Software Validation
Validation is related to verification, but it generally refers to a process
of runtime checking that the software actually meets its requirements in
practice. This may include dynamic analysis.
Validation Testing: an old example
Prologue: This is approximately what I learned about testing from
a university, so according to Kaner, it should not be useful, or I should
not have learned anything from it.
The Unicon test suite attempts to validate, in a general way, the major
functions of the Unicon language; it is used by folks who build Unicon
from sources, especially those who build it on a new OS platform. The
unicon/tests/README file divides the testing into categories as follows:
The sub-directories here contain various test material for
Version 11.0 of Unicon and Version 9.4 of Icon.
bench benchmarking suite
calling calling C functions from Icon
general main test suite
graphics tests of graphic features
preproc tests of the rtt (not Icon) preprocessor
samples sample programs for quick tests
special tests of special features
Each subdirectory has a suite of tests and sample data, and a Makefile for
building and running tests. The master test/Makefile automates execution of
the general and posix tests, which are routinely run on new Unicon builds.
The general/ directory contains tests "inherited" from the Icon programming
language (50 files, 5K LOC):
augment.icn collate.icn gc1.icn mem01c.icn prefix.icn struct.icn
btrees.icn concord.icn gc2.icn mem01x.icn prepro.icn tracer.icn
cfuncs.icn diffwrds.icn gener.icn mem02.icn proto.icn transmit.icn
checkc.icn endetab.icn helloc.icn mffsol.icn recent.icn var.icn
checkfpc.icn env.icn hellox.icn mindfa.icn recogn.icn wordcnt.icn
checkfpx.icn errors.icn ilib.icn numeric.icn roman.icn
checkx.icn evalx.icn kross.icn others.icn scan.icn
ck.icn fncs.icn large.icn over.icn sieve.icn
coexpr.icn fncs1.icn meander.icn pdco.icn string.icn
Some of these tests were introduced when new language features were
introduced and may constitute unit tests; many others were introduced when
a bug was reported and fixed (and hence, are regression tests). A
semi-conscious attempt has been made to use pretty much every language
feature, thus, the test suite forms somewhat of a validation of a Unicon
build.
The tests are all run from a script, which looks about like the following.
Each test is run from a for-loop, and its output diff'ed against an
expected output. Some differences are expected, such as
the test which prints out what operating system, version and so forth.
for F in $*; do
F=`basename $F .std`
F=`basename $F .icn`
rm -f $F.out
echo "Testing $F"
$IC -s $F.icn || continue
if test -r $F.dat
then
./$F <$F.dat >$F.out 2>&1
else
./$F </dev/null >$F.out 2>&1
fi
diff $F.std $F.out
rm -f $F
done
Sample test (diffwrds.icn):
#
# D I F F E R E N T W O R D S
#
# This program lists all the different words in the input text.
# The definition of a "word" is naive.
procedure main()
words := set()
while text := read() do
text ? while tab(upto(&letters)) do
insert(words,tab(many(&letters)))
every write(!sort(words))
end
Sample data file (diffwords.dat):
procedure main()
local limit, s, i
limit := 100
s := set([])
every insert(s,1 to limit)
every member(s,i := 2 to limit) do
every delete(s,i + i to limit by i)
primes := sort(s)
write("There are ",*primes," primes in the first ",limit," integers.")
write("The primes are:")
every write(right(!primes,*limit + 1))
end
Sample expected output (diffwrds.std):
The
There
are
by
delete
do
end
every
first
i
in
insert
integers
limit
local
main
member
primes
procedure
right
s
set
sort
the
to
write
What I Have Learned About Testing
Remember, this was in an academic environment, so Kaner would dismiss it.
- Software changes, so testing is largely about re-testing.
- To reduce the cost of testing, Automate
- Floating point numbers print out differently on different platforms
- Not every difference between expected and actual output is a bug
- Automated test scripts, as with make, are only as portable as your shell,
but since test scripts aren't as complicated as a large system build
process, test scripts are easier to reconstruct on odd platforms.
- Automated test scripts only help when you use them.
- Bug tracking systems only help when you use them. Putting them
up and not using them is negative advertising.
- Properties like "coverage" must be reestablished after changes
- Graphics programs are harder to test. GUI sessions can be recorded,
but its harder to "diff" two computer screens than two text files.
- Testing is only half of the maintenance job: testing without bug fixing
is like holding an election and then keeping the results secret and not
using them.
Software Certification
- Loosely, some organization promises that some property has been checked.
- Verification or validation performed by a third party who is willing
to testify or make the matter part of public record.
- Sometimes has an "insurance" aspect, sometimes not
- People willing to pay for certification are often the same people who
are willing to pay to prove a program is correct.
- Certification doesn't prove anything, it just guarantees some level of
effort was made to check something.
Certification Examples:
- Windows compatibility - application or device driver certification
- Medical device certification
- Avionics certification
Certification of software usually includes certification of the process
used to create the software. Certification of software is also often
confused with certification of the people who write software.
lecture #24 began here
Where we are at
- You should be working furiously to finish/finalize a fully-operational
system.
- The lectures have been going through descriptions of various types of
verification/validation/certification.
Windows Certification
This section does not refer to certification of computing professionals,
but to certification of the software written by 3rd parties for use on
Microsoft platforms. Comparable certifications for other platforms
include
-
Linux Standard Base certification from the Linux Foundation.
- Apple has OSX compatibility labs with a wide range of hardware you can
test on. It rents the lab to developers. It is not obvious that
it offers software certification comparable to Microsoft's.
M$ doesn't certify that your program is bug-free, but it may certify that
your program was written using current standards and API's. The large
body of software developers tends to prefer the status quo, while M$ has
good reasons to try and force everyone to migrate to whatever is new and hot.
The last time I noticed much about this, the public rollout to developers
of a new forthcoming version of Windows included lots of talk about a
new look and feel (you had to take advantage of it), and new installer
protocols (you had to register your software in a particular way during
installation so that the control panel would know how to uninstall you).
If you were willing to jump through these relatively simple hoops in support
of the M$ marketing push for their new OS, and then submit your software
(and maybe pay a modest fee), they would certify you as Windows compatible,
and you'd be eligible for subsidizing on your advertising fees as long as
you advertise your M$-compatibility.
- "Compatible with Windows 7" - Windows 7 Software Logo Program.
- Microsoft-designed tests for compatibility and reliability
(not other forms of quality, nor correctness)
- tied to marketing support
The Windows 7 Software Logo Specification document can be downloaded free from
Microsoft; it covers topics such as the following. Much of this was
found in the Windows Vista logo specification document.
- security and compatibility
- follow user account control guidelines, support x64 versions of the OS,
sign files and drivers, perform windows version checking, support
concurrent user sessions, avoid running anything in safe mode, don't
be malware and follow anti-malware policies.
- .exe's include a manifest that says to run as the invoker, at the
highest available access, or requires administrator privileges.
Nobody by special people get elevated privileges.
- no 16-bit code is allowed
- if you depend on drivers, x64 drivers must be available;
32-bit application code is ok.
- binaries must be signed with an Authenticode certificate
- drivers must be signed via WHQL or DRS
- version check can't autofail on increased Windos version #'s,
unless your EULA prohibits use on future OS'es. Use the
version checking API, not the registry key everyone uses.
- app must handle multiple users/sessions unless they can't.
3D apps are a good example; maybe they don't work over the
remote desktop connection
- if app can't handle multiple users, it must write a nice
message, not fail silently
- sound from one user session should not be heard by another user
- applications must support "fast user switching"
- installing software should not degrade the OS or other applications
- must use Windows Installer (MSI) and do so correctly
- don't assume the installing user will be the running user.
User data should be written at first run, not during the install.
- Applications should be install in "Program Files" or AppData by default
- Software must be correctly identified in "Software Explorer"
(i.e. Add/Remove Programs)
- don't repackage and/or install Windows resources yourself
- don't reboot during installation; be "restart manager aware"
- support command line installation
- pass a number of "Application Verifier" tests; get
Application Verifier from www.microsoft.com/downloads/
- Windows Error Reporting must not be disabled; handle only
exceptions that you know and expect
- sign up to receive your crash data
- installation
- reliability
If M$ certifies you, you are legally allowed to use their logo on your box.
You have to re-certify each major or minor version in order to retain the logo.
Web application certifications:
- www consortium will certify compliance with particular browsers.
But, compliance doesn't guarantee acceptable appearance or performance
on various browsers.
- most individual browsers do not have certification programs, and if they
did they would need to certify visual correctness as well as other
aspects of behavior (pathological performance?).
- has this situation improved?
Sprint Reflection
Pummel:
- Went well:
- lines working, icon glitches, all folks getting started on unit testing
- Needs Improvement:
- meeting attendance, work faster, test plan collaboration
Phunctional:
- Went well:
- test plan, test cases, file saves "mostly" completed,
- Needs Improvement:
- saving/loading all our attributes, SSRS failed to compile!
For next Monday:
Pummel:
- everybody contributing to the test plan
- icons unit testable
- lines deselection working, finish line types
- everybody running unit tests
Phunctional:
- assigning/running tests
- finish saving/loading
- fixing the resizing of class boxes on Linux
QSRs and CGMPs
Software Engineers run into these certification requirements mainly when
writing software for use in medical devices.
-
FDA tends to be picky about instruments that will be used on humans
-
a natural result of centuries of no regulation and many horrible
deaths and maimings.
- FDA estimates that medical errors kill 100,000
Americans and injure another 1.3M each year. Woo hoo!
- Even with current regulations in place
- Testing "samples" gave way to testing the manufacturing process
(for us: the software process) and the test environment.
- "Samples" (the old way) could mean: random samples of instruments
or foods or software test runs.
Definitions
- cGMP
- (current) Good Manufacturing Practice. not specific to software.
documentation of every part of the process. Your food or drug can
be 'adulterated' even if its not in violation of any specific
regulatory requirement, if your process is not using cGMP.
See also the wikipedia entry:
cGMP
- QSR
-
Quality System Regulation. Needs a formal quality system and quality
policy. It must be audited, an improvement cycle needs to be documented.
A software development lifecycle model (from among well known standards)
must be documented.
Safety and risk management must be a documented part of the software process.
Intro to DO-178B (thanks to J. A.-F.)
Software Considerations in Airborne Systems and Equipment Certification,
published by RTCA and jointly developed with EUROCAE. As near as I can
tell RTCA is an industry consortium
that serves as an advisory committee to the FAA. At this writing RTCA charges
$160 for the downloadable e-version of DO-178B; I guess they are profiteering
from public information, despite their non-profit status. UI pays money
every year to be a member, and I can access a copy free but can't share it
with you.
- Requirements for software development (planning, development, verification, configuration management, quality assurance)
- 5 software levels, level A = failure critical, level E = no effect on safety
- Level A (catastrophic) - failure would prevent safe flight and landing
- Level B (major hazard) - failure would reduce the capability of the aircraft or crew (if software makes the users unsafe...the software is unsafe)
- Level C (major) - pain, irritation, or injury, probably short of death
- Level D (minor) - failure just makes more work for everyone
- Level E (no effect)
So... which category your software gets labeled determines how much testing,
verification, validation, or proof gets applied to it. I hope the labeling
is correct!
Data Classification (CC1 and CC2) - what, you mean software certification
includes certification of the data?! Well, we are used to some data being
checked. Baselines, traceability, change control, change review, unauthorized
change protection, release of information...
How much independence is required during certification? Depending on your
level, some objectives may require external measurement, some may require
thorough internal (documented) measurement, and some may be left up to the
discretion of the software developer (e.g. for level "E" stuff).
DO-178B Required Software Verification:
- structural coverage testing
- test at the object code level. test every boolean condition.
- traceability
- requirements must be explicitly mapped to design must be explicitly
mapped to code. 100% requirement coverage. requirements based test tools.
DO-178C
As of December 2011, a successor to DO-178B was approved which retains most of
the text of the DO-178B standard, while updating it to be more amenable to
- OO software (yes, DO-178B is that antiquated)
- formal methods
How to be Certifiable
There is "Microsoft certified" and "Cisco certified", which usually
refers to passing an expensive test that covers a specific set of
user tasks on a specific version of software... this is the kind of
certification you'd expect to get from
"Lake Washington Vocational Technical School".
But...there is also the title:
IEEE Computer Society Certified Software Development Professional
and the forthcoming title:
Certified Software Development Associate.
Mostly, the big and expensive test may make you more marketable in a job
search or as an independent software consultant. It is loosely inspired
by the examination systems available for other engineering disciplines.
It covers the SoftWare
Engineering Body of Knowledge (SWEBOK), a big book that sort of says what
should be covered in classes like CS 383/384. Any teacher of such a course
has to pick and choose what they cover, and the test let's you fill in your
gaps and prove that you are not just a Jeffery-product or UI-product, you
know what the IEEE CS thinks you need to know.
One more certification example
Courtesy of Bruce Bolden, please enjoy this
certification from codinghorror.com
Planning:
In addition to your own prioritized task assignments, please consider:
- which university group(s) you will ask to try out your version of Gus
- what user documentation or help will be necessary for them to use the
application -- is it really, really self explanatory? Add online
documentation and/or manuals to the task list for any use cases that
would not be self-evident to any computer-literate grandmother.
lecture 27 starts here
Product Support
- software support implies technical assistance in using the software
correctly and in fixing problems that occur.
- This is not a substantial focus in our Bruegge text.
- Today's lecture
consists mostly of my thoughts and (limited) experiences in this regard.
Support for Using the Software
What kinds of support have you seen for folks who just need to use the
software?
A lot of this is really about how long will it take (how much it will cost)
to solve a problem. Humans timeout quickly, some more than others. If you
give them the tools to fix the problem themselves, working on it immediately,
they will probably be happier than if you make them wait for your fix.
- printed and online (noninteractive) manuals
- Manuals are out of style, but that is because as Negroponte would say,
they are made out of atoms. The need for a good manual is very strong,
proportional to the feature count of the software system.
- interactive tutorials
- Some of you criticized emacs' usability earlier this semester, but that's
because your personal learning style didn't fit emacs' extensive online
tutorial, or you never used the tutorial. Besides emacs, I learned UNIX
shell programming, C programming, and EverQuest with the help of
extensive interactive tutorials. The best tutorials test whether the
material has been mastered, and report results or even adjust their
content or exercises based on observed performance. Our semester project
has, in places, interactive tutorial elements, but perhaps in order to
get on the same page I should have forced all of us to go through some
tutorials to get a feel for a variety of features in them.
- searchable help
- Besides being a hypertext form of the online manual, a help system
usually has a search capability. Google is thus the world's largest
help system, and if you get your manual searchable via google, you
almost don't need to provide redundant internal capability. Almost.
- context sensitive help
- One area where google can't fulfill all your product support needs (yet)
is in understanding the context of the question. To provide context to
google one generally supplies additional keywords, but it doesn't really
know which keywords are the search term and which are the context, it
just searches for places where all the keywords show up in proximity.
- web or e-mail support
- we probably have all seen web forms that turn around and send an e-mail
to the produt support team. One advantage of this method is that the
team gets an electronic artifact that records the incident. A major
deficiency of this method is, the user doesn't know (or may not feel)
that they have been heard, and doesn't get an immediate answer. Sending
an autoreply message let's them know that the system heard them, but
doesn't guarantee a human will ever see their message, or care about them.
- online chat
- humans crave interactivity. if a user knows a human saw their plea for
help they probably immediately will feel more hopeful and perhaps more
emotionally prepared for whatever wait is needed.
- phone support
- the 45 minute wait on muzak might be tolerable if the phone support is
good, but it is easy for this to go wrong.
Fixing Problems that Occur
How do you know a bug...is a bug?
- When a user doesn't get what they need,
sometimes it is a bug, and sometimes not.
- Blue screens of death are not ambiguous
- a wrong answer might be human error, rather than a bug
- Should you treat all user problems as bug reports until found innocent?
- Should you treat all user problems as user errors until found guilty?
- A human at the right point in the pipeline could perform triage
- Humans are expensive, especially smart humans.
Bug Trackers
Some past class projects have used
Trac.
There are plenty of fancy commercial Bug Trackers. There
are popular open source ones. Check out
this comparison chart of bug trackers.
Personnel Issues
From Bruegge Ch. 14:
- skill types
- application domain, communications, technical, quality, management
- skill matrix
- document staff primary skills, secondary skills, and interests;
try to match up project needs with staff abilities.
| Tasks \ Participant | Bill | Mary | Sue | Ed
|
| control design | | | 1,3 | 3
|
| databases | 3 | 3 | | 1
|
| UI | | | 2 | 1,3
|
| config mgt | 2 | | | 3
|
- role types
- management roles vs. technical roles
- cathedral model
- dictatorship from the top, control
- bazaar model
- chaos, peers, bottom-up
Dr. J's observations regarding personnel issues
- There are true believers and then there are mercenaries.
- (Self-)appraisals are not always accurate.
Corollary: who is watching the watchmen? trust, but verify.
- Even hiring a known-good developer doesn't always work out.
- Sometimes a hire will exceed all hopes and expectations.
- Occasionally there are bad smells.
- Consider the affinity group model; mentor, build group identity.
- High turnover is hard to avoid and expensive.
- New hires are not good for much their first six months.
Static Checking, revisited
Extended Static Checker for Java: a local class copy installed at
http://www2.cs.uidaho.edu/~jeffery/courses/384/escjava, but it is
rhetorical for non-Java project years. There is a copy
of the whole thing as a
.tar.gz file in case you have trouble
downloading from Ireland. My .bashrc for
CS lab machines had to have a couple things added:
export PATH=/home/jeffery/html/courses/384/escjava:$PATH
export ESCTOOLS_RELEASE=/home/jeffery/html/courses/384/escjava
export SIMPLIFY=Simplify-1.5.4.linux
The same distribution, which tries to bundle a half-dozen platforms,
almost (and sort-of) works for me on Windows, but may be somewhat
sensitive about Java versions and such. It gives seemingly-bogus
messages about class libraries (on my Windows box) and doesn't
handle Java 1.5 stuff (in particular, Generics such as
Comparator<tile>). There is at least one system (KIV) that
claims to handle generics, but I haven't evaluated it yet.
-
JML
-
ESCJava
-
ESC Java 2 has run for me before, grudgingly, on my Fedora Core 10
in my office.
-
It would be interesting to run on any Java-based team project.
-
For Python, the best I know of so far is
pylint, it claims to be a
mor powerful tool than PyChecker.
lecture 29 starts here
In addition to your own prioritized task assignments, by the next sprint:
- prepare whatever additional documentation is needed for third party
evaluation
lecture 30 starts here
Risk Management
(Bruegge pp. 607-609)
- best to do at the front of a proposed project, before you even commit to doing it
- risks entailed by not doing it are part of the calculation!
- in avionics certification, we saw
software components be categorized as to the real-world risk
- A=catastrophic...E=no effect
- Risk Management is not just about the risk of component failure
- it is the risks during
the software development process and whole software lifecycle.
How to Do Risk Management
- identify potential problems
- Setup "information flows" such that risks and problems get reported.
Developers often know the risks, but may not want to report them.
Management can't manage what it isn't aware of. So what to do? Reward
risk reporters? Make risk management activities obviously and directly
beneficial to developers. You can also look for "the usual suspects",
and come up with a lot of automatic and universal risks.
- analyze the risks
- there are several things to do by way of analysis of risks:
- risk categorizations
There are many ways to categorize risks
- managerial risks and technical risks.
- Examples
| risk | type
|
| COTS component doesn't work | technical
|
| COTS component doesn't show up when needed | managerial
|
| users hate/reject the user interface | technical
|
| middlware too slow to meet perf. requirement | technical
|
| development of subsystems takes longer than scheduled | managerial
|
- generic risks versus product-specific risks
-
Pressman says product-specific risks cause the most headaches,
so pay extra attention to them.
- performance risk, cost risk, support risk, schedule risk
- This kind of categorization may help direct the risk management
to the right person(s) for the job
- prioritize
- There are two dimensions: probability P of a risk occurring and
impact I of what negative effect the risk may have. These are
categorizations that drive urgency of attention or value of
resources to assign to the risk. Impact I might be the same or
similar to the A-E scale we saw for avionics.
- address the risks in a timely fashion
- can this risk be avoided entirely? can its P or its I be reduced?
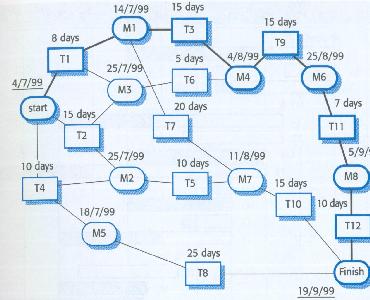 (from Sommerville, 6ed)
(from Sommerville, 6ed)  (from Sommerville, 6ed)
(from Sommerville, 6ed)