM indicates an 8-byte (word) parameter;
you might also want to define PARAM4, PARAM2, PARAM1 (etc.) instructions.
Q: why is the ADDR instruction here?
ADDR loc:72,loc:0
PARAM loc:72
The postfix_expr is a function call, whose TAC codegen rule should say:
allocate a temporary variable t0 (or as we called it: LOC:80)
for the return value, and generate a CALL instruction
CALL readline,1,loc:80
The next leaf (ICON0) has no .code, which brings code generation
up to the != operator. Here the code depends on
the .true (L5) and .false (L2) labels. The TAC code generated is
BNE loc:80,const:0,lab:5
GOTO lab:2
After that, the postfix traversal works over to IDENTs (no .code),
ICON0 (no .code), and up to the postfix expression for the subscript
operator for s[0]. It needs to generate .code that will place
into a temporary variable (its .place, loc:88) what s[0] is.
The basic expression for a[i] is baseaddr + index * sizeof(element).
sizeof(element) is 1 in this case, so we can
just add baseaddr + index. And index is 0 in this case, so an optimizer
would make it all go away. But we aren't optimizing by default, we are
trying to solve the general case. Calling temp = newtemp() we get a new
location (loc:96) to store index * sizeof(element)
MUL loc:96,const:0,const:1
We want to then add that to the base address, but
ADD loc:104,loc:0,loc:96
would add the (word) contents of s[0-7]. Instead, we need
ADDR loc:104,loc:0
ADD loc:104,loc:104,loc:96
After all this, loc:104 contains...the address we want to use.
DEREF1 loc:112,loc:104
fetches (into word at loc:112) the value of s[0].
A label L5 needs to be prefixed into the front of this:
LABEL lab:5
|
Note: an alternative to ADDR would be to define opcodes for reading and
writing arrays. For example
SUBSC1 dest,base,index
might be defined to read from base[index] and store the result in dest.
Similar opcodes for ASNSUB1, SUBSC8, and ASNSUB8 could be added that
assign to base[index], and to perform these operations for 8-byte elements.
Even if you do this, you may need the more general ADDR instruction for
arrays of arbitrary sized elements.
CCON^D has no .code, but the != operator has
to generate code to jump to its .true (L4) or .false (L2) as in the previous
case. Question: do we need to have a separate TAC instruction for
char compares, or sign-extend these operands, or what? I vote: separate
opcode for byte operations. BNEC is a "branch if not-equal characters"
instruction.
BNEC loc:112,const:4,lab:4
GOTO lab:2
The code for the entire local_and_expr is concatenated from its children:
ADDR loc:72,loc:0
PARAM loc:72
CALL readline,1,loc:80
BNE loc:80,const:0,lab:5
GOTO lab:2
LABEL lab:5
MUL loc:96,const:0,const:1
ADDR loc:104,loc:0
ADD loc:104,loc:104,loc:96
DEREF loc:112,loc:104
BNEC loc:112,const:4,lab:4
GOTO lab:2
Tree traversal then moves over into the body of the while loop: its statements.
IDENTi has no .code. The code for atoi(s) looks
almost identical to that for readline(s). The assignment to i tacks on
one more instruction:
ADDR loc:120,loc:0
PARAM loc:120
CALL atoi,1,loc:128
ASN loc:64,loc:128
For the second statement in the while loop, the IF statement, there is
the usual conditional-followed-by-unconditional branch, the interesting
part is where they go. The E.true should do the then-part (the break
statement) for which we generate a .first of lab:6. The E.false should
go for whatever instruction follows the if-statement, for which lab:3
has been designated.
BLE loc:64,const:0,lab:6
GOTO lab:3
The then-part is a break statement. All then-parts will need to have a
label for their .first instruction, which in this case is a trivial GOTO,
but where does it go?
LABEL lab:6
GOTO ??
The break is a major non-local goto that even
the parent node (the if-statement) cannot know the target for, without
obtaining it from about 7 tree-nodes higher! The iteration_statement's
.follow (lab:2) is the target for break (its
.first would be the target for continue).
Dr. J has Doubts About 64-bit Ints
- Last lecture I pointed out that I had edited the example we are
working right now, to account for ints being 64-bit instead of 32-bit.
- It is reasonable to ask whether this is a Bad Idea.
- Pros: if (almost) everything is 64-bits, does that keep things simpler?
- Cons: if our ints are not the same size as g++ ints, how will that
affect us?
Back to the TAC-or-die example
So by one of options #1-3, we find the nearest enclosing iteration_statement's
.follow field says LAB:2. Note that since we have here a label target that
is itself a GOTO, an optimizer would chase back to the branch instructions
that go to label 6, and have them go to label 2, allowing us to remove this
instruction. By the way, if there were an else statement, the
code generation for the then-part would include another GOTO (to skip over
the else-part) that we'd hopefully remove in optimization.
LABEL lab:6
GOTO lab:2
Having completed the then part, it is time to assemble the entire
if-statement:
BLE loc:64,const:0,lab:6
GOTO lab:3
LABEL lab:6
GOTO lab:2
LABEL lab:3
The next statement is a printf statement. We need to push the parameters
onto the stack and execute a call instruction. The code will be: code
to evaluate the parameters (which are non-empty this time), code to push
parameters (in the correct order, from their .place values),
then the call. Question: does it matter whether the evaluations
all occur before the PARAM instructions, or could they (should they) be
interleaved? Answer: in C++ evaluations must all occur before the
PARAM instructions, all PARAM instructions for a call come after the
code for evaluating those arguments, IN REVERSE ORDER, and right
before the CALL instruction.
The code for parameter 1 is empty; its string address will be
pushed onto the stack when we get to that part.
Here is the code for parameter 2,
storing the return value in a new temporary variable.
PARAM loc:64
CALL fib,1,loc:136
The code for the outer call is then
PARAM loc:64
CALL fib,1,loc:136
PARAM loc:136
PARAM sconst:0
CALL printf,2,loc:144
Given this, whole while-loop's code can finally be assembled. The while
prepends a label and appends a GOTO back to the while loop's .first field.
The whole function's body is just this while loop, with a procedure
header and a return statement at the end:
proc main,0,128
LABEL lab:1
ADDR loc:72,loc:0
PARAM loc:72
CALL readline,1,loc:80
BNE loc:80,const:0,lab:5
GOTO lab:2
LABEL lab:5
MUL loc:96,const:0,const:1
ADDR loc:104,loc:0
ADD loc:104,loc:104,loc:96
DEREF loc:112,loc:104
BNEC loc:112,const:4,lab:4
GOTO lab:2
ADDR loc:120,loc:0
PARAM loc:120
CALL atoi,1,loc:128
ASN loc:64,loc:128
BLE loc:64,const:0,lab:6
GOTO lab:3
LABEL lab:6
GOTO lab:2
LABEL lab:3
PARAM loc:64
CALL fib,1,loc:136
PARAM loc:136
PARAM sconst:0
CALL printf,2,loc:144
GOTO lab:1
LABEL lab:2
RETURN
Intermediate Code Generation for Structs, Classes and OO
- CodeGen for structs/classes depends a lot on the language semantics.
- Lecture notes with ideas relevant to Java, ActionScript, or Unicon
may not do things identically to what a C++ subset needs.
- For a new language, we are needing to invent some stuff.
- Maybe some new 3 address opcodes/instructions, for example.
- Next section was for a C++ subset. For each bit, ask how is our
target language different?
- More general OO considerations deferred to later
Consider the following simplest possible OO class example program:
class pet {
int happy
pet() { happy = 50 }
void play() {
write("Woof!\n")
happy += 5
}
}
int main()
{
pet pet1
pet1.play()
return 0
}
What are the code generation issues?
Did we get:
- allocation
- initialization via constructor
- method calling
- member variable referencing
For what its worth, one VGo test case is basically a hand-translation of
this into VGo using a struct.
Object Allocation
- memory allocation of an object is similar to other types.
- it can be in the global, local (stack-relative) or heap area
- the # of bytes (size) of the object must be computed from the class.
- each symbol table should track the size of its members
- for a global or local object, add its byte-count size requirement
to its containing symbol table / region.
- effectively, no separate code generation for allocation
- translate a "new" expression into a malloc() call...
- plus for all types of object creation, a constructor
function call has to happen.
Initialization via Constructor
- A major difference between objects and, say, integers, is that
objects have constructors.
- Constructor, like all other member functions, takes a 0th parameter
that is a pointer to the object instance. Could be implemented as
a register variable, similar to %ebp procedure frame pointer.
- For a local, the object variable declaration translates into a
constructor function call that happens at that point in the code body.
Just catenate .code into the linked list.
- For a "new" object, the constructor function call happens right after
the (successful) call to allocate the object.
- For a global, how do we generate code for its constructor call?
When does it execute? ... Good news, everyone! 120++ almost
does not support globals at all, and only has integer globals.
Method Invocation
Now let's discuss how to generate code for
o.f(arg1,...,argN)
- In C++ it's just a method invocation.
-
When o's class C is known at compile time and methods are non-virtual,
You can generate
C__f(&o, arg1, ..., argN).
- Note the flip side of this: when you generate code for the member
function body, you do the same name mangling, and add the same extra
one-word "this" parameter to the symbol table.
Member variable references
- inside a member function, i.e. access member variable x.
- Handle like with arrays, by allocating a new temporary variable
in which to calculate the address of this->x. Take the address
in the "this" variable and add in x's offset as given in the
symbol table for this's class.
- outside an object, o.x.
- Handle as above, using o's address instead of this's.
You would also check o's class to make sure x is public.
Code Generation for Dynamic OO Languages
-
In a "really" OO language, for o.f(...) you'd do semantic analysis to know
whether f is a method of o's class, or a member variable that happens
to hold a function pointer
- What if f is a method that C inherits from some superclass S?
- What if o's class not known at compiled time and/or methods
are virtual. You have to calculate at runtime which method f to use for o.
What are your options???
Your brilliant suggestions should have included: insert function pointers
for all methods into the instance.
Now let's consider a simple real-world-ish
example. Class TextField, a small, simple GUI widget. A typical
GUI application might have many textfields on each of many dialogs; many
instances of this class will be needed.
The source code for TextField
is only 767 lines long, with 17 member variables and 47 member functions.
But it is a subclass of class Component, which is a subclass of three other
classes...by the time inheritance is resolved, we have 44 member variables,
and 149 member functions. If we include function pointers for all methods
in the instance, 77% of instance variable slots will be these function
pointers, and these 77% of the slots will be identical/copied for all
instances of that class.
The logical thing to do is to share a single copy of the function pointers,
either in a "class object" that is an instance of a meta-class, or more
minimally, in a struct or array of function pointers that might be
called (by some) a methods vector.
Methods Vectors
Suppose you have class A with methods f(), g(), and h(), and class B
with methods e(), f(), and g(). Suppose further that you have code
that calls method f(), that is designed to work either either A or B.
This might happen due to polymorphism, interfaces, subclassing, virtual
methods, etc. The kicker will be that in order to generate code for
o.f(), a runtime lookup will be performed to obtain
the function/method pointer associated with symbol f.
Instead a separate structure (the "methods vector") is allocated and
shared by all the instances of a given class. In this case, o.f()
becomes o.__methods__.f(o)
lecture #46 began here
Mailbag
- What if my program has three functions, each with a local variable to
declare?
- Each function's "local region" is allocated uniquely each time they
are called. Each of your functions' local regions starts at offset 0
so all three local variables might say LOC:0 for local region offset
zero. And yet, they never refer to the same memory, because they are
always offsets relative to some base pointer register on the stack.
- When do I allocate my labels? When do I use them?
- You allocate them in one or more tree traversals prior to starting
the main traversal that generates the linked lists of 3-address code.
Most labels are allocated very close to where they are used.
You use labels by generating pseudo-instructions in the linked list AND
by filling in the target addresses used by goto instructions with LAB:#N
for label number N.
- What do I have to do to get a "D"?
- You are graded relative to your peers. In previous semesters the
answer to this has been something like: pass the midterm and final, and
convince me that you really did semantic analysis. If you did poorly on the
midterm, you might want to try and do better on the final, and you might
want to get some three address code working. Do you really want to settle
for a "D"? Almost everyone who was "D" material dropped the class already.
- I am confused about how to access class members via the "this"
pointer. I am unsure how to do the offsets from the "this" pointer in
three address code without creating a new symbol table for class instances.
- An object instance is like its own little memory region.
The
this pointer is a parameter; offsets relative to
what it points at are done via pointer arithmetic. Each class
should indeed have a symbol table for its member variables' offsets.
- Do you have an example that uses each of the pseudo instructions
(global, proc, local, label, and end), so we
know how these should be formatted?
- No. The pseudo instructions should have opcodes and three address
fields; their presence in the linked list of three address codes is the
same as an instruction. Their format when you print them out is not very
important since this is just intermediate code. But:
instructions are on a single line that begins with a tab character, and
pseudo instructions are on a single line that does not begin with a tab
character.
- We have const that can hold an int/(int)char/boolean, a string region
for holding a string offset, but what should we do about double const
values?
- Real number constants have to be allocated space similar to other types.
They could either be allocated out of a separate "real number constant
region", or the constants of different types could all be allocated out of
the same region, with different offsets and sizes as needed. Note that
not all integer constants fit in instructions, so potentially
some of them may have to be allocated as static data also.
Where we are at
Schedule-wise, it says it is time to move lectures on into the area of
final code generation. We have a new wrinkle there this year, and need
to allow some time for it. But, intermediate code generators are not
due yet, and questions about that are still totally fair game.
One More Intermediate Code Example, with Feeling
I glossed over the "TAC or die trying" example in the last lecture;
it felt redundant for me since we did an earlier example that
was similar. However, one or more of you have requested another
intermediate code generation example.
Yeah, we'll do one alright; this week. But it will take a bit more
preparation, so: not today. This weekend I spent a fair bit digging into
another code generation topic, namely LLVM, and we will also be talking
about that.
Final Code Generation
- Goal: execute the program we have been translating, somehow.
- Note: in real life we would execute a major optimization phase
on the intermediate code, before generating final code.
Alternatives for Final Code:
- interpret the source code
- we could build an interpreter instead of a compiler, in which the
source code was kept in string or token form, and re-parsed, possibly
repeatedly, during execution. Some early BASIC's and operating system
shell scripting languages do this, but it is Really Slow.
- interpret the parse tree
- we could write an interpreter that executes the program
by walking around on the tree doing traversals of various subtrees.
This is still slow, but successfully used by many "scripting languages".
- interpret the 3-address code
- we could interpret the link-list or a more compact binary representation
of the intermediate code
- translate into VM instructions
- popular virtual machines such as JVM or .Net allow execution from an
instruction set that is often higher level than hardware, may be
independent of the underlying hardware, and may be oriented toward
supporting the specific language features of the source language.
For example, there are various BASIC virtual machines out there.
- translate into "native" instructions
- "native" generally means hardware instructions.
For practical purposes, we will consider only two of these options
- translate into VM assembler for the LLVM IR, or
- translate into native x86_64
Introduction to LLVM
LLVM, low-level virtual machine, is a compiler back-end developed by Apple.
Compared with Java VM it is arguably lower level, and it provides a human
readable assembler format that the Java folks have avoided. For a
compiler writer, it provides a way to translate to a machine independent
3-address instruction set and still obtain a highly optimized native
executable on various platforms. LLVM intermediate representation looks
like this:
@.str = private constant [12 x i8] c"Hello llvm!\00", align 1 ;
define i32 @main() ssp {
entry:
%retval = alloca i32
%0 = alloca i32
%"alloca point" = bitcast i32 0 to i32
%1 = call i32 @puts(i8* getelementptr inbounds ([12 x i8]* @.str, i64 0, i64 0))
store i32 0, i32* %0, align 4
%2 = load i32* %0, align 4
store i32 %2, i32* %retval, align 4
br label %return
return:
%retval1 = load i32* %retval
ret i32 %retval1
}
declare i32 @puts(i8*)
Human-readable LLVM IR is translated from a .ll extension into
a binary version with the extension .bc. .bc files can be
translated into native assembler code by llc, and then assembled and linked.
For example, if the above file were in a file named hello.ll, the following
sequence would produce an executable:
llvm-as hello.ll
llc hello.bc
as hello.s -o hello.o
gcc hello.o -o hello
To study LLVM further we should take a look at how to translate our various
three-address intermediate instructions into it, and take a look at its
instruction set. We will explore these topics as time allows.
Native Code Generation
In mainstream compilers, final code generation into native code
- takes a linear sequence of 3-address intermediate
code instructions, and
- translates each 3-address instruction into one or
more native instructions.
The big issues in code generation are:
- (a) instruction selection, and
- (b) register allocation and assignment.
# of Registers Clarification
- numbers quoted last lecture were for "completely undesignated"
general purpose registers
- 32-bit x86 really has eight (8) general purpose registers although
some are typically used for specific purposes suggested by their name:
(eax, ecx, edx, ebx, esp, ebp, esi, edi)
- 64-bit AMD64 (a.k.a. x86-64) has sixteen (16) registers:
rax, rcx, rdx, rbx, rsp, rbp, rsi, rdi, r8, r9, r10, r11, r12, r13, r14, r15
- DEC VAX had 32 registers
- ARM (hello, smartphones) has 8, or maybe 13
- other RISC systems often have 32 or more;
Sun SPARC has 192 registers accessed
via a sliding register window
Code Generation for High Level Structure Types
This discussion applies to maps/dictionaries/tables as we as high-level
sequential (list) types that are dynamic, in contrast with arrays.
- What we have said so far is that you could define new opcodes
for such operators (raising the language level of your
intermediate code), or implement them as function calls.
- Either way, we will (by final code generation) need an
implementation of this functionality, that your code can
link in and use. You could write your own, or ask me to
provide this as a set of runtime functions in C.
Lists:
| operation | as opcode | as function
|
|---|
| L1 L2 | LCONCAT t,L1,L2 | t = lconcat(L1,L2)
|
| L1 += L2 | LAPPEND L1,L2 | lappend(L1,L2)
|
| L1 += x | LPUT L1,x | lput(L1,x)
|
| L[i] | LINDEX t,L,i | t = lindex(L,i)
|
| L[i:j] | LSLICE t,L,i,j
no good, 4 addrs | t = lslice(L,i,j)
|
| #L | LSIZE t,L | t = lsize(L)
|
| t = list() | LIST t,n,m | t = list(n,m)
|
Tables:
| operation | as opcode | as function
|
|---|
| T[a] | TINDEX t,T,a | t = tindex(T,a)
|
| T[]=a | TDEFAULT T,a | tdefault(T,a)
|
| T -= a | TDELETE T,a | tdelete(T,a)
|
| #T | TSIZE t,T | t = tsize(T)
|
| t = table() | TABLE t,m | t = table(m)
|
Collecting Information Necessary for Final Code Generation
- Option #A: a top-down approach to learning your native target code.
-
Study a reference work supplied by the chip manufacturer, such
as the
AMD64 Architecture Programmer's Manual
(Vol. 2,
Vol. 3).
- Option #B: a bottom-up (or reverse engineering)
approach to learning your native target code.
-
study an existing compiler's native code. For example, run
"g++ -S" for various toy programs
to learn native instructions corresponding to each expression,
particularly ones equivalent to the various 3-address instructions.
lecture #47 began here
Mailbag
- Do the linked lists of code really just get concatenated in order
until the entire program is one big linked list?
Does main() have to be at the beginning in generated code?
-
Not really, and not really. It is recommended that you build one
big linked list for the generated code, but I am a pragmatist; do
what makes sense to you to generate all the code. In real native
OS'es, the code at the beginning of the executable is not main, it
is some weird startup boostrapper that sets up environment and
command line arguments and then calls main(). So no, main() does not
have to be at the top, unless maybe you are building an image
for an embedded system that doesn't have an OS or something like that.
- How do I represent function names in addresses in 3 address code?
- One option is to totally dodge, and generate code for one function
at a time, at a place where you know the function name. If you
choose instead to build one big linked list,
function "names" get boiled down to code region addresses. So far
we have one kind of address in the code region: labels.
You could literally generate label #'s for these things, but function
names are more human-friendly. Unless you turn function names into
labels, you should create a new region (call it PROCNAME). You could make the "offset" field in
your 3 addresses a union
struct addr {
int region; // if PROCNAME, use u.s instead of u.i
union {
int offset;
char *s;
} u;
}
You could, instead, make an array of string funcnames in your compiler
and have your region PROCNAME provide offsets that are subscripts into
this array of funcnames.
- I am having a hard time understanding how everything will be put
together in the end, will it be one linked list once all the instructions
are concatenated? How should we handle assigning locations to functions like
Println? Once we see import "fmt" should we go to that symbol table and
assign locations to those functions then?
- Library functions like Println require that we store enough information
to call them, but not that we store information to generate code for them.
fmt should have an associated symbol table entry for Println which should
know that Println takes a string argument. Code for a call to fmt.Println
should mangle that name out to something like fmt__Println.
- can we just define a function without parameters as call, so
main is equivalent to main() if not followed
by parentheses?
- Do not confuse type (reference to) FUNCTION with
the function's return type, which is the result of a call (postfix parentheses
operator).
A New Fun Intermediate CodeGen Example
This example is not burdened with redundant practice at generating code
for arithmetic and assignments and such.
package main
import "fmt"
func min(a,b,c int) int {
if a<=b && a<=c {
return a
} else if b<=a && b<=c {
return b
}
return c
}
func main() {
fmt.Println(min(3,6,2))
}
Back to Final Codegen
Instruction Selection
A modern CPU usually has many different sequences of instructions
that it could use to accomplish a given task. Instruction selection
must choose a particular sequence.
- how many registers are tied to particular instructions?
- is a special case instruction available for a particular
computation?
- what addressing mode(s) are supported for a given instruction?
Given a choice among equivalent/alternative sequences, the decision on which
sequence of instructions to use is usually based on estimates or
measurements of which sequence executes the fastest.
- "fastest" is often approximated by the
number of memory references incurred during execution, including the
memory references for the instructions themselves.
- picking the
shortest sequence of instructions is often a good approximation of the
optimal result, since fewer instructions usually translates into fewer
memory references.
A good set of examples of instruction selection are to be
found in the superoptimizer paper. From that paper:
- a longer instruction sequence may be faster if it avoids gotos
- sometimes the fastest sequence exploits specific constants in the
operands and is really, really surprising.
lecture #48 began here
Mailbag
- Can we have more time to do HW#5 and #6
- I will take them when I can get them. Due dates changed to Nov 27
and Dec 13 respectively.
-
I'm having trouble figuring out what TAC I need to generate for a function
definition. For example, given the function
int foo(int x){
...somecode
}
I'm having trouble understanding what code needs to be generated at this
level. I understand that there needs to be (at least) 1 label, at the very
start (to be able to call the function).
- In final code, the procedure entry point
will indeed include a label. In three address code, a function header
should result in a PROC pseudo-instruction for which you create a link
list element, just like everything else.
-
I'm having trouble understanding what code I would create for the int
return, or to define the space available for parameters.
-
The "return type" at the top of a function generates no code, but it may
affect what you generate when you hit a "return" statement in the function
body.
The proc pseudoinstruction includes a declaration of how many
(words of parameters) it requires/assumes has been passed in to a function,
from which space required may be calculated. It most native code the caller
really allocates this space via PARAM instructions; the called function
just decides the amount of
local/temp variable space on the stack that the procedure requires.
So the pseudoinstructions in intermediate code that you use is
something like:
proc foo,1,nbytes_localspace
-
If I understand the return properly, I don't actually generate code at this
(the procedure header return type) node for the return. It gets generated
at the 'return' line in the body.
-
Yes. There and at the end of any function
that falls off the end. In final code the return statement will put a
return value in %eax and then jump
down to the end of the function to use its proper function-return assembler
instruction(s).
-
I guess the .place of
int x is what is really getting me.
Do I really
need to worry about it too much in TAC, because it is just 'local 0' (or
whatever number gets generated)?
-
I recommend you consider it (in TAC) to be region
PARAM offset 0. That could be handled almost identically to locals in final
code, unless you use the fact that parameters are passed in registers...
-
Then I really end up worrying about it during final code since local 0 might
actually be something like %rbp -1 or wherever the location on the stack
parameters end up being located.
-
By saying it is PARAM offset 0, the TAC code for
parameters is distinct enough from locals that they can be found to be at
a different location relative to the %rbp (positive instead of negative)
or passed in registers.
Register Allocation and Assignment
- reading values in registers is much much faster than accessing main memory.
-
Register allocation denotes the selection of which variables
will go into registers.
-
Register assignment is the determination of exactly
which register to place a given variable.
- goal: minimize the total number of memory accesses required
by the program.
The (register allocation) job changes as CPUs change
- In the age of dinosaurs, Load-Store architectures featured
only one (accumulator) register.
Register allocation and assignment was moot.
- In the age of minis and micros, it was usually "easy", e.g.
traditional x86 had 4 registers instead of 1.
- Recent History features CPU's with 32 or more general purpose
registers. On such systems,
high quality compiler register allocation and assignment makes a huge
difference in program execution speed.
- :-( btw, optimal register
allocation and assignment is NP-complete! Compilers must settle for
doing a "good" job.
- usually the # of variables at many given time exceeds the number
of registers available (the common case)
- variables may be used (slowly)
directly from memory IF the instruction set supports
memory-based operations.
-
When an instruction set does not support memory-based operations, all
variables must be loaded into a register in order to perform arithmetic
or logic using them.
Even if an instruction set does support memory-based operations, most
compilers should load a value into a register while it is
being used, and then spill it back out to main memory when the register
is needed for another purpose. The task of minimizing memory accesses
becomes the task of minimizing register loads and spills.
lecture #49 began here
Native Code Generation Examples
Reusing a Register
Consider the statement:
a = a+b+c+d+e+f+g+a+c+e;
A naive three address code generator would generate a
lot of temporary variables here, one per addition operator, when
in actuality one big number is being added.
How many registers does the expression need? Some variables
are referenced once, some twice. GCC (32-bit) generates:
movl b, %eax
addl a, %eax
addl c, %eax
addl d, %eax
addl e, %eax
addl f, %eax
addl g, %eax
addl a, %eax
addl c, %eax
addl e, %eax
movl %eax, a
Now consider
a = (a+b)*(c+d)*(e+f)*(g+a)*(c+e);
How many registers are needed here?
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
imull %eax, %edx
movl f, %eax
addl e, %eax
imull %eax, %edx
movl a, %eax
addl g, %eax
imull %eax, %edx
movl e, %eax
addl c, %eax
imull %edx, %eax
movl %eax, a
And now this:
a = ((a+b)*(c+d))+((e+f)*(g+a))+(c*e);
which compiles to
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
movl %edx, %ecx
imull %eax, %ecx
movl f, %eax
movl e, %edx
addl %eax, %edx
movl a, %eax
addl g, %eax
imull %edx, %eax
leal (%eax,%ecx), %edx
movl c, %eax
imull e, %eax
leal (%eax,%edx), %eax
movl %eax, a
Brief Comparison of 32-bit and 64-bit x86 code
What can be gleaned from this side-by-side of 32-bit and 64-bit assembler
for a=a+b+c+d+e+f+g+a+c+e.
Note that the actual variable names are in the assembler because the variables
in question are globals.
| x86 32-bit
| x86_64
|
movl b, %eax
addl a, %eax
addl c, %eax
addl d, %eax
addl e, %eax
addl f, %eax
addl g, %eax
addl a, %eax
addl c, %eax
addl e, %eax
movl %eax, a
|
movq a(%rip), %rdx
movq b(%rip), %rax
addq %rax, %rdx
movq c(%rip), %rax
addq %rax, %rdx
movq d(%rip), %rax
addq %rax, %rdx
movq e(%rip), %rax
addq %rax, %rdx
movq f(%rip), %rax
addq %rax, %rdx
movq g(%rip), %rax
addq %rax, %rdx
movq a(%rip), %rax
addq %rax, %rdx
movq c(%rip), %rax
addq %rax, %rdx
movq e(%rip), %rax
leaq (%rdx,%rax), %rax
movq %rax, a(%rip)
|
Q: Should we be disappointed that the 64-bit code looks a lot longer?
A: Maybe instead we should be fascinated.
- Looks can be deceiving; x86_64 tends to run a lot faster than x86
- Instruction prefetch on x86_64 is extensive; instructions that use
register operands are short and many may be prefetched together.
- Superscalar architectures can execute multiple instructions in parallel
- The instructions selected here may be specifically maximizing the
superscalar behavior
The globals are declared something like the following.
.comm stands for data in a "common" (a.k.a. global data) section.
.globl and .type are used for functions, and are really part of
the function header before the function code starts.
If you allocated your globals as a region, you might have one .comm of 56
bytes named globals (or whatever) and give the addresses of your globals as
numbers such as globals+32. Names are nicer but having to
treat globals and locals very differently is not.
.comm a,8,8
.comm b,8,8
.comm c,8,8
.comm d,8,8
.comm e,8,8
.comm f,8,8
.comm g,8,8
.text
.globl main
.type main, @function
Brief Comparison of x86-64 globals vs. locals
How does this difference inform, and affect, what we might want in
our three-address code?
| x86_64 local vars
| x86_64 globals (as per last example)
|
movq -48(%rbp), %rax
movq -56(%rbp), %rdx
leaq (%rdx,%rax), %rax
addq -40(%rbp), %rax
addq -32(%rbp), %rax
addq -24(%rbp), %rax
addq -16(%rbp), %rax
addq -8(%rbp), %rax
addq -56(%rbp), %rax
addq -40(%rbp), %rax
addq -24(%rbp), %rax
movq %rax, -56(%rbp)
|
movq a(%rip), %rdx
movq b(%rip), %rax
addq %rax, %rdx
movq c(%rip), %rax
addq %rax, %rdx
movq d(%rip), %rax
addq %rax, %rdx
movq e(%rip), %rax
addq %rax, %rdx
movq f(%rip), %rax
addq %rax, %rdx
movq g(%rip), %rax
addq %rax, %rdx
movq a(%rip), %rax
addq %rax, %rdx
movq c(%rip), %rax
addq %rax, %rdx
movq e(%rip), %rax
leaq (%rdx,%rax), %rax
movq %rax, a(%rip)
|
Parameters
In final code, do parameters look like locals?
Consider the following example. Note that "long" is used to more closely
resemble the g0 "everything is a 64-bit value" mind-set.
#include <stdio.h>
long f(long,long,long);
int main()
{
long rv = f(1, 2, 3);
printf("rv is %d\n", rv);
}
long f(long a, long b, long c)
{
long d, e, f, g;
d = 4; e = 5; f = 6; g = 7;
a = ((a+b)*(c+d))+(((e+f)*(g+a))/(c*e));
return a;
}
for which the generated code was
.file "expr.c"
.section .rodata
.LC0:
.string "rv is %d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $3, %edx
movl $2, %esi
movl $1, %edi
call f
movq %rax, -8(%rbp)
movl $.LC0, %eax
movq -8(%rbp), %rdx
movq %rdx, %rsi
movq %rax, %rdi
movl $0, %eax
call printf
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.globl f
.type f, @function
f:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
pushq %rbx
movq %rdi, -48(%rbp)
movq %rsi, -56(%rbp)
movq %rdx, -64(%rbp)
movq $4, -40(%rbp)
movq $5, -32(%rbp)
movq $6, -24(%rbp)
movq $7, -16(%rbp)
movq -56(%rbp), %rax
movq -48(%rbp), %rdx
leaq (%rdx,%rax), %rcx
movq -40(%rbp), %rax
movq -64(%rbp), %rdx
leaq (%rdx,%rax), %rax
imulq %rax, %rcx
movq -24(%rbp), %rax
movq -32(%rbp), %rdx
leaq (%rdx,%rax), %rbx
.cfi_offset 3, -24
movq -48(%rbp), %rax
movq -16(%rbp), %rdx
leaq (%rdx,%rax), %rax
imulq %rbx, %rax
movq -64(%rbp), %rdx
movq %rdx, %rbx
imulq -32(%rbp), %rbx
movq %rbx, -72(%rbp)
movq %rax, %rdx
sarq $63, %rdx
idivq -72(%rbp)
leaq (%rcx,%rax), %rax
movq %rax, -48(%rbp)
movq -48(%rbp), %rax
popq %rbx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size f, .-f
.ident "GCC: (GNU) 4.4.7 20120313 (Red Hat 4.4.7-3)"
.section .note.GNU-stack,"",@progbits
We learned that (the first 6+) parameters are passed in registers, but
you can allocate local variable space for them, and copy them into
their local space, after which they can be treated exactly like other
locals.
lecture #50 began here
Mailbag
I saw your in your three address code examples of calling a function that
pass array variables that before PARAM, you always put the array
address into a temporary variable.
like:
char s[64];
readline(s)
ADDR loc:68,loc:0
PARAM8 loc:68
CALL readline,1,loc:68
and printf("%d\n", 10+2);
addr loc:0,string:0
parm loc:0
add loc:8,im:10,im:2
parm loc:8
call printf,16,loc:16
So, before passing the variables to the function, do you have to copy
the variables to the temporary variables? And then PARAM the temporay
variables. Or it is only true for passing array address?
I know the PARAM will copy the passing arguments into the called function's
activation record's parameter region. So there is no need copy the parameter
variables into temporary variables then PARAM the temporary variables.
Answer:
The three-address instructions use addresses, but they normally operate by
implicitly fetching and storing values pointed to by those addresses.
The ADDR instruction does not copy the variable into a temporary variable,
it copies the address given, without fetching its contents, into its
destination. This is needed in order to pass an reference parameter.
In Pascal, by default we would have to allocate (on the stack) an entire
physical copy of the whole array in order to pass it as a parameter. This is
potentially very expensive, which is why C-based languages don't do it.
(Q: if you wanted a physical copy of an array to be passed, do you know
some ways to get one?)
Aside on .cfi* assembler directives
- Explanation of
CFI directives
(CFI stands for Call Frame Information)
- Summary: the .cfi* statements are used for
exception handling and you can get rid of them using the gcc flag
-fno-asynchronous-unwind-tables
lecture #51 began here
Creating an object via new
Consider the following C++ example of final code for an object
constructor. Executing the reserved word new from
function main() calls two functions to
create an object in the heap (via new):
- _Znwm
- similar to a
malloc(); it takes an integer parameter
(constant 16, the # of bytes to allocate) and returns a pointer
- _ZN1CC1Ev
- a call to a C++ constructor function, with an implicit/added first
parameter for
this, the object instance that the member
function is working on.
"new" in final code FYI
class C {
private: long x, y;
public: C() { x=3; y=4; }
};
int main()
{
C *a = new C;
}
generates
.file "new.cpp"
.section .text._ZN1CC2Ev,"axG",@progbits,_ZN1CC5Ev,comdat
.align 2
.weak _ZN1CC2Ev
.type _ZN1CC2Ev, @function
_ZN1CC2Ev:
.LFB1:
.cfi_startproc
.cfi_personality 0x3,__gxx_personality_v0
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq %rdi, -8(%rbp)
movq -8(%rbp), %rax
movq $3, (%rax)
movq -8(%rbp), %rax
movq $4, 8(%rax)
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size _ZN1CC2Ev, .-_ZN1CC2Ev
.weak _ZN1CC1Ev
.set _ZN1CC1Ev,_ZN1CC2Ev
.text
.globl main
.type main, @function
main:
.LFB3:
.cfi_startproc
.cfi_personality 0x3,__gxx_personality_v0
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
pushq %rbx
subq $24, %rsp
movl $16, %edi
.cfi_offset 3, -24
call _Znwm
movq %rax, %rbx
movq %rbx, %rax
movq %rax, %rdi
call _ZN1CC1Ev
.L5:
movq %rbx, -24(%rbp)
movl $0, %eax
addq $24, %rsp
popq %rbx
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE3:
.size main, .-main
.ident "GCC: (GNU) 4.4.7 20120313 (Red Hat 4.4.7-3)"
.section .note.GNU-stack,"",@progbits
As you may observe: the final code for a new calls a memory
allocator (nwm) whose return value (%rax) gets copied in as a parameter
(%rdi) to the constructor (N1CC1Ev), with an interesting side trip to %rbx.
On C/C++ Calling Convention and Order of Passed Parameters
In compilers, the calling conventions are the set of rules by which parameters
and return values are communicated between caller and callee. The calling
conventions also cover things like whether the caller or the callee has to
save and restore specific registers as part of the process of call/return.
- a good general discussion is available on Wikipedia
- Each C compiler makes its own rules. We could do what we want unless we
need to be compatible with another compiler to call their library functions,
in which case we have to follow their calling conventions
- In C/C++, parameters are passed in reverse order
- (as we have seen,) in gcc/g++, several parameters are passed in
registers, but generally get allocated local region space and saved there
by callee
- in gcc/g++ the callee explicitly restores stack and old call frame,
the RET instruction doesn't do that magically, it just manages to
restore the program counter register back to the caller.
- In (newer versions of) G++, the parameter section is 16-byte aligned
How this looks and is used inside member functions
- it is the first parameter, so it is passed in %rdi
- g++ seems to reserve local memory space and copy/save the registers
into that local memory space for ALL parameters passed in registers, so
it does that for
this
- it may make it more likely that you run out of registers to pass all your
parameters in, and are passing later regular paramters on the stack.
- references (through
this) to member variables are done using
the "usual" indirect addressing mode, which takes an optional small
constant as a byte offset when reading/writing using a pointer. If the
this pointer is in %rax and our byte offset for a member
variable is 8, then 8(%rax) is the assembler syntax to
read or write to that variable.
About name mangling in C++ vs. your compiler
- C++ has to name mangle because it does function overloading.
- your compiler doesn't have to use the C++ _Znwm, it can call
malloc() for all I care
- your compiler almost doesn't have to name mangle at all, what
is the exception?
lecture #52 began here
End of Semester Planning
- Final Exam Review: Thursday December 12
- Homework #6 due: Friday December 13, 11:59pm
- Final Exam: Tuesday December 17, 3-5pm
- Compiler Demos: by appointment, Dec 16-20
Mailbag
- I am doing LLVM for HW#6 and my LLVM is incompatible with the one on
the grading machine! What do I do?
- You can demo your HW#6 results during finals week on your machine.
Or you can do your HW6 on the grading machine. Or you can do x86_64.
I will take and grade anything you give me on HW#6.
- Has this class been a one long Kobayashi Maru Test?
- Thanks for the pop culture reference! CS 445 is similar to the
Kobayashi Maru in that it may seem unwinnable. It is different than
the Kobayashi Maru in that the goal is not merely to test your character,
but more importantly, to make you gain experience points and go up levels
in programming skill, such that you are ready to work professionally.
More about LEAL
In a previous example, complicated arithmetic drove GCC to start
"leal'ing".
- leal (load effective address) is a complex instruction usually used for
pointer arithmetic, i.e. its output is usually a pointer.
- due to x86 CISC addressing modes, leal can actually add two registers,
multiplying one of those registers by 1, 2, 4, or 8, and then adding
a constant offset in as well. It is a "more than 3 address instruction".
- the instruction selection module of gcc knows it can be used for
addition.
- Unlike "add" instruction, it does not set the condition flag,
- This property might allow it to execute in parallel with some
other arithmetic operation that does use the condition flag.
So sure enough: it (potentially) improves superscalar execution, and
gcc/g++ are smart enough to use it instead of ADD sometimes.
Lastly (for now) consider:
a = ((a+b)*(c+d))+(((e+f)*(g+a))/(c*e));
The division instruction adds new wrinkles. It operates on an implicit
register accumulator which is twice as many bits as the number you divide
by, meaning 64 bits (two registers) to divide by a 32-bit number. Note
in this code that 32-bit gcc would rather spill than use %ebx. %ebx is
reserved by the compiler for some (hopefully good) reason.
%edi and %esi are similarly ignored/not used.
| 32-bit | 64-bit
|
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
movl %edx, %ecx
imull %eax, %ecx
movl f, %eax
movl e, %edx
addl %eax, %edx
movl a, %eax
addl g, %eax
imull %eax, %edx
movl c, %eax
imull e, %eax
movl %eax, -4(%ebp)
movl %edx, %eax
cltd
idivl -4(%ebp)
movl %eax, -4(%ebp)
movl -4(%ebp), %edx
leal (%edx,%ecx), %eax
movl %eax, a
|
pushq %rbx
subq $88, %rsp
movq $1, -72(%rbp)
movq $2, -64(%rbp)
movq $3, -56(%rbp)
movq $4, -48(%rbp)
movq $5, -40(%rbp)
movq $6, -32(%rbp)
movq $7, -24(%rbp)
movq -64(%rbp), %rax
movq -72(%rbp), %rdx
leaq (%rdx,%rax), %rcx
movq -48(%rbp), %rax
movq -56(%rbp), %rdx
leaq (%rdx,%rax), %rax
imulq %rax, %rcx
movq -32(%rbp), %rax
movq -40(%rbp), %rdx
leaq (%rdx,%rax), %rbx
.cfi_offset 3, -24
movq -72(%rbp), %rax
movq -24(%rbp), %rdx
leaq (%rdx,%rax), %rax
imulq %rbx, %rax
movq -56(%rbp), %rdx
movq %rdx, %rbx
imulq -40(%rbp), %rbx
movq %rbx, -88(%rbp)
movq %rax, %rdx
sarq $63, %rdx
idivq -88(%rbp)
leaq (%rcx,%rax), %rax
movq %rax, -72(%rbp)
movl $.LC0, %eax
movq -72(%rbp), %rdx
movq %rdx, %rsi
movq %rax, %rdi
movl $0, %eax
call printf
addq $88, %rsp
popq %rbx
|
In the 32-bit version, you finally see some register spilling.
In the 64-bit version, there is
- saving a register so you can use it (%rbx)
- allocating a whole local region of 88 bytes
- storing immediate values into main memory
- addition by leaq'ing registers
LEAVE instruction
In our example of using new we saw a LEAVE instruction before
the function returned. LEAVE restores the frame pointer
to the caller's value, something like
movq rsp, rbp ; set top of stack back to where caller had it
popq rbp ; set base pointer back to saved value at (%rsp)
Interestingly, there is a corresponding ENTER instruction, but g++ does not
tend to use it because it is slower than corresponding lower-level operations
like subq $nbytes, %rsp.
For what its worth, professor Thain provides a good introduction to
x86_64 assembler, more than our Louden text.
lecture #53 began here
Brief Comment on HW Resubmissions
At various points in this course you have a choice between completing/fixing
a previous homework, or working on the next homework. But sometimes you
have to complete/fix an old homework for the next one to be implementable.
I have been accepting resubmissions this semester, to make corrections,
restoring points up to a "C" grade for a given assignment.
Please test your work prior to each resubmission; I won't be able to
just keep regrading it until it passes.
More on DIV instruction
When I looked for more, I found this
Cheat Sheet, which pointed at the big books
(A-MN-Z).
- The cheat sheet says div divides reg. ax by [src], ratio in ax, remainder in
dx.
- It also says dx must be 0 to start or you get a SIGFPE.
- The big book
says your basic full-size divide instruction divides a big value stored in
a pair of registers (32 bit: EDX:EAX or 64 bit: RDX:RAX), by which point I
am thinking I have to give the general introduction to X86_64 before this
should be remotely understandable.
Helper Function for Managing Registers
Define a getreg() function that returns a location L
to hold the value of x for the assignment
x := y op z
- if y is in a register R that holds the value of no other names,
AND y is not live after the execution of this instruction, THEN
return register R as your location L
- ELSE return an empty register for L if there is one
- ELSE if x has a next use in the block or op is an operator
that requires a register (e.g. indexing), find an occupied
register R. Store R into the proper memory location(s), update
the address descriptor for that location, and return R
- if x is not used in the block, or no suitable occupied register
can be found in (3), return the memory location of x as L.
Putting It All Together: A Simple Code Generator
- Register allocation will be done only within a basic block.
All variables that are live at the end of the block are stored
in memory if not already there.
- Data structures needed:
- Register Descriptor
- Keeps track of what is in each register. Consulted when a new register
is needed. All registers assumed empty at entry to a block.
- Address Descriptors
- Keep track of the location(s) where the current value of a name can be
found at runtime. Locations can be registers, memory addresses, or stack
displacements. (can be kept in the symbol table).
Example
// make an array (12?) of these:
struct regdescrip {
char name[12]; // name to use in codegen, e.g. "%rbx"
int status; // 0=empty, 1=loaded, 2=dirty, 4=live, ...
struct address addr;
};
// upgrade symbol table entry to use these instead of struct address
struct addr_descrip {
int status; // 0=empty, 1=in memory, 2=in register, 3=both
struct reg_descrip *r; // point at an elem in reg array. could use index.
struct address a;
};
Code Generation Algorithm
For each three-address statement of the form
x := y op z:
- Use
getreg() to determine location L where the
result of the computation y op z should be stored.
- Use the address descriptor for y to determine y', a current location for
y. If y is currently in a register, use the register as y'. If y is not already
in L, generate the instruction
MOV y',L to put a copy of y in L.
- Generate the instruction
OP z',L where z' is a current location for z.
Again, prefer a register location if z is currently in a register.
Update the descriptor of x to indicate that it is in L. If L is a register,
update its descriptor to indicate that it contains x. Remove x from all other
register descriptors.
- If y and/or z have no next uses and are in registers, update the register
descriptors to reflect that they no longer contain y and/or z respectively.
Register Allocation
Need to decide:
- which values should be kept in registers (register allocation)
- which register each value should be in (register assignment)
Approaches to Register Allocation
- Partition the register set into groups that are use for different kinds
of values. E.g. assign base addrs to one group, pointers to the stack to
another, etc.
Advantage: simple
Disadvantage: register use may be inefficient
- Keep frequently used values in registers, across block boundaries. E.g.
assign some fixed number of registers to hold the most active values in each
inner loop.
Advantage: simple to implement
Disadvantage: sensitive to # of registers assigned for loop variables.
lecture #54 began here
Challenge Question we Ended with Last Time
So, how can you know what are the frequently used variables in a function?
- Count the number of occurrences in source code? (easy static analysis,
but bad results)
- Do math proofs of the frequency relationships between variables
(hard static analysis)
- Run the program on representative inputs, and count all uses
of variables in that function. (dynamic analysis)
- Make a crude approximation or estimate (easy static analysis)
x86_64 Floating Point
Float Operations
There is
a useful set of notes from Andrew Tolmach of Portland State University.
Arithmetic operations on floats
have different opcodes, and results have to be stored in
floating point registers, not integer registers.
movsd -56(%rbp), %xmm0
movapd %xmm0, %xmm1
addsd -48(%rbp), %xmm1
Float Constants
Doubles are the same 64-bit size as longs. They can be loaded into memory
or registers using the normal instructions like movq. A spectacular x86_64
opcode named movabsq takes an entire floating point constant as an immediate
(bit pattern given as a decimal integer!) and stores it in a register.
(Q: What C code (or library function) would take your double and
produce the equivalent decimal integer string?)
movabsq $4620355447710076109, %rax
movq %rax, -8(%rbp)
Simple Machine Model
This model is probably relevant for selecting between equivalent sequences
of instructions but is presented here as food for thought regarding which
variables deserve to stay in registers.
- Instruction Costs
- for an instruction I, cost(I) = 1 + sum(cost(operands(I)))
operand costs:
- if operand is a register, cost = 0
- if operand is memory, cost = 1
- Usage Counts
- In this model, each reference to a variable x accrues a savings of
1 if x is in a register.
- For each use of x in a block that is not preceded by an assignment
in that block, savings = 1 if x is in a register.
- If x is live on exit from a block in which it is assigned a value,
and is allocated a register, then we can avoid a store instruction (cost = 2)
at the end of the block.
Total savings for x ~ sum(use(x,B) + 2 * live(x,B) for all blocks B)
This is very approximate, e.g. loop frequencies are ignored.
Cost savings flow graph example
For the following flow graph, how much savings would be earned by leaving
variables (a-f) in a register across basic blocks?
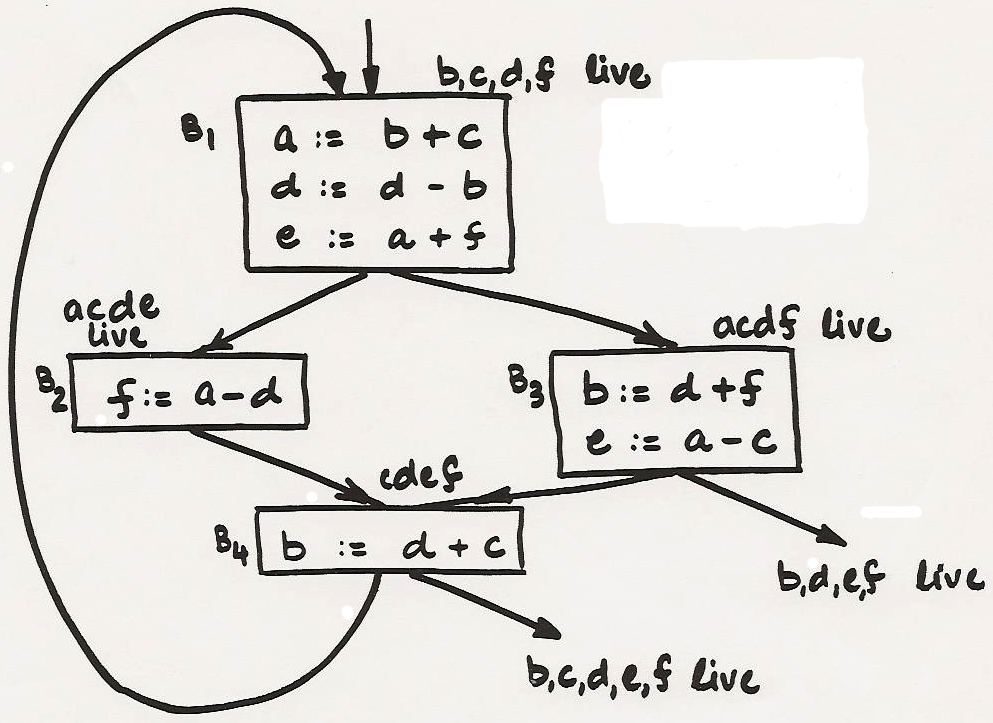
| Savings | B1 | B2 | B3 | B4 | Total
|
|---|
| a | 2 | 1 | 1 | 0 | 4
|
| b | 2 | 0 | 2 | 2 | 6
|
| c | 1 | 0 | 1 | 1 | 3
|
| d | 3 | 1 | 1 | 1 | 6
|
| e | 2 | 0 | 2 | 0 | 4
|
| f | 1 | 2 | 1 | 0 | 4
|
x86_64 Discussion
For what its worth on Windows 64
Warning: the Mingw64 compiler (and possibly other Windows 64-bit c
compilers) do not use the same memory sizes as Linux x86_64! Beware.
If you were compatible with gcc on Linux you might not be on Windows
and vice versa.
Three Kinds of Dependence
In all three of these examples, a dependence relationship implies that
in the program semantics, the second instruction depends on the first
one in some way.
- How are they different?
- How do these affect, e.g., decisions about which registers are in use?
- What about concurrency/superscalar CPU's ?
a = b + c;
...
d = a + e;
|
a = b + c;
...
b = d + e;
|
a = b + c;
...
a = d + e;
|
Review of x86_64 Calling Conventions
64-bit x86 was first done by AMD and licensed afterwards by Intel, so it
is sometimes referred to as AMD64. Warning: Linux and Windows do things
a lot different!
Final Code Generation Example
- finalcg.icn, a program that generates
native code
- Assemble output with command line such as
as -o demo1.o demo1.s
- needs streamlining, removal of exception directive code per
earlier discussion.
Lessons From the Final Code Generation Example
- TAC-to-native-code not that hard; 110 lines netted about half
the TAC instruction set in procedure final(); many other opcodes very
similar.
- Most complexity centers around calls / returns
- Although you pass parameters in registers, IF YOU CALL ANYTHING, and
IF YOU USE YOUR PARAMETERS AFTERWARDS, you will
have to allocate space on the stack for your incoming parameters,
and save their values to memory before reusing that register.
- How hard would it be, for each function body, to determine whether it
calls anything, or is a "leaf" function that does not? How common are
such leaf functions?
- Interesting special case: does a function ever turn around and call
another function with the same parameters? How often? Under what
circumstances might a compiler exploit this?
Reverse Engineering, gcc -S, and Optimization
I decided to fill in a missing piece of the
x86_64 final code generation template page
that I am providing you, and chose a real easy one: if !x goto L.
I figured it would be a two-instruction analogue of if x goto L.
So I constructed a simple program to try and produce the desired code.
#include
int fac(long y)
{
long x;
if (!y) goto L;
printf("hello");
L:
return 1;
}
I was frustrated to find seemingly idiotic code as gcc's default: it was
generating an extra jump and an extra label. Eventually, I tried it with -O
just to see what we would get.
The corresponding gcc -S output is as follows:
| gcc -S | gcc -O -S
|
|---|
.file "foo.c"
.section .rodata
.LC0:
.string "hello"
.text
.globl fac
.type fac, @function
fac:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movq %rdi, -8(%rbp)
cmpq $0, -8(%rbp)
jne .L2
jmp .L3
.L2:
movl $.LC0, %edi
movl $0, %eax # num of float args, for vararg funcs
call printf
.L3:
movl $1, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size fac, .-fac
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-28)"
.section .note.GNU-stack,"",@progbits
|
.file "foo.c"
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "hello"
.text
.globl fac
.type fac, @function
fac:
.LFB11:
.cfi_startproc
testq %rdi, %rdi
je .L4
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $.LC0, %edi
movl $0, %eax # num of float args, for vararg funcs
call printf
.L2:
movl $1, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.L4:
movl $1, %eax
ret
.cfi_endproc
.LFE11:
.size fac, .-fac
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-28)"
.section .note.GNU-stack,"",@progbits
|
Flow Graphs
In preparation for lectures discussing code optimization, a more detailed
discussion of flow graphs is needed.
- A flow graph is a graph in which vertexes are basic blocks
- There is a distinguished initial node, the basic block
whose leader is the first instruction.
- There is a directed edge from block B1 to B2 if:
- There is a conditional or unconditional jump from the last statement
of B1 to the first statement of B2
- B2 immediately follows B1 in the order of the
program, and B1 does not end in an unconditional jump.
Flow Graph Example
if (x + y <= 10 && x - y >= 0) x = x + 1;
Construct the flow graph from the basic blocks
t1 := x + y
if t1 > 10 goto L1
|
t2 := x - y
if t2 < 0 goto L1
|
t3 := x + 1
x := t3
|
L1:
|
Next-Use Information
- use of a name
- consider two statements
I1: x := ... /* assigns to x */
...
I2: ... := ... x ... /* has x as an operand */
such that control can flow from I1 to I2 along some path that has no
intervening assignments to x. Then, I2 uses the value of x
computed at I1. I2 may use several assignments to x via different paths.
- live variables
- a variable x is live at a point in a flow graph if the
value of x at that point is used at a later point.
Computing Next-Use Information (within a block only)
- assume we know which names are live on exit from the block
(needs dataflow analysis; else assume all nontemporary variables
are live on exit)
- scan backwards from the end of the basic block. For each statement
i: x := y op z
do:
- attach to stmt. i the current information (from symbol table) about
next use and liveness of x, y, and z
- in the symbol table, set x to "not live", "no next use"
- in the symbol table, set y and z to "live", set next use of y,z to i
- treatment of
x := y or x := op y is similar
Note: order of (2) and (3) matters, x may be on RHS as well
lecture #55 began here
Mailbag
- Could we cover assembly stack allocation/management?
-
Sure. I've pointed you at a lot of resources; here is another, on
Eli Bendersky's site.
- In the general case, calling arbitrary other code,
ALL registers that hold live values across a call will have to be saved,
and restored after the call. This sounds incredibly expensive, and is
only getting more expensive as CPUs add more and more registers. In
x86_64, the registers are partitioned into those the caller is
responsible for protecting, and those the callee is responsible for.
- Good compilers, then, are all about taking shortcuts and doing
the minimum needed for each specific case. A compiler can save costs
on the caller side and on the callee side.
- Stack registers. As a reminder, there is an rsp
that is the true top of the stack, and a rbp that is the base pointer
register for the current function call. The stack grows down.
- When and what do we have to push and pop from the stack
when we call a function?
-
We (that mens you) should probably look at a bunch of examples, probably by
reverse engineering them with gcc -S, to get a feel for this. A summary on
which we can expand/correct is:
- caller pushes parameters. By default the
first six parameters go into designated registers instead of main memory.
BTW, if you had anything in those registers, you have to save those values
(i.e. push them) before sticking parameters in registers for a new call.
- caller saves r10/r11 if it us using them.
- caller executes CALL instruction.
- CALL instruction pushes return address (IPC) and does a GOTO.
- Callee pushes (saves) rbp
- Callee sets rbp to the top of the stack
- Callee saves other "callee-save" registers if it uses them (rbx,r12-r15)
- Callee pushes/creates local region, by subtracting N bytes from rsp.
- Callee by default copies parameters from registers into local space.
- Callee executes function body.
- Callee stores return value in rax, if there is one
- Callee frees local region by adding N bytes to rsp
- Callee restores rbx, r12-r15 if it uses them
- Callee restores rsp and rbp for caller via LEAVE, or its equivalent.
- Callee executes RET, which pops saved IPC and does a GOTO to it.
- Can we use the stack exclusively for all of our parameters and local
variables?
-
Your compiler can ignore register parameters entirely when you generate code
that calls to and returns from your own functions. IFF your code needs to call
C library code (such as printf, reads, etc.) you would have to use the
standard calling conventions (including registers) to call those functions
successfully.
Storage for Temporaries
- size of activation records grows with the number of temporaries, so
compiler should try to allocate temporaries carefully
- in general, two temporaries can use the same memory location if they
are not live simultaneously
- allocate temporaries by examining each in turn and assigning it the
first location in the field for temporaries that does not contain a live
temporary. If a temporary cannot be assigned to a previously created
location, use a new location.
Storage for Temporaries Example
Consider the following (a dot-product code) example. This is a single basic
block, subdivided using the liveness of some non-overlapping temporary
variables.
|
t1 live |
prod := 0
i := 1
L3: t1 := 4 * i
t2 := a[t1]
|
| t3 live |
t3 := 4 * i
t4 := b[t3]
|
| t5 live |
t5 := t2 + t4
t6 := prod + t5
|
| t7 live |
prod := t6
t7 := i + 1
i := t7
|
|
if i <= 20 goto L3
|
t1, t3, t5, t7 can share the same location.
What about t2, t4, and t6?
Notes:
- the "reusing temporary variables" problem is pretty much the
same as the register allocation problem
- optimal allocation is NP-complete in general
DAG representation of basic blocks
This concept is useful in code optimization. Although we are not doing a
homework on optimization, you should understand it to be essential in real
life and have heard and seen a bit of the terminology.
- Each node of a flow graph (i.e. basic block)
can be represented by a directed acyclic graph (DAG).
- Why do it? May enable optimizations...
A DAG for a basic block is one with the following labels on nodes:
- leaves are labelled by unique identifiers, either variable names or
constants.
- interior nodes are labelled by operator symbols
- nodes are optionally given a sequence of identifiers as labels
(these identifiers are deemed to have the value computed at that node).
Example
For the three-address code
L: t1 := 4 * i
t2 := a[t1]
t3 := 4 * i
t4 := b[t3]
t5 := t2 * t4
t6 := prod + t5
t7 := i + 1
i := t7
if i <= 20 goto L
What should the corresponding DAG look like?
- Chapter 6 of the text presents DAGs constructed from syntax
trees immediately before, rather than after, three address code.
- We presented it later than that, because it enables common optimizations.
Constructing a DAG
Input: A basic block.
Output: A DAG for the block, containing:
- a label for each node, and
- for each node, a (possibly empty) list of attached identifiers
Method: Consider an instruction x := y op z.
- If node(y), the node in the DAG that represents the value of y at that
point, is undefined, then create a leaf labelled y. Let node(y) be this node.
Similar for z.
- determine if there is a node labelled op with left child node(y)
and right child node(z). if not, create such a node. let this node be n
-
- a) delete x from the list of attached identifiers for node(x) [if defined]
- b) append x to the list of attached identifiers for node n (from 2).
- c) set node(x) to n
Applications of DAGs
- automatically detects common subexpressions
- can determine which identifiers have their value used in the block --
these are identifiers for which a leaf is created in step (1) at some point.
- Can determine which statements compute values that could be used outside
the block -- these are statements s whose node n constructed in step (2)
still has node(x)=n at the end of the DAG construction, where x is the
identifier defined by S.
- Can reconstruct a simplified list of 3-addr instructions, taking advantage
of common subexpressions, and not performing copyin assignments of the form
x := y unless really necessary.
Evaluating the nodes of a DAG
- The evaluation order of the interior nodes of a DAG must be consistent
with a topological sort of the DAG, so that operands are evaluated before an
operator is applied.
- In the presence of pointer or array assignments, or procedure calls, not
every topological sort may be permissible.
Example: given a basic block
x := a[i]
a[j] := y
z := a[i]
The "optimized" basic block after DAG construction and common subexpression
elimination equates x and z, but this behaves incorrectly when i = j.
Code Optimization
There are major classes of optimization that can significantly speedup
a compiler's generated code. Usually you speed up code by doing the
work with fewer instructions and by avoiding unnecessary memory reads
and writes. You can also speed up code by rewriting it with fewer gotos.
Constant Folding
Constant folding is performing arithmetic at compile-time when the values
are known. This includes simple expressions such as 2+3, but with more
analysis
some variables' values may be known constants for some of their uses.
x = 7;
...
y = x+5;
Common Subexpression Elimination
Code that redundantly computes the same value occurs fairly frequently,
both explicitly because programmers wrote the code that way, and implicitly
in the implementation of certain language features.
Explicit:
(a+b)*i + (a+b)/j;
The (a+b) is a common subexpression that you should not have to compute twice.
Implicit:
x = a[i]; a[i] = a[j]; a[j] = x;
Every array subscript requires an addition operation to compute the memory
address; but do we have to compute the location for a[i] and a[j] twice in
this code?
Loop Unrolling
Gotos are expensive (do you know why?). If you know a loop will
execute at least (or exactly) 3 times, it may be faster to copy the
loop body those three times than to do a goto. Removing gotos
simplifies code, allowing other optimizations.
| original | unrolled | after subsequent constant folding
|
|---|
for(i=0; i<3; i++) {
x += i * i;
y += x * x;
}
|
x += 0 * 0;
y += x * x;
x += 1 * 1;
y += x * x;
x += 2 * 2;
y += x * x;
|
y += x * x;
x += 1;
y += x * x;
x += 4;
y += x * x;
|
lecture #56 began here
Optimization Techniques, cont'd
Algebraic Properties
Implicit in the previous example of loop unrolling was the notion that
certain computations can be simplified by basic math properties.
| name
| sample
| optimized as
|
| identities
|
x = x * 1;
x = x + 0;
|
|
| simplification
|
y = (5 * x) + (7 * x);
|
y = 12 * x;
|
| commutativity
|
y = (5 * x) + (x * 7);
|
y = (5 * x) + (7 * x);
|
| strength reduction
|
x = y * 16;
|
x = y << 4;
|
This open-ended category might also include exploits of associativity,
distributive properties, etc.
Hoisting Loop Invariants
This one requires knowledge, perhaps too much knowledge. I know the following
optimization is safe, but does the compiler know? What would you have
to know/prove in order for this example to be "safe" for a compiler to do?
for (i=0; i<strlen(s); i++)
s[i] = tolower(s[i]);
|
t_0 = strlen(s);
for (i=0; i<t_0; i++)
s[i] = tolower(s[i]);
|
Peephole Optimization
Peephole optimizations look at the native code through a small, moving
window for specific patterns that can be simplified. These are some of the
easiest optimizations because they potentially don't require any analysis
of other parts of the program in order to tell when they may be applied.
Although some of these are stupid and you wouldn't think they'd come up,
the simple code generation algorithm we presented earlier is quite stupid
and does all sorts of obvious bad things that we can avoid.
| name
| sample
| optimized as
|
| redundant load or store
|
MOVE R0,a
MOVE a,R0
|
MOVE R0,a
|
| dead code
|
#define debug 0
...
if (debug) printf("ugh");
|
| control flow simplification
|
if a < b goto L1
...
L1: goto L2
|
if a < b goto L2
...
L1: goto L2
|
Peephole Optimization Examples
It would be nice if we had time to develop a working demo program for
peephole optimization, but let's start with the obvious.
| as generated | replace with | comment
|
|---|
movq %rdi, -56(%rbp)
cmpq $1, -56(%rbp)
|
movq %rdi, -56(%rbp)
cmpq $1, %rdi
| reuse n that's already in a register
|
cmpq $1, %rdi
setle %al
movzbl %al,%eax
movq %rax, -8(%rbp)
cmpq $0, -8(%rbp)
jne .L0
|
cmpq $1, %rdi
jle .L0
|
boolean variables are for wimps.
setle sets a byte register (%al) to contain a boolean
movzbl zero-extends a byte to a long (movsbl sign-extends)
|
cmpq $1, %rdi
jle .L0
jmp .L1
.L0:
|
cmpq $1, %rdi
jg .L1
.L0:
|
Use fall throughs when possible; avoid jumps.
|
movq %rax, -16(%rbp)
movq -16(%rbp), %rdi
|
movq %rax, %rdi
|
TAC code optimization might catch this sooner
|
movq -56(%rbp), %rax
subq $1, %rax
movq %rax, %rdi
|
movq -56(%rbp), %rdi
subq $1, %rdi
|
What was so special about %rax again?
|
movq %rax, -40(%rbp)
movq -24(%rbp), %rax
addq -40(%rbp), %rax
|
addq -24(%rbp), %rax
|
Addition is commutative.
|
Interprocedural Optimization
Considering memory references across procedure call boundaries;
for example, one might pass a parameter in a register if both
the caller and callee generated code knows about it.
argument culling
when the value of a specific parameter is a constant, a custom version
of a called procedure can be generated, in which the parameter is
eliminated, and the constant is used directly (may allow additional
constant folding).
f(x,r,s,1);
int f(int x, float y, char *z, int n)
{
switch (n) {
case 1:
do_A; break;
case 2:
do_B; break;
...
}
}
|
f_1(x,r,s);
int f_1(int x, float y, char *z)
{
do_A;
}
int f_2(int x, float y, char *z)
{
do_B;
}
...
|
Code Generation for Input/Output
This section is on how to generate code for basic
C input/output constructs.
- getchar()
- Basic appearance of a call to getchar() in final code:
call getchar
movl %eax, destination
Of course, VGo does not have a getchar() function, it reads a line at
a time.
A built-in function for reading a line at a time might be built on
top of this in vgo or in C, but it might be better to call a different
input function.
-
gets() is part of the C standard that permanently encodes
a buffer overrun attack in the language for all time. However, we could use
fgets(char*,int,FILE*) to implement VGo's input function.
char *vgoread()
{
int i;
char *buf = malloc(4096);
if (buf == NULL) return NULL; // should do more
i = fgets(buf, 4095, stdin);
// should do more
return buf;
}
What-all is wrong with this picture?
-
- printf(s...)
- First parameter is passed in %rdi. An "interesting"
section in the AMD64 reference manuals explains that 32-bit operands are
automatically sign-extended in 64-bit registers, but 8- and 16-bit operands
are not automatically signed extended in 32-bit registers.
If string s has label .LC0
movl $.LC0, %eax ; load 32-bit addr
; magically sign-extended to 64-bits
movq %rax, %rdi ; place 64-bit edition in param #1 reg.
call printf ; call printf
- printf(s, i)
- Printf'ing an int ought to be the simplest printf.
The second parameter is passed in %rsi. If you placed a 32-bit
int in %esi you would still be OK.
movq source, %rsi ; what we would do
movl source, %esi ; "real" C int: 32, 64, same diff
- printf(s, c)
- Printf'ing a character involves passing that char as a parameter.
Generally when passing
a "char" parameter one would pass it in a (long word, aligned) slot, and
it is prudent to (basically) promote it to "int" in this slot.
movsbl source, %esi
- printf(s, s)
- Printf'ing a string involves passing that string as a parameter.
For local variable string constant data,
gcc does
some pretty weird stuff.
I'd kind of rather allocate the string constant out of the string
constant region and then copy it into the local region, but perhaps
calculating the contents of a string constant as a sequence of
32-bit long immediate values is an interesting exercise.
Another Word on Interprocedural Optimization
The optimization unit of this course mentions only the
biggest categories of compiler optimization and gives very brief
examples. That "argument culling" example of interprocedural
optimization deserves at least a little more context:
- Interprocedural optimization (IPO) includes any optimizations that
apply across function call boundaries, not just culling
- Because function call boundaries are what is being optimized, this
will often focus on analysis of information known about parameters
and return type
- Includes function inlining, if the compiler decides when to do that,
rather than leave the decision up to the programmer.
- Can only do interprocedural optimization on procedures the compiler
knows about; limited value unless compiling whole program together,
or embedding in linker
- Modern production compilers have extra command-line options for IPO
Comments on Debugging Assembler
The compiler writer that generates bad assembler code may need to debug
the assembler code in order to understand why it is wrong.
- See this tutorial from DBP Consulting for some good ideas
- You almost only need to learn gdb's si and ni commands.
- You also need to know "as --gstabs+"
- You also need to know "info registers", or "i r" (e.g. "i r eax")
- In plain assembler debugging s and n work in lieu of si and ni
Dominators and Loops
Raison d'etre: many/various Loop Optimizations require that loops be
specially identified within a general flow graph context. If code is
properly structured (e.g. no "goto" statements) these loop optimizations are
safe to do, but in the general case for C you would have to check...
- dominator
- node d in a flow graph dominates node n (written as "d dom n")
if every path from the initial node of the flow graph to n goes through d
- dominator tree
- tree formed from nodes in the flow graph whose root is the initial node,
and node n is an ancestor of node m only if n dominates m. Each node in a
flow graph has a unique "immediate dominator" (nearest dominator), hence a
dominator tree can be formed.
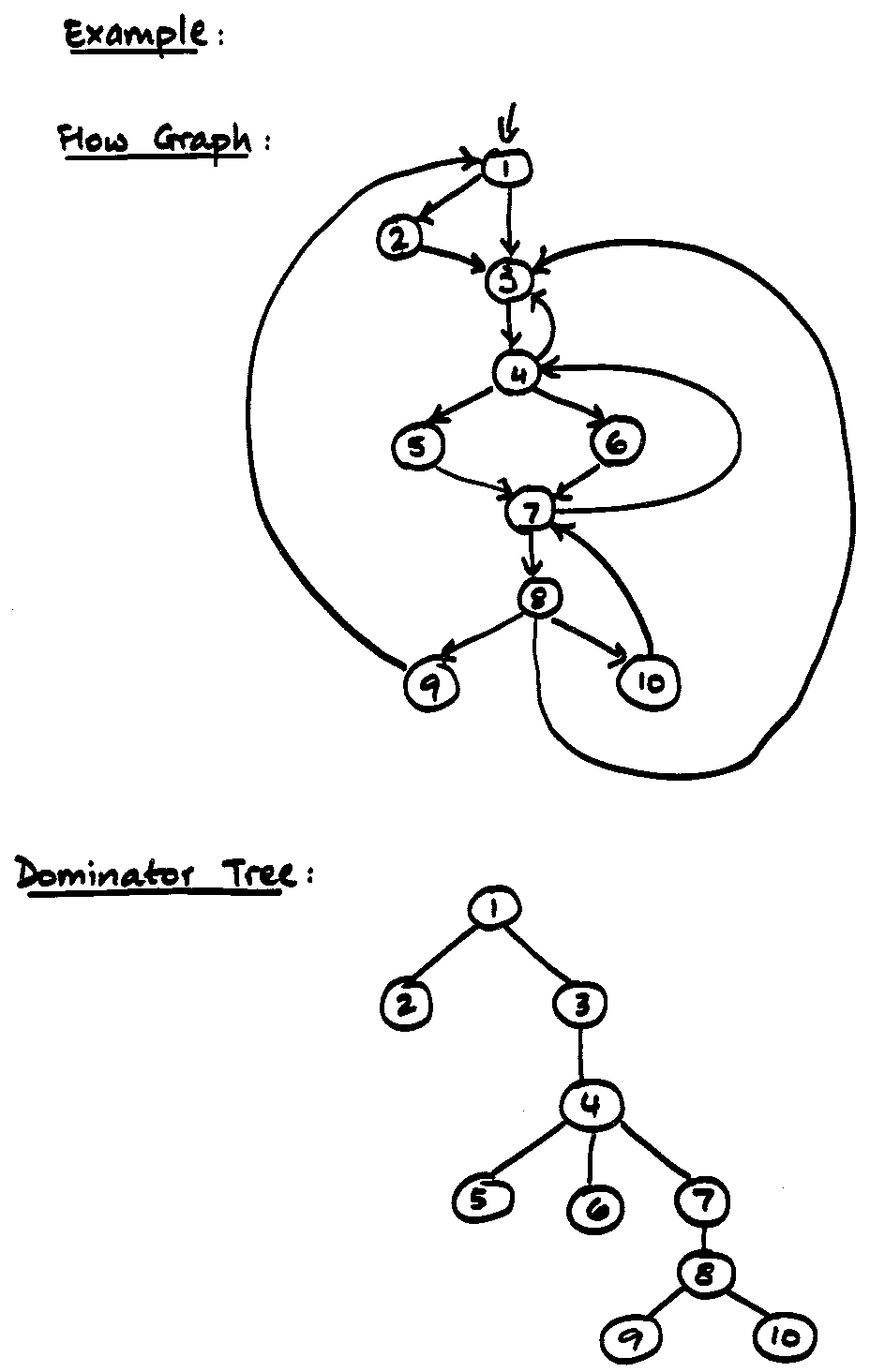
Loops in Flow Graphs
- Must have a single entry point (the header) that dominates all nodes
- Must be a way to iterate; at least one path back to the header
- To find loops: look for edges a->b where b dominates a (back edges)
- Given a back edge n->d, the natural loop of this edge is
d plus the set of nodes that can reach n without going through d.
- every back edge has a natural loop...
Algorithm to construct the natural loop of a back edge
Input: a flow graph G and a back edge n -> d
Output: the set (named loop) consisting of all nodes in the
natural loop of n -> d.
Method: depth-first search on the reverse flow graph G'.
Start with loop containing only node n and d.
Consider each node m | m != d that is in
loop, and insert m's predecessors in
G into loop. Each
node is placed once on a stack, so its predecessors will be examined.
Since d is put in loop initially, its predecessors
are not examined.
procedure insert(m)
if not member(loop, m) then {
loop := loop ++ { m }
push m onto stack
}
end
main:
stack := []
loop := { d }
insert(n)
while stack not empty do {
pop m off stack
for each predecessor p of m do insert(p)
}
Inner Loops
- If only natural loops are considered then unless two loops have the same
header, they are either disjoint or one is nested within the other. The ones
that are nested inside other loops may be of more interest e.g. for
optimization.
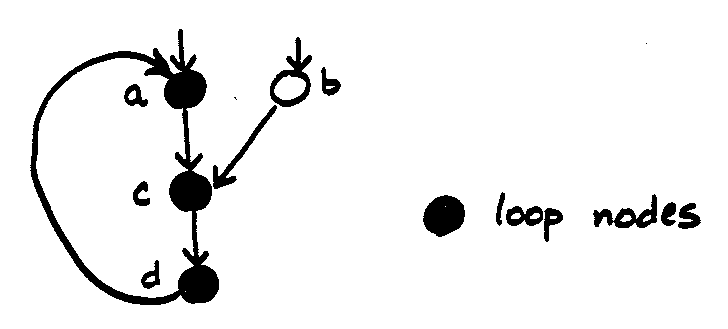
- If two loops share the same header, neither is inner to the other,
instead they are treated as one loop.
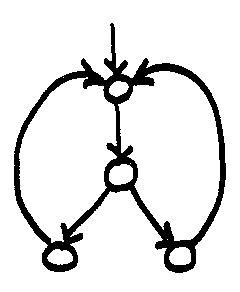
Code Generation for Virtual Machines
A virtual machine architecture such as the JVM changes the "final" code
generation somewhat. We have seen several changes, some of which
simplify final code generation and some of which complicate things.
- no registers, simplified addressing
- a virtual machine may omit a register model and avoid complex
addressing modes for different types of variables
- uni-size or descriptor-based values
- if all variables are "the same size", some of the details of
memory management are simplified. In Java most values occupy
a standard "slot" size, although some values occupy two slots.
In Icon and Unicon, all values are stored using a same-size descriptor.
- runtime type system
- requiring type information at runtime may complicate the
code generation task since type information must be present
in generated code. For example in Java method invocation and
field access instructions must encode class information.
Just for fun, let's compare the generated code for java with that X86
native code we looked at earlier when we were talking about how to make
variables spill out of registers:
iload_1
iload_2
iadd
iload_3
iload 4
iadd
imul
iload 5
iload 6
iadd
iload 7
iload_1
iadd
imul
iload_3
iload 5
imul
idiv
iadd
istore_1
What do you see?
- Stack-machine model. Most instructions implicitly use the stack.
- Difference between "iload_3" and "iload 4": Java VM has special
opcodes that run faster for first 3 locals/temporaries.
thanks here to T. Mowry.
Preheaders
Loop optimizations often require code to be executed once before the loop.
Example: loop hoisting.
Solution: introduce a new (possibly empty) basic block for every loop.
It had to have a header anyhow; give it a preheader.
What was all that Loops/Dominators Stuff For?
- You can't do the loop optimizations on malformed loops!
- To be safe, one must identify proper optimization-eligible "loops"
from their shape in the flow graph, not
from syntax keywords like "while" or "for".
- The whole flow graph for a function, then, will contain zero or more
(usually one or more) inner, natural loops that can be worked on by
storing in an auxiliary data structure the set of nodes (from the flow
graph) that belong under a given header.
Given that you find such a natural loop, you can do:
Loop Hoisting
- identify loop invariant. Invariant wrt loop iff operands are defined
outside loop or constant OR definition inside loop was itself invariant.
- move invariant to preheader
Hoisting Conditions
thank you to Peter Lee
Hoisting conditions
For a loop-invariant definition
d: t = x op y
we can hoist instruction d into the loop’s pre-header if:
1. d’s block dominates all loop exits at which t is
live-out, and
2. there is only one definition of t in the loop, and
3. t is not live-out of the pre-header
Finding Loop Invariants
OK, what can you do with this:
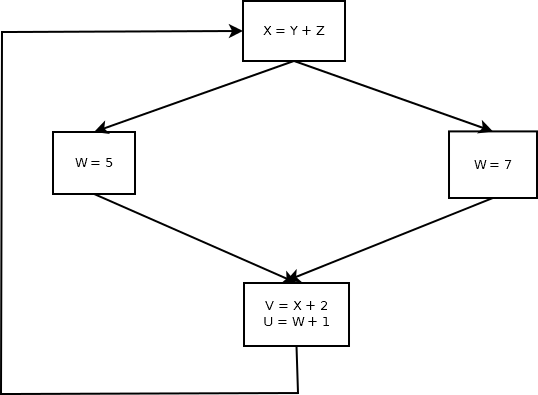
Did you get:
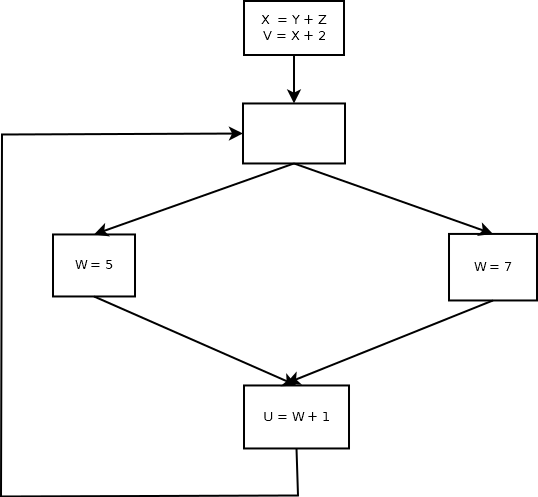
Exercise: run it a few billion times; see whether hoisting a couple
operations out of the loop makes a measurable difference. It might
not, after all... gotos are expensive.
Exercise: what is wrong with this example?
Another example (from Wikipedia loop-invariant code motion):
for (int i = 0; i < n; i++) {
x = y + z;
a[i] = 6 * i + x * x;
}
One can hoise not just x = y + z; because it establishes x as invariant,
subexpression x*x (into a temp variable) can also be hoisted.
More on Runtime Systems
Every compiler (including yours) needs a runtime system. A runtime system
is the set of library functions and possibly global variables maintained by
the language on behalf of a running program. You use one all the time; in C
it functions like printf(), plus perhaps internal compiler-generated calls
to do things the processor doesn't do in hardware.
So you need a runtime system; potentially, this might be as big or bigger a
job than writing the compiler. Languages vary from assembler (no runtime
system) and C (small runtime system, mostly C with some assembler) on up to
Java (large runtime system, mostly Java with some C) and in even higher level
languages the compiler may evaporate and the runtime system become gigantic.
The Unicon language has a relatively trivial compiler and gigantic virtual
machine and runtime system. Other scripting languages might have no compiler
at all, doing everything (even lexing and parsing) in the runtime system.
Quick Look at the Implementation of Unicon
- Language much higher level than C, C++, or Java, closer to Python
- Descended from Icon, whose Big Research Contribution was:
integrating goal-directed evaluation into imperative programming
- Unicon came into existence because a tiny office in The Government
wanted to use Icon, but needed it to be relevent to their real world
problems: big data, analysis of large unstructured text stored in
SQL databases.
- Unicon's Little Research Contributions are:
- scaling Icon to large real-world problems
- adding OOP, concurrency, pattern type, rich high-level I/O subsystems
- native execution monitoring
- At least Three implementations:
- Virtual machine, no registers, yes built-in backtracking
- Optimizing compiler, generates C, backtracking turns into continuation passing
- Transformer, generates Java, backtracking turns into iterators
- In all cases, the runtime system is far larger than the compiler!
- Compared with a traditional language:
- no type checking in the compiler!
- runtime type checks (opt. compiler: type inferencing)
The remainder of this quick look will focus on OO features, as implementing
object-oriented language features is of broad interest.
On Double Constants in Assembler
For what its worth, I was Wrong. I claimed to one or more of you that
immediate mode instructions didn't include full 64-bit immediate constants,
but see the end of lecture #48! Earlier this semester we already noted
that x86_64 does in fact have immediate mode for 64-bits...for at least
one instruction/opcode (movabsq). Proof by contradiction. I note that the
double 3.1415 was represented in output assembler
by $4614256447914709615.
Just for fun, I checked my earlier cast-to-long strategy:
#include
using namespace std;
int main()
{
double d;
d = 3.1415;
long l = *(long *)(&d);
cout << "$" << l << endl;
}
outputs:
$4614256447914709615
We win.
Tips on Invoking the Assembler and Linker from your Compiler
HW#6 calls for your compiler to produce an executable
that I can run. But we have mainly discussed a compiler that writes out code
suitable for input to an assembler. A student requested that I give you some
tips on getting the rest of the way.
- You could write a 120++ shell script that ran your compiler (named
something else) and them ran the assembler and linker.
- Probably better to call assembler and linker from within your main().
- Probably this means invoking an external program/process from your
program.
- Most standard way to do this is via system(s). Could use popen() or
fork()/exec()/wait() but system() is probably best.
- Return integer is a "status" consisting of an exit code PLUS STUFF.
You have to use WEXITSTATUS(i) to get the process return code of
command s.
- The assembler is named as, and as mentioned you may want to use
as --gstabs+, as in
as --gstabs+ -o foo.o foo.s
- The linker is named ld, and you typically would invoke it with not
just your own code, but also startup code to call your main(), and
a runtime library. If your library were named lib120++.a that might
look like:
ld -o foo /usr/lib64/crt1.o foo.o -l120++
- If you were invoking the linker ld on a "real" g++ standard library the
ld command invocation is more complex. For example in December 2017 on
wormulon (Centos) it looked like:
ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib64/crt1.o /usr/lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/4.4.7/crtbegin.o dbl.o /usr/lib64/libstdc++.so.6 -lc /usr/lib/gcc/x86_64-redhat-linux/4.4.7/crtend.o /usr/lib64/crtn.o
Since this is version-specific, the "portable" way would be to use g++ as
your linker, if you are going to link in its standard C++ libraries:
g++ dbl.o
- Runtime libraries like lib120++.a are built from .o files by running
the archiver program ar, as in
ar cr lib120++.a mylib1.o mylib2.o ...
- You can expect to have to read the man pages for as, ld, ar, and system
in order to figure out options.
- There is a potential problem with where your
compiler should find lib120++.a, how shall we solve that?
Imports and Inheritance in Unicon
Unicon is different from mainstream languages, and this section is not intended
to tell you what you are supposed to do, it is intended to provide a basis for
comparison.
Syntax Tree Overview
Unicon uses "iyacc", a variant of Berkeley yacc, which is a cousin of Bison.
The unigram.y grammar has around 234 shift reduce
conflicts. The semantic action at the import statement is illustrative of
tree construction as well as what little semantic analysis Unicon does.
import: IMPORT implist {
$$ := node("import", $1,$2," ")
import_class($2)
} ;
For what its worth, the tree type in Unicon is very challenging and
sophisticated:
record treenode(label, children)
procedure node(label, kids[])
return treenode(label, kids)
end
Actually, Unicon syntax trees are incredibly simple, except that
they are actually heterogeneous trees with a mixture
of treenode, string, token, and various class objects.
Idol.icn
Despite the generic tree, various class objects
from idol.icn store all the
interesting stuff in the syntax tree. It is almost
really one class per non-terminal type, and those
non-terminals that have symbol tables have a field
in the class that contains the symbol (hash) table object.
class Package (one of the only parts of idol.icn I didn't write)
tells a real interesting story. There is both an in-memory
representation of what we know about the world, and a persistent
on-disk representation (in order to support separate compilation).
#
# a package is a virtual syntax construct; it does not appear in source
# code, but is stored in the database. The "fields" in a package are
# the list of global symbols defined within that package. The filelist
# is the list of source files that are linked in when that package is
# imported.
#
class Package : declaration(files, dir, classes)
#
# Add to the two global tables of imported symbols from this package's
# set of symbols. If sym is non-null, we are importing an individual
# symbol (import "pack.symbol").
#
method add_imported(sym)
local s, f
if /dir then return
f := open(dir || "/uniclass", "dr") |
stop("Couldn't re-open uniclass db in " || dir)
every s := (if \sym then sym else fields.foreach()) do {
if member(imported, s) then
put(imported[s], self.name)
else {
imported[s] := [self.name]
}
if fetch(f, self.name || "__" || s) then {
if member(imported_classes, s) then
put(imported_classes[s], self.name)
else {
imported_classes[s] := [self.name]
}
}
}
close(f)
end
method Read(line)
self$declaration.Read(line)
self.files := idTaque(":")
self.files$parse(line[find(":",line)+1:find("(",line)] | "")
end
method size()
return fields$size()
end
method insertfname(filename)
/files := idTaque(":")
if files.insert(filename) then {
write(filename, " is added to package ", name)
writespec()
}
else write(filename, " is already in Package ", name)
end
method insertsym(sym, filename)
if fields.insert(sym) then {
write(sym, " added to package ", name)
writespec()
}
else write(sym, " is already in Package ", name)
end
method containssym(sym)
return \fields.lookup(sym)
end
method String()
s := self$declaration.String()
fs := files.String()
if *fs > 0 then fs := " : " || fs
s := s[1: (*tag + *name + 2)] || fs || s[*tag+*name+2:0]
return s
end
method writespec()
if \name & (f := open(env,"d")) then {
insert(f, name, String())
close(f)
return
}
stop("can't write package spec for ", image(name))
end
initially(name)
if name[1] == name[-1] == "\"" then {
name := name[2:-1]
self.name := ""
name ? {
if upto('/\\') then {
while self.name ||:= tab(upto('/\\')) do self.name ||:= move(1)
}
self.name ||:= tab(find(".")|0)
}
}
else {
self.name := name
}
if dbe := fetchspec(self.name) then {
Read(dbe.entry)
self.dir := dbe.dir
}
/tag := "package"
/fields := classFields()
end
fetching a specification
Given a class name, how do we find it? It must live in a GDBM database
(uniclass) somewhere along the IPATH. A bunch of tedious string parsing
concluding with a GDBM fetch.
#
# find a class specification, along the IPATH if necessary
#
procedure fetchspec(name)
static white, nonwhite
local basedir := "."
$ifdef _MS_WINDOWS_NT
white := ' \t;'
nonwhite := &cset -- ' \t;'
$else
white := ' \t'
nonwhite := &cset -- ' \t'
$endif
name ? {
while basedir ||:= tab(upto('\\/')) do {
basedir ||:= move(1)
}
name := tab(0)
# throw away initial "." and trailing "/"
if basedir[-1] == ("\\"|"/") then basedir := basedir[2:-1]
}
if f := open(basedir || "/" || env,"dr") then {
if s := fetch(f, name) then {
close(f)
return db_entry(basedir, s)
}
close(f)
}
if basedir ~== "." then fail # if it gave a path, don't search IPATH
ipath := ipaths()
if \ipath then {
ipath ? {
dir := ""
tab(many(white))
while dir ||:= tab(many(nonwhite)) do {
if *dir>0 & dir[1]=="\"" & dir[-1] ~== "\"" then {
dir ||:= tab(many(white)) | { fail }
}
else {
if dir[1]==dir[-1]=="\"" then dir := dir[2:-1]
if f := open(dir || "/" || env, "dr") then {
if s := fetch(f, name) then {
close(f); return db_entry(dir, s) }
close(f)
}
tab(many(white))
dir := ""
}
}
}
}
end
Closure-Based Inheritance
Unicon not only allows multiple inheritance, it is the only language that I
know of that can handle cycles in the inheritance graph. It does this by
having each child be completely self-centered. When they inherit, they rifle
through their parents looking for spare change. This is a depth-first method
that completely/perfectly inherits from the first superclass (including all
its parents) and only then considers later step-parents.
Inside class Class, supers is an object that maintains an ordered list of a
class' superclasses (i.e. parents). Variable classes is effectively a
global object that knows all the classes in the current package and let's
you look them up by name. Variable added tracks classes already visited,
and prevents repeating any classes already on the list.
method transitive_closure()
count := supers.size()
while count > 0 do {
added := taque()
every sc := supers.foreach() do {
if /(super := classes.lookup(sc)) then
halt("class/transitive_closure: couldn't find superclass ",sc)
every supersuper := super.foreachsuper() do {
if / self.supers.lookup(supersuper) &
/added.lookup(supersuper) then {
added.insert(supersuper)
}
}
}
count := added.size()
every self.supers.insert(added$foreach())
}
end
Given that all the superclasses have been ordered, the actual inheritance
in class Class is done by a method resolve():
method resolve()
#
# these are lists of [class , ident] records
#
self.imethods := []
self.ifields := []
ipublics := []
addedfields := table()
addedmethods := table()
every sc := supers.foreach() do {
if /(superclass := classes.lookup(sc)) then
halt("class/resolve: couldn't find superclass ",sc)
every superclassfield := superclass.foreachfield() do {
if /self.fields.lookup(superclassfield) &
/addedfields[superclassfield] then {
addedfields[superclassfield] := superclassfield
put ( self.ifields , classident(sc,superclassfield) )
if superclass.ispublic(superclassfield) then
put( ipublics, classident(sc,superclassfield) )
} else if \strict then {
warn("class/resolve: '",sc,"' field '",superclassfield,
"' is redeclared in subclass ",self.name)
}
}
every superclassmethod := (superclass.foreachmethod()).name() do {
if /self.methods.lookup(superclassmethod) &
/addedmethods[superclassmethod] then {
addedmethods[superclassmethod] := superclassmethod
put ( self.imethods, classident(sc,superclassmethod) )
}
}
every public := (!ipublics) do {
if public.Class == sc then
put (self.imethods, classident(sc,public.ident))
}
}
end
Unicon Methods Vectors
Unicon resolves each class' inheritance information at compile time, and
generates a field table for runtime calculations that map field
names to slot#/offsets. Methods vectors are just structs,
shared by objects by means of a pointer (__m) added to class instances.
lecture #57 began here
Final Exam Review
The final exam is comprehensive, but with a strong emphasis on "back end"
compiler issues: symbol tables, semantic analysis, and code generation.
- Review your lexical analysis, regular expressions, and finite automata.
- Review your syntax analysis, CFG's, and parsing.
- If a parser discovers a syntax error, how can it report what line
number that error occurs on? If semantic analysis discovers a
semantic error (or probable semantic error), how can it report what
line number that error occurs on?
- What are symbol tables? How are they used?
What information is stored there?
- How does information get into a symbol table?
- How many symbol tables does a compiler need?
- What is "semantic analysis"?
- What does "semantic analysis" accomplish? What are its side effects?
- What are the primary activities of a compiler's semantic analyzer?
- What are memory regions, and why does a compiler care?
- What memory regions are there, and how do they affect code generation?
- What does code generation do, anyhow?
- What kinds of code generation are there?
- Why do (almost all) compilers use an "intermediate code"? What does
intermediate code look like? How is it different from final code?
This final is from a previous year and has questions specific to that
year's project. But it gives you an idea of the kinds of questions
that appear on the final.
|