CS 210: Programming Languages Lecture Notes
|
|
|
Spring break
Covid-19
etc.
|
|
|
|
lecture #1
Welcome to CS210, here is our Syllabus
The Computer Science Assistance Center (CSAC), located in the JEB floor "2R"
area, has tutors available during most of "business hours" Monday through
Friday.
Most likely you will need help in this course; get to know who works
the CSAC and which ones know which languages.
- The main textbook in this class is by Adam Webber. Either the first or
the current (2nd) edition will be adequate. The textbook for the class
will be supplemented by a large number of language references as well as
this set of lecture notes,
which are revised substantially each time the course is offered.
Printing up front at start-of-semester is inadvisable, since I will
typically be re-ordering material and adding a new language to the mix.
It is OK to read ahead, but plan to re-read after the lecture is given.
Plan to spend quality time here in the class lecture notes.
- all homeworks in this class should be turned in in .zip compressed
format with no binary or executable files included. Submission is on
bblearn.uidaho.edu, which I will occasionally call "blackboard", which
is the commercial name of that product. From time to time
some class clown turns in a homework that is a gzip-compressed tar file,
a .rar, or some other archive format.
- We will discuss, and you are tasked to write homeworks as "literate"
programs. Your submitted .zip files must include your source code and a
makefile that has a "make pdf" rule.
Produce code as a document that you want me to be able to read
and understand. Points will be assigned for readability.
Reading
Read Webber Chapters 1-2.
Slides for Chapter 1
We went through slides #1-21 from Webber Ch. 1.
You should scan through the rest of them and see what questions they raise.
lecture #2
Picking up with Programming Languages
- Reminder: no class on Monday (Martin Luther Day)
- Have you read Webber Ch. 1-2 yet? Might be a quiz next Wednesday
- Webber Chapter 2: programming language syntax
- First Big Homework Unit: programming language syntax
- First Language Paradigm: Declarative
- First Language for you to Learn: Flex (and then Bison)
- I am gonna give you some of my own thoughts on Programming Languages before
we go to Webber Chapter 2.
- Lecture notes (this page) getting moved around a lot to accommodate the
Webber order of topic delivery; if you see a bug please report it. Otherwise,
apologies for the dust.
Why Programming Languages
This course is central to most of computer science.
- Definition of "programming language"
- a human-readable textual or graphic means of specifying the behavior
of a computer.
-
Programming languages have a short history
- ~60 years
-
The purpose of a programming language
- allow a human and a computer to communicate
- Humans are bad at machine language:

- Computers are bad at natural language:
Time flies like an arrow.
- So we use a language human and computer can both handle:
procedure main()
w := open("binary","g", "fg=green", "bg=black")
every i := 1 to 12 do {
GotoRC(w,i,1); writes(w, randbits(80))
}
WriteImage(w, "binary.gif")
Event(w)
end
procedure randbits(n)
if n = 0 then return ""
else return ((?2)-1) || randbits(n-1)
end
Even if humans could do machine language very well, it is still better
to write programs in a programming language.
Auxiliary reasons to use a programming language:
- portability
- so that the program can be moved to new computers easily
- natural (human) language ambiguity
- Computers would either guess, or take us too literally
and do the wrong thing, or be asking us constantly to restate the
instructions more precisely.
At any rate, programming of computers started with machine language, and
programming languages are characterized by how close, or how far, they are
from the computers' hardware capabilities and instructions. Higher level
languages can be more concise, more readable, more portable, less subject to
human error, and easier to debug then lower languages. As computers get
faster and software demands increase, the push for languages to become ever
higher level is slow but inevitable.
Turing vs. Sapir
The first thing you learn in studying the formal mathematics of computational
machines is that all computer languages are equivalent, because they all
express computations that can be mapped down onto a
Turing Machine,
and from
there, into any of the other languages. So who cares what language we use,
right? This is from the point of view of the computer, and it should be
taken with a grain of salt, but I believe it is true that the computer does
not in fact care which language you use to write applications.
On the other hand,
the Sapir-Whorf hypothesis
suggests to us that improving the programming
language notation in use will not cause just a first-order difference in
programming productivity; it causes a second-order difference in allowing
new types of applications to be envisioned and undertaken. This is from
the human side of the human-computer relationship.
From a practical standpoint, we study programming languages in order to
learn more tools that are good for different types of jobs. An expert
programmer knows and uses many different programming languages, and can
learn new languages easily when new programming tasks create the need. The
kinds of solutions offered in some programming languages suggest approaches
to problem solving that are usable in any language, but might not occur to
you if you only know one language.
The Ideal programming language is an executable pseudocode that perfectly
captures the desired program behavior in terms of software designs and
requirements. The two nearly insurmountable problems with this goal are
that (a) attempts to create such a language may be notoriously inefficient,
and (b) no design notation fits all different types of programs.
A Brief History of Programming Languages
There have been a few major conferences on the History of Programming
Languages. By the second one, the consensus was that "the field of
programming languages is dead", because "all the important ideas in
languages have been discovered". Shortly after this report from the
2nd History of Programming Languages (HOPL II) conference, Java swept
the computing world
clean, and major languages have been invented since then. It is conceivable
that the opposite is true, and the field of programming languages is still
in its infancy.
There are way over 1000 major (i.e. publically available and at one
point used for real applications) programming languages. Much less
than half are still "alive" by most standards. Programming languages
mostly have lifespans like pet cats and small dogs. Any language
can expect to be obsoleted by advances in technology within a decade
or at most two, and requires some justification for its continued
existence after that. Nevertheless some dead languages
are still in wide use and might be considered "undead", so long as
people have businesses or governments that are depending on them.
Languages evolved very approximately thus:
machine code, assembler
instruction sets vary enormously in size, complexity, and capabilities.
Difficult for humans.
Basic unit of computation is the machine word, often used as a number.
|

|
FORTRAN, COBOL
"high-level" languages. imperative paradigm.
Entire human-readable arithmetic expressions can be written on a single line.
Flowcharts widely used to assuage the chaos entailed by
"goto"-based program control flow.
|

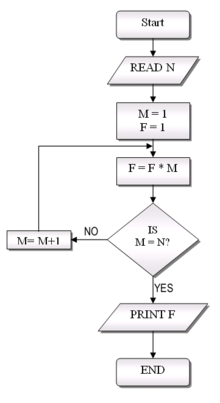
|
Lisp, SNOBOL, APL, BASIC
functional paradigm and alternatives. interpretive. user-friendlier. slow.
Entire functions, or other complex computations, can be written in a line or
two in some of these languages. More important are advances such as automatic
recycling of memory, and the ability to modify or construct new code while
the program is running. But for some folks, they may have fatal flaws.
| 
|
Algol, C, Pascal, PL/1
"structured" languages solve/eliminate the "goto" control flow problem.
Imperative paradigm; "goto"s considered harmful.
The mainstream of the 1970's. Emphasis on fast execution, and protecting
programmers from themselves and each other. Programs tend to become
unmaintainable as they grow bigger.
|

|
Ada, Modula-2, C++
"modular" systems programming languages. data abstraction.
Improvements in scalability to go along with the fact that you have to
write a zillion lines to do anything.
|

|
SmallTalk, Prolog; Icon, Perl
"Pure" versions of object-oriented, functional, and declarative paradigms;
rapid-prototyping and scripting languages.
Extreme power, often within specific problem domains.
|
|
Visual Basic, Python, Java, C#, Ruby, PHP, ...
GUI-oriented and web languages. mix-friendly languages.
The learning curve may be more in the programming environment.
|

|
Go, Swift, Rust...
New languages keep on coming. Improvements are perhaps becoming more gradual
over time. How many times must someone build "a better C" language? They are
still doing it.
What languages should be on this list?
What new languages are "hot"?
|

|
Programming Language Buzzwords
-
"low level", "high level", and "very high level"
-
"low" (machine code level) vs. "high" (anything above machine level)
is ubiquitous but inadequate
- machine readable vs. human readable
- certainly humans have difficulty reading binary codes, but
machines find reading human language text vexing as well
- data abstraction vs. control abstraction
- really, I might prefer data vs. code as my counterpoints
- kinds of data abstractions
- basic/atomic/scalar vs. structural/composite
- "first class" value
- an entity in a programming language that can be computed/constructed
at runtime, assigned to a variable, passed in or returned out of a
subroutine.
- kinds of control abstractions
- many variants on selection, looping, subroutines
- syntax and semantics
- meat and potatoes of language comparison and use
- translation models
- compilation, interpretation, source/target/implementation languages
Googling for History
Here are some highlights from the history of programming languages;
google them and see if they give clean answers or raise more questions
(for exam purposes):
- Programming predated the electronic computer. The first programmer
is widely claimed to be Lady Ada Lovelace. What language was
Ada Lovelace writing in?
- Who was Grace Murray Hopper and what is she famous for?
(her appearance on Letterman only gives part of the answer)
- What does APL, a language from the 1950's/60's have to do with
Google's Map/Reduce paradigm, upon which a decent chunk of modern
cloud computing is built?
- How has the rise of graphical user interfaces affected language design?
- What is the most successful visual programming language to date?
Paradigms and Languages
Several paradigms, or "schools of thought", have been promulgated regarding
how best to program computers.
The dominant imperative paradigm has been gradually refined over
time. It basically states that to program a computer, you give it
instructions in terms it understands. a.k.a. "procedural" paradigm: a
program is a set of procedures/functions. You write new "instructions" by
defining procedures. Since the underlying machine works this way, this is
the default paradigm and the one that all other paradigms reduce themselves
to in order to execute.
Functional and object-oriented paradigms are arguably special
cases of imperative programming. In functional programming you give the
computer instructions in clean, mathematical formulas that it understands.
In object-oriented programming, you give the computer instructions by
defining new data types and instructions that operate on those types.
Declarative programming is a polar opposite of
imperative programming, introduced in many different application contexts.
In declarative programming, you specify what computation is required, without
specifying how the computer is to perform that computation. The
logic programming paradigm is arguably a special case of
declarative programming.
Languages are implemented by compilers or interpreters. There are many
implementation techniques that fall somewhere in between.
Pure vs. Impure; Multi-paradigm
Really, when we say a programming language embodies a particular paradigm,
we are usually saying what it "mainly" does. Languages can be characterized
by evaluating how "pure" is their adherence to their dominant paradigm.
Impurity usually means:
falling back on imperative paradigm when expedient or necessary.
Purity is elegant but often comes at the price of idiocy.
| Pure Language Examples
|
|---|
| Language | Example | Commentary
| | SmallTalk |
quadMultiply: i1 and: i2
"This method multiplies the given numbers by each other and the result by 4."
| mul |
mul := i1 * i2.
^mul * 4
| Pure OO. Even ints are objects.
| | classic Lisp |
(defun fibonacci (N)
"Compute the N'th Fibonacci number."
(if (or (zerop N) (= N 1))
1
(+ (fibonacci (- N 1)) (fibonacci (- N 2)))))
| Pure functional.
No I/O, no assignment statements, etc.
| | Prolog |
perfect(N) :-
between(1, inf, N), U is N // 2,
findall(D, (between(1,U,D), N mod D =:= 0), Ds),
sumlist(Ds, N).
| Pure logic. Surprise failures, wild backtracking, nontermination
|
|
Different programming paradigms seem ideal for different application
domains. What is great for business data processing may be terrible for
rocket scientists. A computer scientist should know all the major paradigms
well enough to know which paradigm is best for each new project that they
come across. One option is to become proficient in several diverse languages.
Another option, sometimes, is to use a language that supports
multiple paradigms. These run the risk of being Frankenlanguages.
They are more likely to succeed when designed by a genius, and
when pragmatic, viewing multi-paradigm as an extension of impurity
rather than a theoretical ideal to aspire to.
| Example Multi-Paradigm Languages
|
|---|
| language | example | commentary
|
|---|
| LEDA |
relation grandChild(var X, Y : names);
var Z : names;
begin
begin writeln('test father-father descent'); end;
grandChild(X,Y) :- father(X,Z), father(Z,Y).
begin writeln('test father-mother descent'); end;
grandChild(X,Y) :- father(X,Z), mother(Z,Y).
begin writeln('test mother-father descent'); end;
grandChild(X,Y) :- mother(X,Z), father(Z,Y).
begin writeln('test mother-mother descent'); end;
grandChild(X,Y) :- mother(X,Z), mother(Z,Y).
end;
| Logic paradigm default; imperative when needed
| | Oz |
proc {Insert Key Value TreeIn ?TreeOut}
case TreeIn
of nil then TreeOut = tree(Key Value nil nil)
[] tree(K1 V1 T1 T2) then
if Key == K1 then TreeOut = tree(Key Value T1 T2)
elseif Key < K1 then T in
TreeOut = tree(K1 V1 T T2)
{Insert Key Value T1 T}
else T in
TreeOut = tree(K1 V1 T1 T)
{Insert Key Value T2 T}
end
end
end
| Pattern matching seems inspired by FORMAN, which is under-credited.
| | Icon |
# Generate words
#
procedure words()
while line := read() do {
lineno +:= 1
write(right(lineno, 6), " ", line)
map(line) ? while tab(upto(&letters)) do {
s := tab(many(&letters))
if *s >= 3 then suspend s# skip short words
}
}
end
|
Imperative default, but logic-style programming when the programmer uses certain constructs.
Unicon adds OO (along with a lot of I/O capabilities).
|
|
lecture #3
Today we did:
We got through about slide 8 or so of the chapter 2 slides.
Syntax
At first glance the syntax of a language is its most defining
characteristic. Languages differ in terms of how they form expressions
(prefix, postfix, infix), what kinds of control structures govern the
evaluation of expressions, and how the programmer composes complex
operations from built-ins and simpler operations.
Syntax is described formally using a lexicon and a grammar. A lexicon
describes the categories of words in the language. A grammar describes
how words may be combined to make programs. We use regular expressions
and context free grammars to describe these components in formal
mathematical terms. We will define these notations in the coming weeks.
| Example Regular Expressions | Example Context Free Grammar
|
|---|
ident [a-z][a-z0-9]*
intlit [0-9]+
|
E : ident
E : intlit
E : E + E
E : E - E
|
Many excellent languages have died (or, been severely hampered)
simply because their syntax was poorly designed, or too weird.
Introducing new syntax is becoming less and less popular.
Recent languages such as Java demonstrate that it is possible
to add more power to programming languages without turning their
syntax inside out.
Syntax starts with lexicon, then expression syntax, and grammar.
We are going to study these ideas in some detail in this course; expect
to revisit this topic.
A context free grammar notation is sufficient to completely
describe many programming languages, but most popular languages
are described using a context free grammar plus a small set of
cheat rules where surrounding context or semantic rules affect
the legal syntax of the language.
Lexical syntax defines the individual words of the language.
Often there are a set of "reserved words", a set of operators,
a definition of legal variable names, and a definition of legal
literal values for numeric and string types.
Expression syntax may be infix, prefix, or postfix, and may
include precedence and associativity rules. Some languages
"expression-based", meaning that everything in the language
is an expression. This might or might not mean the language
is simple to parse without needing a grammar.
Context free grammars are a notion introduced by Chomsky and
heavily used in programming languages. It is common to see
a variant of BNF notation used to formally specify a grammar
as part of a language definition. Context free grammars have
terminals, nonterminals, and rewriting rules.
CFG's cannot describe all languages, and some grammars are
inherently ambiguous. Consider
1 - 0 - 1
and
if E1 then if E2 then S1 else S2
Semantics
However much we love to study syntax, it is semantics that really defines
the paradigms. Semantics generally includes type system details and an
evaluation model. We will come back to it again and again this semester.
For now, note that there can be axiomatic semantics, operational
semantics, and denotational semantics.
Runtime Systems
Programming Languages' semantics are partly defined by the compiler or
interpreter, and partly by the runtime system. A runtime system consists
of libraries that implement the language semantics. They range from tiny
to gigantic. The may be linked into generated code, or linked into an
interpreter, or sometimes embedded directly in generated code. They include
things ranging from implementing language built-ins that aren't supported
directly by hardware, to memory managers and garbage collectors, to thread
schedulers, to input/output.
Memory: the Most Important Problem Solved by (the field of)
Programming Languages
You can argue that the biggest thing languages have done for is us
solve the control flow problem, by eliminating goto statements and
all the spaghetti coding that made early programs difficult to debug.
But Dr. J's Conjecture #1 is that memory management is a dominant aspect
of modern computing. If it is not solved by the language, it will dominate
the effort required to develop most programs. Example: memory debugging in
C and C++ may occupy 60%+ of time spent getting a working solution. Many
C/C++ programs ship with memory bugs.
- Early languages laid out all data statically, as global variables
- About the time we started using functions for everything, we
had discovered that most data was short-lived and could be
re-used effectively if we allocated it on a stack (i.e. local variables).
Machine hardware evolved to dedicate 1-2 registers for this.
- About the time we started using objects for everything, we had
discovered that longer-lived data tended to be associated with
application domain concepts, and that such data had highly variable
lifetimes best served by an (automatically managed) heap.
OO systems typically dedicate another register ("self" or "this")
for this.
I/O: the Key to All Power in the (Computing) Universe
Almost all programming languages tend to consider I/O an afterthought.
Dr. J's Conjecture #2: I/O is a dominant aspect of modern computing and of
the effort required to develop most programs.
Evidence: dominance of graphics, networking, and storage in modern hardware
advances; necessity of I/O in communication of results to humans;
proliferation of different computing devices with different I/O capabilities.
Implications: programming language syntax and semantics should promote
extensible I/O abstractions as central to their language definitions.
Ubiquitous I/O harware should be supported by language built-ins.
Expansion on the whole "Compilers" vs. "Interpreters" thing
Remind me of your definitions of "compiler" and "interpreter" in the
domain of programming languages. What's the difference? Are they
mutually exclusive?
Variants on the Compiler
- classic
- source code to machine code
- preprocessor
- source code to...simpler source code (Cfront, Unicon)
- JIT
- compiles at runtime, VM-to-native or otherwise
- special-purpose / misc
- translate source code to hardware, to network messages, ...
Variants on the Interpreter
- classic
- executes human-readable text, possibly a statement or line at a time
- tokenizing
- executes "tokenized" source code (array of array of tokens)
- tree
- executes via tree traversal
- VM
- executes via software interpretation of a virtual machine instruction set
Enscript
enscript(1) is a program that converts ASCII text files
into postscript. It has some basic options for readable formatting.
enscript --color=1 -C -Ejava -1 -o hello.ps hello.java && ps2pdf hello.ps
produces a PDF like this.
Flex and Bison
Our next "language" in this course is really two languages that were designed
to work together.
- Flex and Bison are free GNU implementations of two classic
languages (lex and yacc) designed by the team at AT&T that brought you
C/C++ and UNIX.
- They are examples of the declarative programming
paradigm.
- Declarative languages take a (mathematically precise) specification
of what is to be computed, and compute it, without the programmer
having to specify the sequence of instructions used to compute the
result.
Reading Assignment: Flex
Read Sections 3-6 of the Flex manual,
Lexical Analysis With
Flex. This manual describes a slightly different version than that
installed on our Linux boxes, but you are unlikely to encounter any
differences that matter in a CS 210 homework.
Regular Expressions
The notation we use to precisely capture all the variations that a given
category of token may take are called "regular expressions" (or, less
formally, "patterns". The word "pattern" is really vague and there are
lots of other notations for patterns besides regular expressions).
Regular expressions are a shorthand notation
for sets of strings. In order to even talk about "strings" you have
to first define an alphabet, the set of characters which can
appear.
- Epsilon (ε) is a regular expression denoting the set
containing the empty string
- Any letter in the alphabet is also a regular expression denoting
the set containing a one-letter string consisting of that letter.
- For regular expressions r and s,
r | s
is a regular expression denoting the union of r and s
- For regular expressions r and s,
r s
is a regular expression denoting the set of strings consisting of
a member of r followed by a member of s
- For regular expression r,
r*
is a regular expression denoting the set of strings consisting of
zero or more occurrences of r.
- You can parenthesize a regular expression to specify operator
precedence (otherwise, alternation is like plus, concatenation
is like times, and closure is like exponentiation)
Although these operators are sufficient to describe all regular languages,
in practice everybody uses extensions:
- For regular expression r,
r+
is a regular expression denoting the set of strings consisting of
one or more occurrences of r. Equivalent to rr*
- For regular expression r,
r?
is a regular expression denoting the set of strings consisting of
zero or one occurrence of r. Equivalent to r|ε
- The notation [abc] is short for a|b|c. [a-z] is short for a|b|...|z.
[^abc] is short for: any character other than a, b, or c.
Some Regular Expression Examples
In a previous lecture we saw regular expressions, the preferred notation for
specifying patterns of characters that define token categories. The best
way to get a feel for regular expressions is to see examples. Note that
regular expressions form the basis for pattern matching in many UNIX tools
such as grep, awk, perl, etc.
What is the regular expression for each of the different lexical items that
appear in C programs? How does this compare with another, possibly simpler
programming language such as BASIC?
| lexical category | BASIC | C |
| operators | the characters themselves | For operators that are regular expression operators we need mark them
with double quotes or backslashes to indicate you mean the character,
not the regular expression operator. Note several operators have a
common prefix. The lexical analyzer needs to look ahead to tell
whether an = is an assignment, or is followed by another = for example.
|
| reserved words | the concatenation of characters; case insensitive |
Reserved words are also matched by the regular expression for identifiers,
so a disambiguating rule is needed.
|
| identifiers | no _; $ at ends of some; 2 significant letters!?; case insensitive | [a-zA-Z_][a-zA-Z_0-9]*
|
| numbers | ints and reals, starting with [0-9]+ | 0x[0-9a-fA-F]+ etc.
|
| comments | REM.* | C's comments are tricky regexp's
|
| strings | almost ".*"; no escapes | escaped quotes
|
| what else?
|
lex(1) and flex(1)
These programs generally take a lexical specification given in a .l file
and create a corresponding C language lexical analyzer in a file named
lex.yy.c. The lexical analyzer is then linked with the rest of your compiler.
The C code generated by lex has the following public interface. Note the
use of global variables instead of parameters, and the use of the prefix
yy to distinguish scanner names from your program names. This prefix is
also used in the YACC parser generator.
FILE *yyin; /* set this variable prior to calling yylex() */
int yylex(); /* call this function once for each token */
char yytext[]; /* yylex() writes the token's lexeme to an array */
/* note: with flex, I believe extern declarations must read
extern char *yytext;
*/
int yywrap(); /* called by lex when it hits end-of-file; see below */
The .l file format consists of a mixture of lex syntax and C code fragments.
The percent sign (%) is used to signify lex elements. The whole file is
divided into three sections separated by %%:
header
%%
body
%%
helper functions
lecture #4
Lecture 4 was spent on student questions about HW#1, particularly, how Flex
worked with C code. The following mailbag question was also answered:
Mailbag
Sometimes if you ask a good question by e-mail that the whole class needs
to hear the answer to, I will answer it in class. Sometimes I will give the
same answer you got by e-mail, and sometimes I will add to it after I think
about it some more.
- Do I have to develop on the cs course server or can I use my own
personal development environment on my laptop? If so, what version of Flex
should I be using. The latest version is 2.6.4
- Develop on any machine you want...but the test scripts will be
run and your grade will be based on how your program runs
on cs-210.cs.uidaho.edu. In practice, different versions of Flex
probably work the same for the purposes of this course, but it is
recommended that you allow time to TEST and FIX on cs-210.cs.uidaho.edu
even if you developed on another machine.
lecture #5
Flex Header Section
The header consists of C code fragments enclosed in %{ and %} as well as
macro definitions consisting of a name and a regular expression denoted
by that name. lex macros are invoked explicitly by enclosing the
macro name in curly braces. Following are some example lex macros.
letter [a-zA-Z]
digit [0-9]
ident {letter}({letter}|{digit})*
Flex also has a bunch of options, such as
%option yylineno
Read the Flex Manual and/or the Flex Man Page!!!
Flex Body Section
The body consists of of a sequence of regular expressions for different
token categories and other lexical entities. Each regular expression can
have a C code fragment enclosed in curly braces that executes when that
regular expression is matched. For most of the regular expressions this
code fragment (also called a semantic action consists of returning
an integer that identifies the token category to the rest of the compiler,
particularly for use by the parser to check syntax. Some typical regular
expressions and semantic actions might include:
" " { /* no-op, discard whitespace */ }
{ident} { return IDENTIFIER; }
"*" { return ASTERISK; }
"." { return PERIOD; }
You also need regular expressions for lexical errors such as unterminated
character constants, or illegal characters.
The helper functions in a lex file typically compute lexical attributes,
such as the actual integer or string values denoted by literals. One
helper function you have to write is yywrap(), which is called when lex
hits end of file. If you just want lex to quit, have yywrap() return 1.
If your yywrap() switches yyin to a different file and you want lex to continue
processing, have yywrap() return 0. The lex or flex library (-ll or -lfl)
have default yywrap() function which return a 1, and flex has the directive
%option noyywrap which allows you to skip writing this function.
A Short Comment on Lexing C Reals
C float and double constants have to have at least one digit, either
before or after the required decimal. This is a pain:
([0-9]+"."[0-9]* | [0-9]*"."[0-9]+) ...
You may be happier with something like:
([0-9]*"."[0-9]*) { return (strcmp(yytext,".")) ? REAL : PERIOD; }
or
([0-9]*"."[0-9]*) { return (strlen(yytext)>1) ? REAL : PERIOD; }
You-all know and love C/C++'s ternary e1 ? e2 : e3 operator, don't ya?
It's an if-then-else
expression, very slick. Since flex allows more than one
regular expression to match, and breaks ties by using the regular expression
that appears first in the specification, perhaps the following is best:
"." { return PERIOD; }
([0-9]*"."[0-9]*) { return REAL; }
This is still not complete.
-
After you add in optional "e" scientific exponent notation, what
should it look like?
- If present, it is an E followed by an integer with an optional
minus sign.
- Remember that
there are optional suffixes F and L.
- E, F, and L are case
insensitive (either upper or lower case) in real constants if present.
Cheesey Flex Example
On the fly, we wrote an example that
recognizes some basic English words, and punctuation.
lecture #6 began here
Reading json.org with my grader, I realized
- there is no character type in JSON, only strings
- there are a lot of things that are not legal JSON!
Accordingly, HW#1 has been tweaked. Beware, and refresh your browser.
Doing Homework on Windows
Yesterday in office hours, a student presented me with a view of their
Windows machine.
- it is possible to get Windows-native versions of flex, gcc etc.
that would run very similarly as cs-210.cs.uidaho.edu.
Mingw32 and Mingw64 are Windows-native compilations of UNIX tools.
-
We found a working flex.exe but missed a GCC on our first try.
- I should have brought up Windows Subsystem for Linux.
It is very capable of giving you all you need for CS 210, but you
have to know enough Linux to install packages after you enable it.
- There are also multiple similar 3rd party packages that provide
a linux-like command environment: cygwin and MSYS2 are like that.
- There is also Oracle virtual box, and installing a Linux in a virtual
machine there.
Lex extended regular expressions
Lex further extends the regular expressions with several helpful operators.
Lex's regular expressions include:
- c
- normal characters mean themselves
- \c
- backslash escapes remove the meaning from most operator characters.
Inside character sets and quotes, backslash performs C-style escapes.
- "s"
- Double quotes mean to match the C string given as itself.
This is particularly useful for multi-byte operators and may be
more readable than using backslash multiple times.
- [s]
- This character set operator matches any one character among those in s.
- [^s]
- A negated-set matches any one character not among those in s.
- .
- The dot operator matches any one character except newline: [^\n]
- r*
- match r 0 or more times.
- r+
- match r 1 or more times.
- r?
- match r 0 or 1 time.
- r{m,n}
- match r between m and n times.
- r1r2
- concatenation. match r1 followed by r2
- r1|r2
- alternation. match r1 or r2
- (r)
- simple parentheses specify precedence but do not match anything
- (?o:r), (?-o:r), (?o1-o2:r)
- parentheses followed by a question mark trigger (or if preceded
by a hyphen, suppress) various options
when interpreting the regular expression
| i | case-insensitivity
|
|---|
| s | interpret dot (.) to mean any character including \n
|
|---|
| x | ignore whitespace and (C) comments
|
|---|
| # | a real Flex comment. Looks like (?# ... )
|
|---|
This is some of the most awful and embarrassing language design
I have ever seen in a production tool. Enjoy.
- r1/r2
- lookahead. match r1 when r2 follows, without
consuming r2
- ^r
- match r only when it occurs at the beginning of a line
- r$
- match r only when it occurs at the end of a line
This example comes from the Flex manual page.
What is similar here to your HW assignment? What must be different?
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
%%
{DIGIT}+ {
printf("An integer: %s (%d)\n", yytext,
atoi( yytext ) );
}
{DIGIT}+"."{DIGIT}* {
printf( "A float: %s (%g)\n", yytext,
atof( yytext ) );
}
if|then|begin|end|procedure|function {
printf( "A keyword: %s\n", yytext );
}
{ID} printf( "An identifier: %s\n", yytext );
"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );
\{[^}\n]*\} /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
int main(int argc, char **argv )
{
++argv, --argc; /* skip over program name */
if ( argc > 0 )
yyin = fopen( argv[0], "r" );
else
yyin = stdin;
yylex();
return 0;
}
yyin
Consider how yyin is used in the preceding toy compiler example,
if you have not already done so. You may need to do something similar.
Warning: Flex is Idiosyncratic!
Flex is a declarative language. The declarative paradigm is the highest-level
paradigm, so why is it so difficult to debug?
Examples of past student consultations:
- Doctor J, my program is sick:
...
IDENT [a-zA-Z_]+ /* this is an ident */
...
- C comments are allowed some places in Lex/Flex, but I guess not all.
This one causes a cryptic error message where the macro is used.
|
- Doctor J, my program won't do the regular expression I wrote:
...
[ \t\n]+ { /* skip whitespace*/ }
...
^[ ]*[a-zA-Z_]+ { return IDENT; }
...
- If the newline and whitespace are consumed by one big grab,
the newline won't still be sitting around in the input buffer to match
against
^ in this ident rule.
|
Point: a language can be declarative, but if it is cryptic and/or
gives poor error diagnostics, much of the claimed benefits of declarative
paradigm are lost.
Warning: Flex can be Arbitrary and Capricious!
Perhaps because of a desire for brevity, the lex family of tools makes
one the same, fatal and idiotic mistakes as Python and FORTRAN: using
whitespace as a significant part of the syntax! Consider when are %{
and %} needed in
- test1.l
- No errors, but fails to declare num_lines and num_chars unless you
add whitespace to the front or use %{ ... %}
- test2.l
- Gives cryptic flex syntax errors unless you
add whitespace to the front or use %{ ... %}
- test3.l
- The proper way to include C code in a Flex header.
Matching C-style Comments
Will the following work for matching C comments? A student e-mail proposed:
[ \t]*"/*".*"*/"[ \t]*\n
What parts of this are good? Are there any flaws that you can identify?
The use of square-bracket character sets in Flex
A student once sent me an example regular expression for comments that read:
COMMENT [/*][[^*/]*[*]*]]*[*/]
This is actually trying to be much smarter that the previous example. One
problem here is that square brackets are not parentheses, they do not nest,
they do not support concatenation or other regular expression
operators. They mean exactly: "match any one of these characters" or for ^:
"match any one character that is not one of these characters". Note also
that you can't use ^ as a "not" operator outside of square
brackets: you can't write the expression for "stuff that isn't */" by saying
(^ "*/")
Does your assignment this semester need to detect anything similar to
C style comments? If so, you should find or invent a working regular
expression that is better than the "easy, wrong" one.
Many different solutions are available around the Internet and
in books on lex and yacc, but let's see what we can do. On a midterm exam,
I am likely to ask you not for this regular expression, but for a regular
expression that matches some pattern of comparable complexity.
Danger Will Robinson:
/\* ... \*/
legal in classic regular expressions, not so in Flex which uses / as a
lookahead operator! Feel free to try
\/\* ... \*\/
But I prefer double-quoting over all those slashes. A famous non-solution:
"/*".*"*/"
and another, pathologically bad attempt:
"/*"(.|"\n")*"*/"
Flex End-of-file semantics
yylex() returns integers. From the Flex manual, it returns 0 at end of file.
HW#1 NOTE: originally the HW#1 spec said to return -1 on end of file. To do
that, you would write a regular expression like
<<EOF>> { return -1; }
This would be compatible with C language tradition of using -1 to indicate
EOF in functions such as fgetc(). However, I changed the main.c spec to say
it would continue to ask for words/tokens as long as it is getting positive
values returned, and it will not matter whether your yylex() function
returns 0 or -1 to indicate end of file. Still, you should know about this
EOF thing in case I make you do multiple files (and use yywrap()) later on.
Flex "States" (Start Conditions)
Section 10 of the Flex Manual discusses start conditions, which allow you
to specify a set of states and apply different regular expressions in
those different states. State names are declared in the header section
on lines beginning with %s or %x. %s states will also allow generic regular
expressions while in that state. %x states will only fire regular expressions
that are explicitly designated as being for that state.
There is effectively an implicit global variable
that remembers what state you are in. That variable is set using a
macro named BEGIN(); in the C code body in response to seeing some regular
expression that you want to indicate the start of a state.
ALL your regular expressions in the main section may optionally
specify via <sc> what start condition(s) they belong to.
Extended Flex Demo
Let's pretend we are doing HW#4 for a bit. In particular, let's try doing
as much as is needed for this program: wh.icn.
procedure main()
i := 1
while i <= 3 do
write(i)
end
Lexical Structure of Languages
A vast majority of languages can be studied lexically and found
to have the following kinds of token categories:
- reserved words
- literals
- punctuation
- operators
- identifiers
In addition, almost all languages will have separators/whitespace
that occur between tokens, and comments.
As you may have seen from homeworks 1-2, regular expressions can't
always handle real world lexical specifications. FORTRAN, for example,
has lexical challenges such as having no reserved words. Consider the
line
DO 99 I = 1.10
FORTRAN doesn't use spaces as separators.
The keyword DO isn't a keyword, unless you change the period
to a comma, in which case we can't be doing an assignment to a variable
named "DO99I" any more...
How many of you used
"states" (a.k.a. "start conditions")? What online resources for flex
have you found? Googling "lex manual" or "flex manual" gives great
results.
Chomsky Hierarchy
- A "language" in formal language theory is a mathematical entity: a set
of strings. It can be finite or infinite.
- Any particular regular expression will match some set of strings,
i.e. some "language".
- The set of all languages matchable by any regular expression
is an interesting class of languages, called the regular languages.
- The regular languages are incapable of matching balanced marks such
as parentheses: no regular language can do 0n1n
- The coming weeks of class will introduce a more powerful notation,
with a corresponding, broader class of languages, the context free
languages, which are described using context free grammars.
- There is a more powerful class than context free languages, called
context sensitive languages.
- The levels of increasing power among categories of languages are
called the Chomsky hierarchy.
Back to Textbook Ch. 2 slides
we got through about slide 26
lecture #7 began here
Syntax Analysis
Lexical analysis was about what words occur in a given language.
Syntax analysis is about how words combine. In natural language
this would be about "phrases" and "sentences"; in a programming
language it is how to express meaningful computations. If you
could make up any three improvements to C++ syntax, what would
they be? Some syntax is a lot more powerful or more
readable for humans than others, so syntax design actually matters.
And some syntax is a lot harder for the machine to parse.
Some Comments on Language Design
- success or failure of a language due to complicated factors
including its design (what else?)
- human-oriented vs. machine oriented
- purist vs. pragmatic
- general vs. special-purpose
Language Design Criteria
"(programming) language design is compiler construction" - Wirth
- efficiency of execution
- writability (efficiency of construction)
- readability (efficiency of maintenance)
- scalability (really Big programs?)
- extensibility (calling out, or adding new built-ins?)
- portability (where-all will it run?)
- stability/reliability (can you count on it?)
- implementability (if not, who cares?)
- consistency
- simplicity
- expressiveness
Context Free Grammars
A context free grammar G has:
- A set of terminal symbols, T
- A set of nonterminal symbols, N
- A start symbol, s, which is a member of N
- A set of production rules of the form A -> ω,
where A is a nonterminal and w is a string of terminal and
nonterminal symbols.
A context free grammar can be used to generate strings in the
corresponding language as follows:
let X = the start symbol s
while there is some nonterminal Y in X do
apply any one production rule using Y, e.g. Y -> ω
When X consists only of terminal symbols, it is a string of the language
denoted by the grammar. Each iteration of the loop is a
derivation step. If an iteration has several nonterminals
to choose from at some point, the rules of derivation would allow any of these
to be applied. In practice, parsing algorithms tend to always choose the
leftmost nonterminal, or the rightmost nonterminal, resulting in strings
that are leftmost derivations or rightmost derivations.
Context Free Grammar Examples
OK, so how much of the C language grammar can we come up
with in class today? Start with expressions, work on up to statements, and
work there up to entire functions, and programs.
Back to Textbook Ch. 2 slides
We started from slide 27 or so. We finished the slide deck.
lecture#8
Announcements
- HW#1 is due Wednesday! I will probably post a HW#2 between now and then.
- No CS 210 class, this Friday, February 7.
YACC (and Bison)
- YACC ("yet another compiler compiler") is a popular tool which originated at AT&T Bell Labs.
- The folks that gave us C, UNIX, and the transistor.
- YACC takes a context free grammar as input, and generates a
parser as output.
- Writes out C code. Handles a subset of all possible CFG's
- YACC's success spawned a whole family of tools
-
Many independent implementations (AT&T
yacc, Berkeley yacc, GNU Bison) for C and most other popular languages.
YACC files end in .y and take the form
declarations
%%
grammar
%%
subroutines
The declarations section defines the terminal symbols (tokens) and
nonterminal symbols. The most useful declarations are:
- %token a
- declares terminal symbol a; YACC can generate a set of #define's
that map these symbols onto integers, in a y.tab.h file. Note: don't
#include your y.tab.h file from your grammar .y file, YACC generates the
same definitions and declarations directly in the .c file, and including
the .tab.h file will cause duplication errors.
- %start A
- specifies the start symbol for the grammar (defaults to nonterminal
on left side of the first production rule).
The grammar gives the production rules, interspersed with program code
fragments called semantic actions that let the programmer do what's
desired when the grammar productions are reduced. They follow the
syntax
A : body ;
Where body is a sequence of 0 or more terminals, nonterminals, or semantic
actions (code, in curly braces) separated by spaces. As a notational
convenience, multiple production rules may be grouped together using the
vertical bar (|).
A Little Peek Behind Lex and Yacc Magic
Why? Because you should never trust a declarative language
unless you trust its underlying math.
-
Lex and Yacc (i.e. Flex and Bison) generate out C code
implementations of a state machine (a.k.a. automaton)
which remembers/encodes (in an integer "state")
what-all the pattern recognizer has seen at a given point.
- The difference between Lex and Yacc is that Lex's state
machine has no "memory", just the single state ("register").
Yacc's state machine has a "memory" consisting of a stack.
The memory (called the parse stack) is what allows Yacc to
manage
- The act of grabbing the next terminal symbol and placing it on the
parse stack (marking it as "seen" and moving to the next symbol) is
called a "shift".
- The act of replacing symbols on the parse stack that match the
righthand side of a grammar rule, with the nonterminal on its lefthand
side, is called a "reduce".
- See CS 385 for more info on the mathematics of state machines
- See CS 445 for more details on parsing algorithms.
Reading Assignment
Read Bison Manual chapter 1-4, 6, and skim chapter 5.
Ambiguity
In normal English, ambiguity refers to a situation where the meaning is
unclear, but in context free grammars, ambiguity refers to an unfortunate
property of some grammars that there is more than one way to
derive some input, starting from the start symbol. Often it is necessary
or desirable to modify the grammar rules to eliminate the ambiguity.
The simplest possible ambiguous CFG:
S -> x
S -> x
Maybe you wouldn't write that, but it is pretty easy to do it accidentally:
S -> A | B
A -> w | x
B -> x | y
In this grammar, if the input is "x", the grammar says it is legal. But
what is it, an A or a B?
Conflicts in Shift-Reduce Parsing
"Conflicts" occur when an ambiguity in the grammar creates a situation
where the parser does not know which step to perform at a given point
during parsing. There are two kinds of conflicts that occur.
- shift-reduce
- a shift reduce conflict occurs when the grammar indicates that
different successful parses might occur with either a shift or a reduce
at a given point during parsing. The vast majority of situations where
this conflict occurs can be correctly resolved by shifting.
- reduce-reduce
- a reduce reduce conflict occurs when the parser has two or more
handles at the same time on the top of the stack. Whatever choice
the parser makes is just as likely to be wrong as not. In this case
it is usually best to rewrite the grammar to eliminate the conflict,
possibly by factoring.
Example shift reduce conflict:
S->if E then S
S->if E then S else S
Consider the sample input
if E then if E then S1 else S2
In many languages, nested "if" statements produce a situation where
an "else" clause could legally belong to either "if". The usual rule
attaches the else to the nearest (i.e. inner) if statement. This
corresponds to choosing to shift the "else" on as part of the current
(inner) if-statement being parsed, instead of finishing up that "if"
with a reduce, and using the else for the earlier if which was
unfinished and saved previously on the stack.
Example reduce reduce conflict:
(1) S -> id LP plist RP
(2) S -> E GETS E
(3) plist -> plist, p
(4) plist -> p
(5) p -> id
(6) E -> id LP elist RP
(7) E -> id
(8) elist -> elist, E
(9) elist -> E
By the point the stack holds ...id LP id
the parser will not know which rule to use to reduce the id: (5) or (7).
YACC error handling and recovery
- Use special predefined token
error where errors expected
- On an error, the parser pops states until it enters one that has an
action on the error token.
- For example: statement: error ';' ;
- The parser must see 3 good tokens before it decides it has recovered.
- yyerrok tells parser to skip the 3 token recovery rule
- yyclearin throws away the current (error-causing?) token
- yyerror(s) is called when a syntax error occurs (s is the error message)
lecture 9
Announcement
- Reminder: no class Friday February 7, sorry!
- HW#1 is due. HW#2 is posted on the class webpage.
Improving YACC's Error Reporting
yyerror(s) overrides the default error message, which usually just says either
"syntax error" or "parse error", or "stack overflow".
You can easily add information in your own yyerror() function, for example
GCC emits messages that look like:
goof.c:1: parse error before '}' token
using a yyerror function that looks like
void yyerror(char *s)
{
fprintf(stderr, "%s:%d: %s before '%s' token\n",
yyfilename, yylineno, s, yytext);
}
Yacc/Bison syntax error reporting, cont'd
Instead of just saying "syntax error", you can use the error recovery
mechanism to produce better messages. For example:
lbrace : LBRACE | { error_code=MISSING_LBRACE; } error ;
Where LBRACE is an expected token '{'.
This assigns a global variable error_code
to pass parse information to yyerror().
Another related option is to call yyerror()
explicitly with a better message
string, and tell the parser to recover explicitly:
package_declaration: PACKAGE_TK error
{ yyerror("Missing name"); yyerrok; } ;
Using error recovery to perform better error reporting runs against
conventional wisdom that you should use error tokens very sparingly.
What information from the parser determined we had an error in the first
place? Can we use that information to produce a better error message?
Getting Flex and Bison to Talk
The main way that Flex and Bison communicate is by the parser
calling yylex() once for each terminal symbol in
the input sequence. The terminal symbol is indicated by the integer
values returned by function yylex().
An extended example of this functioning can be
built by expanding
the earlier Toy compiler example
Flex file for a subset of Pascal so that it talks to a similar
toy Bison grammar.
This was a nice lecture on Flex and Bison with a hands-on end-to-end
example consisting of a lexer and parser for a subset of English language
dates. The main difference between this and your homework, structurally,
was the placement of main() in dates.y instead of a separate .c file. The
example is incomplete; what refinements are needed?
Getting Lex and Yacc to Talk ... More
In addition, YACC uses a global variable named yylval, of type YYSTYPE,
to collect lexical information from the scanner. Whatever is in this variable
each time yylex() returns to the parser is copied over onto the
top of a parser data structure called the "value stack" when the token
is shifted onto the parse stack.
The YACC Value Stack
- YACC's parse stack contains only states
- YACC maintains a parallel set of values
- $ in semantic actions names elements on the value stack:
- $$ denotes the value associated with the LHS (nonterminal) symbol
- $n denotes the value associated with RHS symbol at position n.
- Value stack typically used to construct a parse tree
- The default value stack is an array of integers
- The value stack can hold arbitrary values in an array of unions
- The union type is declared with %union and is named YYSTYPE
- Typical rule with semantic action: A : b C d { $$ = tree(R,3,$1,$2,$3); }
lecture 10
There was no class on Friday February 7.
lecture 11
Using the Value Stack for More Than Just Integers
You can either declare that struct token may appear in the %union,
and put a mixture of struct node and struct token on the value stack,
or you can allocate a "leaf" tree node, and point it at your struct
token. Or you can use a tree type that allows tokens to include
their lexical information directly in the tree nodes. If you have
more than one %union type possible, be prepared to see type conflicts
and to declare the types of all your nonterminals.
Getting all this straight takes some time; you can plan on it. Your best
bet is to draw pictures of how you want the trees to look, and then make the
code match the pictures. No pictures == "Dr. J will ask to see your
pictures and not be able to help if you can't describe your trees."
Declaring value stack types for terminal and nonterminal symbols
Unless you are going to use the default (integer) value stack, you will
have to declare the types of the elements on the value stack. Actually,
you do this by declaring which
union member is to be used for each terminal and nonterminal in the
grammar.
Example: in a .y file we could add a %union declaration to the header
section with a union member named treenode:
%union {
nodeptr treenode;
}
This will produce a compile error if you haven't declared a nodeptr type
using a typedef, but that is another story. To declare that a nonterminal
uses this union member, write something like:
%type < treenode > function_definition
Terminal symbols use %token to perform the corresponding declaration.
If you had a second %union member (say struct token *tokenptr) you
might write:
%token < tokenptr > SEMICOL
Comments from (Old) Student Office-Hour Visits
- lots of productive learning occurs when doing the homeworks
- troubles with syntax error on first token? Bison's integer tokens
for its terminal symbols must match what your yylex is giving it.
- End of file can cause problems. It is
entirely possible to accidentally be returning an end of file code
multiple times or forever, if flex and bison are not handling EOF
the same.
- In debugging, printing out each token (like in the last homework)
inside yylex() can be handy. Or just define YYDEBUG and turn on yydebug.
- Need help with bugfinding? (A) learn difference between syntax and parse
trees and how to use $$=$1 and (B) view each bug in terms of what parent
treenode to look for it in, and what child node shape(s) exhibit the bug.
Debugging a Bison Program
The power of lex and yacc (flex and bison) is that they are declarative:
you don't have to supply the algorithm by which they work, you can treat
it as if it is magic. Good luck debugging magic. Good luck using gdb to
try and step through the generated parser. If "bison --verbose" generates
enough information for you to debug your problem, great.
If not, your best hope is to go into the .tab.c file that Bison
generates, and
turn on YYDEBUG and then assign yydebug=1. If you do, you will get a runtime
trace of the shifts and the reduces. Between that and a trace of every token
returned by yylex(), you can figure out what is going on, or get help with it.
An Inconvenient Truth about YACC and Bison
Did we mention that the parsing algorithm used by YACC and Bison (LALR)
can only handle a subset of all legal context free grammars?
- Full context
free parsers exist, but use so much time and space such that they
were prohibitive back in the 1970's.
- YACC runs in linear time --- proportional to the
input size (# of tokens), a very desirable property for tools that must handle
large inputs all the time, like compilers.
- YACC's space requirements are worse than linear, but it uses tricks
(such as noticing that many of the rows in its
tables are identical) to keep its parse tables reasonable in size.
Hand-simulating an LR parser
Suppose we simulate the "calc" parser on an example input.
It uses the following algorithm. The details are sort of
beyond the scope of this class; what you
are supposed to get out of this is some intuition.
ip = first symbol of input
repeat {
s = state on top of parse stack
a = *ip
case action[s,a] of {
SHIFT s': { push(a); push(s') }
REDUCE A -> β: {
pop 2*|β| symbols; s' = new state on top
push A
push goto(s', A)
}
ACCEPT: return 0 /* success */
ERROR: { error("syntax error", s, a); halt }
}
}
LR Parsing Cliffhanger.
OK, here comes a sample input data! The grammar is:
E : E '+' T | E '-' T | T ;
T : T '*' G | T '/' G | G ;
G : F '^' G | F ;
F : NUM | '(' E ')' ;
What we are really missing in order to actually simulate a
shift-reduce parse of this are the parse tables and how they
are calculated -- this
is covered thoroughly in a number of compiler writing
textbooks. By the way LR parsing (the magic that YACC does) is
not the only or most human-friendly of parsing methods.
lecture #12 began here
Discussion of parsing "(213*11^5)-8"
- the lexical analysis and the parsing are interleaved.
- the whole array of tokens is not constructed before parsing (usually).
-
yyparse() calls yylex() once each time it
does a shift operation
- lexical analysis is thus gradually performed.
This could mix CPU operations and I/O operations
in an attractive balance, but in practice, the I/O has to be heavily
buffered to get good performance at it. You can at least figure that
you are starting with an array of characters
Now, let's see that parse again. The array of char looks like.
The parse stack is empty, yyparse() calls yylex() to read the first
token
| Parse stack | current token | remaining input
|
| empty | '(' |
|
Shift or reduce ? -- shift. Note that you could reduce, even in this empty
stack case, if the grammar had a production rule where there was some
optional thing at the start.
| Parse stack | current token | remaining input
|
| '(' | NUM213 |
|
Shift or reduce ? -- shift. Can't reduce '('.
| Parse stack | current token | remaining input
|
NUM213
'(' | '*' |
|
Shift or reduce ?? Before we can shift a '*' onto the stack, we
have to have an T. We don't have one, we have to reduce. What can
we reduce? We can reduce NUM to an F.
| Parse stack | current token | remaining input
|
F
'(' | '*' |
|
Shift or reduce ?? We still have to have a T and don't, so reduce again.
| Parse stack | current token | remaining input
|
T
'(' | '*' |
|
Shift or reduce ?? Shift the '*'
| Parse stack | current token | remaining input
|
'*'
T
'(' | NUM11 |
|
Shift or reduce ??
(The lecture went on to finish, on the whiteboard)
lecture #13 began here
Announcement
- No class Monday February 17, it is a UI holiday (President's Day)
YYDEBUG and yydebug demo
Let's use Bison to do the previous example.
Extended Discussion of Parse Trees and Tree Traversals
lecture #14 began here
How is HW#2 Going?
- It will be due soon. It is a challenging assignment.
- I have been getting a lot of requests for an extension.
- Extension merit kinda depends on whether you've procrastinated;
also slightly: whether the grader finishes grading HW#1 soon or not.
- What questions do you have for me today?
Reflections on Recent Office Visits
- Folks need to actually read Flex and Bison manuals and try to learn
those tools.
- If you didn't really understand or complete a correct HW#1, HW#2 starts
with: do HW#1.
- json.org, your specification document,
doesn't tell you where the line
between Flex and Bison is, it just presents both in one seamless form.
- HW#2 line between Flex and Bison is: Flex does the 10 categories defined
in HW#1, plus discarding whitespace. Bison does everything else.
- Bison does: objects, arrays, and the elements within them, such as
comma-separated lists of things.
lecture #15 began here
ML Lecture #1
Announcements
- No office hours today 2/21, sorry. But you might catch me between 10:30
and 12:30 today if you are not in class then.
- If you didn't finish your HW#2, keep working on it, seek help by e-mail
or next week. In the absence of an excused lateness, late fees will be
"modest" (5%/day) until our grader finishes
grading HW#1. After that: 10%/day.
- It is time to set the date of our midterm. How about Friday March 13?
Functional Programming and ML
You must unlearn what you have learned. -- Master Yoda
The language ML ("Meta Language"), is from the functional programming
paradigm.
- Function programming tries to view the entirety of computing in
terms of mathematical functions.
- ML was invented by Robin Milner and
colleagues at the University of Edinburgh in the 1970's.
- ML is
influenced by Lisp, the mother of all functional programming languages,
from the 1950s.
To be honest, I like Lisp and am new to ML. Our textbook
author Dr. Webber is an ML nerd, and that is the least of his...
eccentricities. ML is grossly overrepresented in our book. I expect to
march through it fast, and learn however much we can. Webber would like
us to spend half the course on it. I am thinking more like 1/4.
Functional programming in a nutshell
Reading
Read the Webber textbook chapters 5/7/9/11. Originally the intent was to
cover one chapter per class period, but that seems to be impossible.
We will do however much ML we have time for before spring break, and you
should read as fast as we manage to cover material.
ML Slides from Webber
lecture #19 began here
Discussion of HW #1 and HW #2
- If you rocked them both, kudos to you
- If you didn't rock them, you kinda get to choose your future.
- What I can do, and what I can't do.
| Can Do | Can't Do
|
|---|
- help you every which way to learn Flex, Bison, ML
- accept resubmits for partial credit
- ... ??
|
- write your homeworks for you
- extend the academic calendar
- change the past
|
- you must ask the right questions
- HW#2 grading methodology substantially revised from HW#1
- HW#2 was graded similar to how CS 445 homeworks are graded.
- Misgraded, or other complaints with your grade/feedback? Take it up with me.
- Uncanny resemblance between your code and a classmate's? Take it up with me.
- Haven't really learned flex/regex'es/bison/grammars yet? Learn before the midterm.
- Need to fix your homework? Get help as needed, fix, and resubmit.
A Second Look at ML (slides 8-26)
lecture #20 began here
A Second Look at ML (slides 27+)
Polymorphism (slides 1-17)
lecture #21 began here
Polymorphism (slides 18-)
A Third Look at ML (slides 1-11)
lecture #22 began here
Midterm on Friday this week
The midterm will cover what we have seen up to now: Flex, Bison, and ML.
Wednesday will be a Midterm Review.
Thoughts on ML TextIO.inputLine
A Third Look at ML (slides 12-)
We will not cover, and the exams will not include:
A Fourth Look at ML (43 slides)
We will probably discuss, during the 2nd half of the semester:
Scope (48 slides)
Binding (53 slides)
lecture 23
CoronaVirus Update
- Campus authorities have instructed us to not
physically hold class for rest of the semester.
- Class will be online via Zoom.
- You can attend from home, or from your dorm or house on campus, so
long as you have good internet.
- You should have your microphone muted except when
you are asking a question.
- Our CS 210 Zoom ID is 625-323-868. You may wish to connect to zoom.uidaho.edu and
then join our session.
- I will run class from my office (or home office) our classroom appears
to not have a camera setup.
CDAR Testing?
If you have accommodations, feel free to work with CDAR regarding your
exam scheduling. Several students are eligible for this.
Random numbers in ML
From stackoverflow:
val r = Random.rand(1,1);
- returns a random number generator object. The tuple is used to generate
a random seed; almost any two integers would work.
val nextInt = Random.randRange(1,100);
- returns a function that takes a random number generator and returns
an integer between 1 and 100.
nextInt r;
- fetches a random number in the range nextInt was setup for (1..100)
Random.randReal r;
- fetches a random number between 0.0 and 1.0
There are also other functions; see
the manual.
Midterm Review
- Friday's exam will be on Flex and Bison and ML
- Emphasis will be on Flex and Bison because you have had more time to
learn them. ML may feature more than Flex/Bison on the final.
Programming Languages Big Picture Stuff
You should know what are the major programming paradigms, their main ideas,
and which ones have been covered in our class thus far.
Flex Review Materials
You should know...
- flex's basic syntax, major sections, etc.
- basic regular expressions and regex operators
- flex's extended regular expressions -- at least most of them
- sample.l was done in class to illustrate previous
three bullets
- how flex is called from C code, how it communicates with the caller
Bison Review Materials
You should know...
- bison's basic syntax, major sections, etc.
- basic context free grammar notation
A : b A c ;
- what is a shift and what is a reduce
- how a bison generated parser is called from C code (yyparse()),
how it communicates with the caller,
how it communicates with flex
- basic idea of how to build a parse tree
ML Review Materials
What can you tell me, or what can I tell you, about the following:
- ML language
- syntax and semantics
- ML runtime system
- garbage collection, symbol table
- Using ML
- common ML built-in functions and control structures
- ML execution behavior
- be able to diagram memory
What to study in ML
- Functional programming paradigm
- clean, mathematical thinking about computation
- exploratory and experimental programming
- How is ML different than C++?
- Practice with recursion
lecture 24
Welcome to Virtual CS 210
HW#3 Extension
Per student request Homework #3 is now due Wednesday, 11:59pm.
Midterm Exam Results
grade distribution:
157 157
140 143 145 147 149
---------------------- A
132 137
124 129
---------------------- B
111 113 116 117 117
102 103 105
---------------------- C
96
81
---------------------- D
65
34
Midterm Examination Solutions
As an experiment, the midterm exam solutions presentation has been
recorded in 8 separate videos available at this link.
These videos comprise 40+ minutes of the lecture for March 23, which will
consist of reading questions from e-mail, and taking them live at 9:30 on
3/23.
Mailbag
- How do I print multiple lines at one time in ML?
-
That depends on what you mean by multiple lines I guess. To print out
multiple lines at one time, you may want to concatenate those lines into one
big string
s, putting "\n" characters in between
each line. Then call TextIO.output(s) on it. Alternatively,
you could use a loop or recursion to output several lines with several calls
to TextIO.output.
- How can I clear the screen?
-
Clearing the screen might be tricky. ML is not exactly designed to be doing
advanced terminal stuff, and advanced terminal stuff tends to be not
portable -- what works on Linux might be different than what works on Windows
or MacOS for example. My first thought was to call
TextIO.output("\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n");
with enough newline characters to clear the screen. On cs-210.cs.uidaho.edu
you could probably also use OS.Process.system("clear"). More
advanced interactive programs might want to be able to move the cursor to a
particular row and column, or go into "raw" input mode to read characters
one key at a time, but that is beyond the scope of this class.
- I wrote an
exit() function, but it gives a warning message.
How do I get rid of that?
- fun exit () = OS.Process.exit OS.Process.success;
...
- exit();
stdIn:2.1-2.7 Warning: type vars not generalized because of
value restriction are instantiated to dummy types (X1,X2,...)
- The warning is harmless and has to do with the SML type inferencer not
knowing what to do with the return type of function
exit().
Perhaps the
simplest way to shut it up is to return something else. The following
example discards the return value of exit and just returns false.
- fun exit () = (OS.Process.exit OS.Process.success; false);
...
- exit();
- My ML global variables aren't working, what do I do?
- They work alright, but they are immutable. In pure functional
programming, you don't modify existing values, you construct new ones.
ML feels strong enough about this that variables are generally immutable.
Dr. Webber feels strongly enough about it that at the end of
the slides for his 4th Look at ML chapter, he mentions that he explicitly
omitted a discussion of "reference types" which are ML's way of having
mutable values.
Brief Primer on ML Reference Types
Because although you should do everything with recursion and immutable
variables, you eventually must do whatever it takes to get your program
to meet its requirements. Some ideas here came from
Cornell
- A value of type "int ref" is a pointer to an int.
- The
! reads/dereferences the value pointed to.
- The
:= operator writes/modifies what a ref points to.
Examples:
- val Health : int ref = ref 30;
val Health = ref 30 : int ref
- Health;
val it = ref 30 : int ref
- !Health;
val it = 30 : int
- Health := (!Health) - 1;
val it = () : unit
- !Health;
val it = 29 : int
lecture 25
Practice Raising your Hand
If you text chat me enough, and are patient, I will probably respond to that,
but if you click on the Attendees (Participants) button, that window also has
"raise hand" button that you can toggle in order to raise your virtual hand,
which might be a bit more in-my-face than the chat window. Miguel already knew
how to do it last class. Let's practice it now; see if you can find it and
raise your hand and be recognized at least once in today's class.
Mailbag
Can you tell me what is wrong with my code? It is saying "Error:
unresolved flex record (can't tell what fields there are besides #1)"
- When the SML type inferencer fails, it sometimes makes you spell out
what types to use. For example, you can tell it you have a list of tuples
like this:
fun print_hand (L:(int*bool*string*int*int) list,i) = ...
Per earlier in class discussion, using tuple elements by position (#1)
is usually not the best way to do it. But do what you gotta.
Unicon
I made some (alright, amateurish first attempts) to describe Unicon via video.
To see the screen contents you will probably have to view the video in fullscreen mode.
I want reports on the legibility of the video and audio.
This covers approximately half of Wednesday's lecture; the other half will be
delivered, and hopefully recorded, at the regular 9:30am class time.
- Philosophy: make programming as easy as possible
- Very high level, familiar* syntax, (a lot of) extra power
- Descended from SNOBOL, via
Icon
- Unicon was created around 2000 by merging several extensions of Icon. The initial contributions were by Clinton Jeffery, Shamim Mohammed, and Federico Balbi.
- Unicon is hosted at unicon.org and the
code is on Source Forge and
Github.
- Besides Unicon father Clinton Jeffery, the language incorporates major
contributions from around two dozen individuals listed on Unicon's
Citizens page
- Unicon is a goal-directed language
- Goal-directed evaluation simplifies many expressions
and makes them clearer. This is from real life, i.e. a student's
CS 445 homework.
else if (node->kids[1]->prodrule == ADDITIVE_EXPRESSION + 1 ||
node->kids[1]->prodrule == ADDITIVE_EXPRESSION + 2 ||
node->kids[1]->prodrule == MULTIPLICATIVE_EXPRESSION + 1 ||
node->kids[1]->prodrule == MULTIPLICATIVE_EXPRESSION + 2 ||
node->kids[1]->prodrule == MULTIPLICATIVE_EXPRESSION + 3 )
...
Compare with this Unicon code:
else if node.kids[2].prodrule =
((ADDITIVE_EXPRESSION+(1|2)) | (MULTIPLICATIVE_EXPRESSION+(1|2|3)) then...
Unicon Basics
- Variable declaration is optional
- This is a compromise between the needs of scripting/prototyping languages,
and the need to support larger mainstream software engineering projects.
local, global, and static
declarations are recommended in large programs or libraries.
- Variables can hold any data type, and reassigned with different types
- Like in Lisp, Python etc. But this is very rare in practice.
-
type(x) returns a string type name
("list", "integer" etc) of x
- You can write code that works across multiple types.
Heterogeneous, polymorphic awesomeness.
- arithmetic is pretty normal
- ^ is an exponentiation operator.
Integers are unlimited precision. Reals are C doubles.
- Type conversion is automatic across scalar types
- Runtime error when conversion won't work, except in explicit conversion functions, which fail instead.
- Strings use double quotes and are escaped using \
- indexes are 1-based; they are immutable, atomic; not arrays of char; there is no char type
- s[i] := "hello" works
- really like s[1:i] || "hello" || s[i+1:0]
- *s is a length operator, repl(s,i) is i concatenations of s
- expressions in Icon can fail to produce a result
- failure cascades to surrounding expressions
- Built-in types include lists, tables, sets, csets, and records.
- Arguably simpler to use than Common Lisp's
- Classes and packages
- Well-suited for large-scale apps
- Easy I/O capabilities
- 2D, 3D, and network programming
Fundamentals of the Goal-Directed Paradigm
| Ordinary Languages | Goal-Directed Evaluation
|
|
expression evaluation computes a return value, no matter what
|
expression evaluation can succeed or fail
|
If you have a problem:
- return an "error code" or "sentinel value", or
- raise an exception
| If you have a problem:
fail
|
If your expression has multiple answers
- compute first, write a loop to get the rest
- compute all, return an array/list/whatever
|
If your expression has multiple answers:
generate results as needed by surrounding computation
|
Fallible Expressions
- Expressions want to succeed in computing their result
- Some expressions cannot fail, or cannot succeed
- Some expressions are explicitly intended to test and possibly fail
- Most expressions can do their thing iff their operands succeed
- A fallible expression is one that may possibly produce 0 results.
Examples:
| can't fail | can't succeed | test (fallible) | depends on operands
|
|---|
| 1 | &fail | x < 1 | x+1
|
lecture 26
Intermittent Internet, Audio Distractions from Home
- Per Governor Brad Little's directives, most or all lectures during
the rest of the semester may be delivered from home, as was last Wednesday's
class.
- Lectures may have
intermittent interruptions whenever my home internet is flakey; I ask
you to be patient and bear with me in such circumstances.
- Similarly, there may be background noise at home, such as my beagle
whining, or piano or french horn or a vacuum cleaner. Sorry about that.
- I will also pre-record lecture materials when time allows; that might
reduce our dependency on our synchronous 9:30 time slot and my
home internet.
- Please help me to remember to record each lecture period; at the
start of class, ask me "Dr. J, have you started recording?"
- However, uploading prerecorded videos from home is proving to be
dicey at best (large files, failed uploads), so there may be delays
in making such videos available.
Reading Assignment
Read Chapter 1-3 of the
Unicon book, from
Generators
A video about Generators is here (27 minutes).
Generators are simply expressions that logically might produce more than one
result. For further reading, see "Generators in Icon", by Griswold, Hanson,
and Korb.
Some common generators in Unicon include:
-
i to j generates all the numbers between i and j
-
x | y generates x and then y (called alternation)
-
!x generates elements from x
In the realm of string scanning:
-
find(s) generates all positions where s occurs
-
upto(c) generates all positions where a member of c occurs
In addition to chaining all of these (and a few other built-in generators)
together, you can create your own generators. We'll show this in a
bit.
String Scanning
s ? expr
evaluates expr in a string scanning environment in which string s
is analyzed (terminology: s is the subject string). While in a
string scanning environment, string functions all have a default string,
and a default position within the string at which they are to operate.
s ? find(s2)
searches for s2 within s and is a lot like find(s2, s, 1).
You almost never use string scanning if you only have one string function
to call, but rather, when you are breaking up a string into pieces with
multiple functions. In this case, function tab(i) changes the position to i,
and function move(i) moves the position by i characters. tab() and move()
return the substring between the start position and where they change it to.
s ? {
if write(f, tab(find("//"))) then {
move(2) # move past //
write(&errout, "trimmed comment ", tab(0))
}
else write(&errout, "there was no comment")
}
Built-in scanning functions include:
- find(s)
- search for a string
- upto(c)
- search for a position at which any character in set c can be found
- match(s)
- if current position starts with s, return position after it
- any(c)
- if current character is in c, return position after it
- many(c)
- if current position starts with characters in c, return position after them
- bal(c1,c2,c3)
- like upto(), but only return positions at which string is "balanced" with respect to c2, c3. Tricky in one respect.
Actually several of these are generators.
We looked at several string scanning functions within an example
program foo.icn.
lecture 27
Pass/Fail Option; Later Drop Deadline
- You now have until May 1 to decide if you want to switch
to Pass/Fail, or if you wish to drop.
- Switching to Pass Fail might be good or bad.
- A grade of P does not count on your GPA but a Fail does count.
- Since Passing in Pass Fail clears you to
proceed with later CS courses which require a C or above, a Pass will be
assigned for work equivalent to a C or above, relative to your peers.
- In a typical Jeffery CS class, "C or above" is earned with some
overall score of roughly 55-65% of available points.
- I will adhere to grade categories and percentages in the syllabus
- Points awarded on bblearn are not used as-is; they are weighted by
me in calculating the final
grade, to reflect some assignments being more difficult
or more important than others.
Here are the CS department's tutorial office hours.
ShareScreen dropped out in the first generator lecture
This has been reported to me; I will fix that lecture if possible.
Resubmits, Regrades, and Grade Checks
Thank you to several of you for e-mailing regarding resubmits
needing grades or grade adjustments. I will work on those this week.
Office Hours: Switching to Meeting ID 795-166-283
Purpose: configured a waiting room on this ID.
More about Generators
-
a | b
- The simplest generator is alternation. Instead of saying
x = 5 | x = 10
you can just say x = (5|10).
This is shorter and more readable than ordinary programming languages,
instead of adding power by being "weirder". Maybe read | as "then" instead of
"or". So what does
(1 | 2) + (x | y)
do?
-
i to j
i to j by step
-
The coolness here is that a traditional language's "for-loop" has been
generalized not just into an iterator, but into an expression that can be
smoothly blended into any surrounding expression context.
-
!x
-
All data structures in the language support the "generate" operator to
produce their contents. Files generate their contents a line at a time.
Consider
s == !f
-
find(s), upto(c), and bal(c1,c2,c3)
-
These classic string pattern matching generators produce (return) indices
within a string.
- They take optional parameters for string to examine, and
start and end positions to consider.
- They are usually used in a string
scanning environment where these parameters may be omitted.
- Of the three,
bal() is seldom used and a bit trickier than the others.
It generates
positions containing characters in c1 (like upto())
balanced with respect to
c2 and c3. Note that if *c2 and *c3 are greater than 1, though, it does not
distinguish different kinds of parentheses.
-
seq(), key()
-
For completeness sake, here are the remaining two "built-in" generators.
seq() generates an infinite sequence of integers.
key() generates the "keys" of a table or set.
User-Defined Generators
Generators are often a convenient way to write
dynamic programming solutions. Reserved word suspend
produces a result (like return) but leaves the generator around
to be resumed for additional results if nedeed.
procedure fib()
local u1, u2, f, i
suspend 1|1
u1 := u2 := 1
repeat {
f := u1 + u2
suspend f
u1 := u2
u2 := f
}
end
- This procedure generates the numbers in the fibonacci sequence.
- Compared to calling the naive recursive fibonacci function for higher and
higher values of n, this single call that generates many results runs
crazy fast.
- But the sequence is infinite, so if you call this from an
every loop it will never stop.
- There is a limitation operator that can limit a generator to
at most n results:
g \ n
procedure main()
every write(fib() \ 5)
end
lecture 28
How unreliable is Dr. J's home machine?
On Monday at the end (fortunately) of a committee meeting, while still on zoom,
I got a BSOD. If that happens, I'll turn off my machine, turn it back on, and
reconnect to zoom as soon as I can.
Reading
Please skim chapters 5-9 and read chapters 10-12 of
Programming with Unicon.
The rest of the Unicon book is also useful,
but there will be no exam questions on it.
Record the Lecture Please, Dr. J
Someone needs to say it, or it might not happen.
Unicon: highlights of built-in data types
Let's review all the major data types in Unicon.
Scalar Types are immutable and passed by value. They can at least
semi-plausibly be converted to and fro.
- integer
- arbitrary precision, ^ is an exponent operator
baservalue literals for bases 2-36.
- real
- double precision
- strings
- "hello\tworld\n", s1 || s2, s1 == s2, s[i], s[-i], s[i:j]
scanning control structure and functions, pattern matching
- csets
- 'hello\tworld\n' === '\ndlrow\teh', c1 ++ c2, c1 -- c2 , any(c)
used heavily in scanning functions, keywords &letters etc.
Structure types are mutable, passed by reference, allow heterogeneous elements,
can contain references to themselves, etc. They generally do not convert back
and forth, but many structure operations are polymorphic.
- lists
- ["hi", "CS", 210], L[i], L[i:j], L1 ||| L2, push(L, x), pop(L), put(L, x), pull(L)
arrays are special cases.
lists of lists are common; lists of tables etc.
lists can even contain themselves.
- tables
- ["hi" : "there"; "CS" : 210], t[k]
beware using lists (etc.) as keys
- sets
- S1 ++ S2, S1 ** S2, S1 -- S2, member(), delete(), insert()
- records and classes
- constructors, methods, etc.
Oddball Types
- files
- includes open windows, pipes, network and database connections
much higher-level than typical languages' library-based access
- co-expressions
- denote a computation (say, a generator for example) that you can
pass around and use from different locations, and for which you
can grab its results one at a time as-needed
- threads
- denote a computation that can be executed in true multi-core parallel
fashion. There are locks and message passing facilities to deal with
race conditions.
lecture 29
Office Hours Today Rescheduled
A Ph.D. student of Dr. Marshall Ma's is doing his Ph.D. proposal defense
this afternoon at least from 1:30-2:30 and it may well go until 3, meaning
at least half and probably all of today's office hours will be eaten up.
If you need to consult me, send me an e-mail and suggest a day/time, I will
be glad to help you if I can.
HW#3 Comments
- A number of your ML programs were spectacular!
- A number of your ML programs were nonstarters
- Please to polish and resubmit your ML program, if you
didn't really get it done, or
got less credit for it than you deserved.
Turn on Recording, Dr. J
Records
Recursive Generators
Given a record tree(data, ltree, rtree), what does the
following procedure do?
procedure walk(t)
if /t then
fail
else {
suspend walk(t.ltree | t.rtree)
return t.data
}
end
Compare that with a non-generator, conventional
"Visitor" design pattern solution:
procedure walk(t, p)
if /t then fail
walk(t.ltree, p)
walk(t.rtree, p)
p(t.data)
What does this procedure do?
procedure leaves(t)
if /t then fail
else if /(t.ltree === t.rtree) then
return t.data
else {
suspend leaves(t.ltree | t.rtree)
}
end
Recursion and Backtracking
-
The point of generators and goal-directed evaluation is to provide
implicit backtracking
built-in to the language, when you need it.
- But is backtracking actually used? Is it so rare that we don't care?
- I first ran into it in the field of parsing (linguistics and
compilers use parsers) where backtracking might be used to try
different production rules
- Backtracking is broadly used in the CS
area of searching, especially in A/I. Searching is pretty darn
common/central/important.
- Backtracking can be especially powerful when combined with recursion.
Recursive backtracking examples,
UT Longhorn-style.
This is a long slide set. You may wish to review additional slides in this
slide deck, beyond the set covered in class.
lecture 30
Unicon: Classes and OOP
- Our textbook teaches OOP in its Java chapters, so I could take
my pick of teaching you OO in Java or in Unicon.
- OOP was my initial contribution to Unicon, and there is a
whole story there.
- I'll tell my story and then look through Webber to see what,
if anything, he has to add.
Three Pillars of Object Orientation
For some people the three principles of object-orientation are:
- encapsulation
- this is the fundamental ability to define an "object"
- police-state interpretation: this is about protection -- guaranteeing
the outside world cannot mess up a piece of code+data by
preventing access except through public interface functions. Makes
it easier to prove correctness.
- sim/modeling interpretation: code is easier to read and debug
if it is placed near the data that it manipulates, organized around
application domain concepts
- polymorphism
- as covered earlier by Webber: encapsulation and public interfaces
can facilitate writing code that works on different types
- inheritance
- we can write new code in terms of generalizations and specializations.
we can write new kinds of objects in terms of their differences from
what we've already got.
- Unicon's OOP is generally a lot simpler than mainstream languages.
- The goal is to add power, not to protect programmers from themselves.
- Everything is public, and everything is "virtual"; there
are no static methods, and no non-virtual methods.
Here is a gentle syntax comparison, adapted from Hani Bani-Salameh.
| C++ | Unicon
|
|---|
class Example_Class {
private:
int x;
int y;
public:
Example_Class() {
x = y = 0;
}
~Example_Class() { }
int Add()
{
return x + y;
}
};
|
class Example_Class (x,y)
method Add()
return x + y
end
initially
x := y := 0
end
|
- Classes are records with methods.
- Instances are created via a call:
o := Example_Class(1,2)
- Methods are called via
o.Add()
- constructor code is given via an optional
initially section
- The
initially may include parameters, and if it does, they
are used INSTEAD of the default, which is to initialize fields directly
from actual parameters passed in to the constructor.
Another OOP Example
class listable(L,T)
method insert(k,value)
/value := k
T[k] := value
put(L, value)
end
method lookup(k)
return T[k]
end
method gen_in_order()
suspend !L
end
initially(defaultvalue)
L := [ ]
T := table(defaultvalue)
end
So, this is a table, except it remembers the order in which its elements
are inserted. Like Java, because we don't have operator overloading, we
can't make it look exactly like a table...
procedure main(argv)
LT := listable(0)
every s := !argv do
LT.insert(s, LT.lookup(s)+1)
every x := LT.gen_in_order() do
write(x)
end
What is wrong with this picture?
Unicon Inheritance
Inheritance is when you can write one class as a subclass that gets much
of its data (fields) and code (methods) from another class.
- When writing a class, superclasses are just a colon (:) away
class Subclass : Super1 : Super2 (field1, field2)
...
end
- If you wanted to call your parents method from your own, overriding
method
class B : A (fields)
method M(x)
# possibly do stuff before calling parent M
self.A.M(x) # call parent M
# possibly do stuff after calling parent M
end
Inheritance in Unicon is closure-based.
- All the stuff you have in Subclass's own body comes first. Then you
rifle through your parents' bodies looking for spare change, and anything
else you can use. Any member variable or method not already defined is
sucked in from that superclass and added onto the end of what you've got
at present.
- works fabulously for any number of superclasses; superclasses are
visited in depthfirst fashion
Closure-based semantics gives the cleanest resolution of
multiple inheritance conflicts that I am aware of. Most of the time you do
not notice or care.
class fraction(numerator, denominator)
#methods here
initially
end
class inverse : fraction(denominator)
initially
numerator := 1
end
class sub : A : B(x)
initially
x := 0
self.A.initially() # calling parent method in overriding subclass method
self.B.initially() # self is implicit in most other contexts.
end
Unicon Tips from the Ghosts of Students Past
- procedures end with
end
- not { } as in C/C++/Java. Same goes for classes, methods
- && is not an "and" operator
- & is an "and" operator
- a generator only generated as much as its surrounding expression demands
- if it is not driven by "every", it may well stop at its first result
- if it is already a generator,
! won't make it more so
- rather, it will generally mess it up
- Can't just start assigning elements of an empty list
- After
L:=[], you will find that L[1] does not
exist yet. Create with elements via list(n) or put() or push() elements onto your list before you
try to subscript them.
lecture #31
Unicon: Graphics
2D
- Unicon has some of the world's easiest 2D graphics
-
w := open("window title", "g") opens a window
- inspired by the TRS-80 Extended Color BASIC graphics,
- influenced by the X Window System. (X11 and classic Mac and
Windows 2D APIs were all inspired heavily by the original
Xerox graphics workstations).
- although this was some of the first open source code I ever wrote,
it is still in wide use. UIdaho's Gigi Young is on the cusp of replacing
my original X Windows-based implementation of Unicon's graphics
with an OpenGL reimplementation.
The 3D facilities (open() mode "gl") are also
pretty darn simple. They are built atop (classic) OpenGL and have grown
to emphasize the use of textures over time.
- Q: When is "graphics" a programming language concept, and when is it
software engineering, operating systems, architecture, or mathematics?
- There are many answers.
- language vs. library.
- application layer vs. system layer.
- software vs. hardware.
- idea vs. implementation.
In Unicon, there is a built-in data type for graphics.
The VM / runtime system is doing graphics even when
you are not in a graphics function call. Perhaps
there should be more operators and
control structures for working with windows.
Main concepts of Unicon graphics:
- window = canvas + context
- a window is a binding of a drawable canvas and a set of drawing
attributes. For easy switching, you can have more than one set of
attributes bound to a given canvas at one time.
- canvas
- a canvas is a matrix of pixels you can draw on
- context
- a context is a set of attributes like color, font, linestyle, fill pattern...
-
"attribute=value" strings
- canvas and context have attributes that you can set
- pixels
- color/contents of a single dot
- coordinates
- (x,y) integer coordinates from (0,0) in the upper left
- colors
- (r,g,b) values, often specified by names
- fonts
- pixel fill patterns used to draw text in a particular style
- input processing and callback routines
- keyboard and mouse read from a single function. user interfaces
typically give control to a loop that reads this and then calls functions
- language level (built-in) tries to provide essential features
with simplest API possible, relatively complete programmer control
- built-in API consists of ~30 or 40 functions, instead 400-800. attribute strings, not hundreds
of new classes/record types.
- Unicon class (library) level features an extensive GUI, modern concepts
-
By way of saying hello, we submit this entry to Brad Myers'
"rectangle follows mouse" challenge.
procedure main()
&window := open("rfm", "g", "fg=blue", "drawop=reverse")
repeat {
e := Event()
case e of {
&ldrag | &mdrag | &rdrag : {
FillRectangle(\x, y, 10, 10)
FillRectangle(x := &x, y := &y, 10, 10)
}
"q" : exit(0)
}
}
end
For the sake of comparison, here is an application to render a simple
textured 3D scene.

procedure main()
&window :=open("textured.icn","gl","bg=black","size=700,700")
# Draw the floor of the room
WAttrib("texmode=on", "texture=carpet.gif")
FillPolygon(-7.0, -0.9, -14.0, -7.0, -7.0, -14.0,
7.0, -7.0, -14.0, 7.0, -0.9, -14.0, 3.5, 0.8, -14.0)
# Draw the right wall
WAttrib("texture=wall1.gif", "texcoord=0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0")
FillPolygon(2.0, 4.0, -8.0, 8.3, 8.0, -16.0, 8.3, -1.2, -16.0, 2.0, 0.4, -8.0)
# Draw the left wall
WAttrib("texture=wall2.gif")
FillPolygon(2.0, 4.0 ,-8.0, -9.0, 8.0, -16.0, -9.0,-1.2,-16.0, 2.0, 0.4, -8.0)
# Draw a picture
WAttrib("texture=poster.gif", "texcoord=0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0")
FillPolygon(1.0, 1.2, -3.0, 1.0, 0.7, -3.0, 1.2, 0.5, -2.6, 1.2, 1.0, -2.6)
# Draw another picture
WAttrib("texture=unicorn.gif", "texcoord=1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0")
FillPolygon(0.8, 2.0, -9.0, -3.0, 1.6, -9.0, 3.0, 3.9,-9.0, 0.8, 4.0, -9.0)
# Draw the lamp
WAttrib("texmode=off")
PushMatrix()
Translate(0.7, 0.20, -0.5)
Fg("emission pale weak yellow")
PushMatrix()
Rotate(-5.0, 1.0, 0.0, 0.0)
Rotate( 5.0, 0.0, 0.0, 1.0)
DrawCylinder(-0.05, 0.570, -2.0, 0.15, 0.05, 0.17)
PopMatrix()
Fg("diffuse grey; emission black")
PushMatrix()
Rotate(-5.0, 1.0, 0.0, 0.0)
Rotate( 6.0, 0.0, 0.0, 1.0)
DrawCylinder(0.0, 0.0, -2.5, 0.7, 0.035, 0.035)
PopMatrix()
PushMatrix()
Rotate(6.0, 0.0, 0.0, 1.0)
DrawTorus(-0.02, -0.22, -2.5, 0.03, 0.05)
PopMatrix()
PopMatrix()
# Draw the table
WAttrib("texcoord=auto", "texmode=on", "texture=table.gif")
PushMatrix()
Rotate(-10.0, 1.0, 0.0,0.0)
DrawCylinder(0.0, 0.2, -2.0, 0.1, 0.3, 0.3)
PopMatrix()
PushMatrix()
Translate(0.0, -0.09, -1.8)
Rotate(65.0, 1.0, 0.0, 0.0)
DrawDisk(0.0, 0.0, 0.0, 0.0, 0.29)
PopMatrix()
WAttrib("texmode=off", "fg=diffuse weak brown")
PushMatrix()
Rotate(-20.0, 1.0, 0.0,0.0)
DrawCylinder(0.0, 0.2, -2.2, 0.3, 0.1, 0.1)
PopMatrix()
while (e := Event()) ~== "q" do {
write(image(e), ": ", &x, ",", &y)
}
end
lecture #32
Class today included a discussion of using a list of strings representation
for a maze, inserting a room by modifiying the list of strings, semantics
of strings (immutable, but easy to build new strings and replace old ones),
and the Unicon random number operator, unary ?, which was used to generate
random number between 1 and N (?N) as well as select a random element out of
a list of strings (?L).
lecture #33
Some Q&A and then...
Unicon: Networking
Unicon has some of the world's easiest internet client and server facilities.
There are basic TCP and UDP protocols accessed via open() mode "n" and "nu",
and there are several higher level internet protocols such as HTTP and POP
that are accessed via open() mode "m".
Main concepts:
- client vs. server
- client == app that opens the connection. server == app that receives
connection requests
- slow, reliable and ordered (TCP) vs. fast (UDP)
- btw UDP is unreliable, unordered
- hostnames, IP #'s, and ports
- DNS, IPv4 vs IPv6...
- synchronous/blocking vs. asynchronous, non-blocking I/O and timeouts
- how long do you want to wait?
- dropped connections and widely varying delays
- modern WAN is ugly
- multiplexing and select()
- what happens when you have multiple users?
- built-in higher level messaging (HTTP, SMTP, etc.)
- internet is built on hundreds of protocols (on top of TCP or UDP).
which ones should be built-in?
lecture 34
Network Demo
We gloriously demoe'ed serv.icn and
client.icn.
Discussion of Scoping Rules, Suspend
suspenddemo.icn
- undeclared variables are local...unless some other module that you link in
declares them to be global!
- Local by default works well for small programs. For larger programs it is
wise to declare your variables.
- Do Unicon programmers actually use suspend? ~29x in uni/unicon/*.icn;
over a hundred in ipl/procs/*.icn. But plenty of programs don't.
- Discussion and examples of user-defined generators, written using suspend
lecture 35
Y'all saw the small HW extension, did ya?
Reading Assignment
- We are starting Java on Monday.
- Read Webber Ch. 13 A First Look at Java
Backtracking Control vs. Data
- When an expression fails and control resumes the most recently-suspended
generator in Unicon, you are "undoing" some amount of control
flow and
execution (restoring program counter and stack registers, etc).
- For the most part, Unicon does *not* undo data: assignments to variables,
inserts into sets, tables or lists, etc. are not undone when failure
happens.
- The ONLY automatic undo-ing of data on failure in Unicon are
- reversible assignment operator, e.g.
x <- expr
- string scanning subject and position
- For the rest (such as board configurations in games), you would have
to manage your data backtracking
- Easiest: copy-on-modify (i.e. original easy to restore, it never changed)
- Alternative: save value before change, make change and suspend, restore
value after resumption. Example:
procedure tic_tac_toe(L, x, y, mymove)
local old := L[x][y]
suspend L[x][y] := mymove
L[x][y] := old
end
- Co-expressions are synchronous independent computations
- They have their own stack; take turns at the CPU.
- You can call them co-operative "lightweight" threads;
they are akin to "goroutines" if you like Go, except...
- They are fine-grained, expression-level, and can produce
results for the caller by both implicit and explicit
activation.
- Unicon also has true concurrent threads, unlike most scripting languages.
- Main (research) purpose of co-expressions:
encapsulate a generator so it can be used a
piece at a time, from different locations in source code.
- Dr. J's added secondary purpose: allow 2+ programs to run in the same VM instance.
Threads
- "Turn co-expressions loose": spawn(coexpr)
- True concurrency vs. pseudo-concurrency
- True concurrency is expensive
- Synchronization and communication costs
- Described in the Unicon book and in UTR14, both at unicon.org.
thread write(1 to 3)
is equivalent to
spawn( create write(1 to 3) )
The usual problem with a thread is: you aren't waiting for it to be done,
and you can't even tell when it finishes. Well, assign it to a variable
and you can at least do that much.
mythread := thread write(1 to 3)
...
wait(mythread)
waits for a thread to be done.
Typically, a thread has some work (data structure) and an id passed into
some function. After the thread is finished, the results will have to be
incorporated back into the main computation somehow
t1 := thread sumlist(2, [4,5,6])
...
procedure sumlist(id, L)
s := 0
every s +:= !L
#... can't easily just "return" the value
end
The classic way threads might communicate is: global variables!
But these have race conditions. Alternatives include
files or pipes or network connections (all slow), or an extra
language feature, but first: how to avoid race conditions.
global mtx
mtx := mutex()
...
critical mtx: expr
is equivalent to
lock(mtx)
expr
unlock(mtx)
Another way to avoid race conditions in Unicon is to use a "mutex'ed" data
structure, as in
L := mutex([])
There are also thread-based versions of the activate operator:
four or eight of them:
| @> | @>> | <@ | <<@
|
| send | blocking send | receive | blocking receive
|
They follow this (weird) model:
There is more to concurrency: condition variables, private channels...
this was just your gentle introduction. See UTR14 for more.
A Unicon Thread Story
Real Life intrudes upon our tender classroom...
- a plea from a friend
- toxline-dedup is a Very Simple Program
- Purpose: remove duplicates in a gigantic data source.
- It had to be run once a month on a datafile that grew a bit each month,
so far, 800+ MB
- Runtimes were out-of-this-world slow! Several hours!
- ...and getting worse, fast.
- Many ways to speed up (faster algorithm? optimizing compiler?)
- Let's try threads
- Except, it looks like each iteration depends on all previous?
- 3 thread version divides work into reader, a
processor, and a writer.
- Fixes nothing. Makes it worse.
- I/O is not the problem. Read 800+MB in < 1s
- Think more deeply about how to divide work up into many chunks.
- Devise massive threaded solution
- While debugging the (much more complicated) threaded version, realize
the real problem and fixed it (improve Unicon's table data type).
- In the process of working with the customer, find bugs in threads
(improve Unicon's concurrency facilities).
- End result: from 2+ hours to ... 22 seconds.
Discussion of Sort Module
The Icon Program Library sort module handles more exotic sorting needs
than those of the built-in sort().
We have an example to consider,
but we almost have to get some more core data types and control structures
covered in order to appreciate it.
Bits of Icon/Unicon Wisdom
- Possibly the most useful type of all is the table. Have you used it yet?
- !t is ok, but I seem to use key(t) a lot.
- Actually learning string scanning is wise. Some of you have.
- Records and classes are technically all public. Privacy is a convention,
like in a public bathroom, not like in an isolation wing of a prison.
- You can easily get the names of all the fields and methods. You can
easily get the superclasses, overwrite/replace a method, etc.
- Knowing all your generators is prudent. There are surprisingly few in
classic Icon. Many of these are for string scanning.
! (bang), |, i to j, i to k by k, seq(), key(), find(), upto(), bal().
-
Unicon adds some more generators, mainly its high-powered monitoring facility.
keyword(), structure(), globalnames(), paramnames(), staticnames(),
localnames(), fieldnames(), function(), istate(), WAttrib().
- Knowing your fallible expressions is prudent.
:= (design flaw, &pos only), <-, <->, :=:, ?, [], [:], \, /
<, <=, >, >=, ~=, =, ==, ===, ~==, ~===, etc.
string(), numeric(), cset(), integer(), real(), proc(), loadfunc(), args(),
serial(), move(), pos(), tab(), any(), many(), match(), get(), pop(),
classname(), oprec(), member(), pull(), getenv(), open(), read(), reads(),
remove(), rename(), save(), seek(), where(), getch(), getche(), kbhit(),
chdir(), delay()
- Graphics facilities fallible expressions.
Active(), Bg(), Color(), ColorValue(), CopyArea(), Couple(), DrawImage(),
Fg(), Font(), NewColor(), PaletteChars(), PaletteKey(), Pending(), ReadImage(),
WDefault(), WriteImage().
- Windows Native fallible expressions.
WinAssociate(), WinPlayMedia(), WinButton(), WinScrollBar(), WinMenuBar(), WinColorDialog(), WinFontDialog(), WinOpenDialog(), WinSelectDialog(), WinSaveDialog()
- Unicon adds more fallible expressions.
variable(), cofail(), EvSend(), EvGet(),
sql(), dbcolumns(), dbdriver(), dblimits(), dbproduct(), dbtables(), fetch(),
PlayAudio, sys_errstr(), getppid(), getpid(), link(), symlink(), readlink(),
kill(), trap(), chown(), chmod(), chroot(), rmdir(), mkdir(), truncate(),
flock(), fcntl(), utime(), ioctl(), filepair(), pipe(), fork(), fdup(),
exec(), system(), getuid(), geteuid(), getgid(), getegid(), setuid(),
setgid(), getpgrp(), setpgrp(), crypt(), umask(), wait(), name(),
gettimeofday(), lstat(), stat(), send(), receive(), select(), getpw(), getgr(),
gethost(), getserv(), setpwent(), setgrent(), sethostent(), setservent(),
ready(), syswrite(), setenv().
- One of the most important additions to Icon occurs in the open() modes.
It is not just that there are many I/O modes supported but they are generally
as easy to use as local files.
| mode | meaning
|
|---|
| "r" | read (default)
|
| "w" | write
|
| "a" | append
|
| "c" | create
|
| "p" | pipe
|
| "g" | 2D graphics
|
| below this point, Unicon only
|
| "n" | network (Internet, TCP/UDP)
|
| "gl" | 3D graphics (OpenGL)
|
| "d" | DBM database
|
| "o" | ODBC (SQL) database
|
| "z" | libZ compression
|
| "m" | messaging (http://, pop://, etc.)
|
Things I love about Icon and Unicon
Yeah, this list isn't complete...
- x1 < y < x2
- ranges the way I saw them back in math class
- lists and tables
- the most convenient data structures building blocks in any language
- !L === x and P(!L) and such
- the most convenient algorithms building blocks in any language
- open() and friends
- the most convenient graphics and network I/O in any language
Things I hate about Icon and Unicon
- Run-time errors that have &null values because of typos
- compiler option -u helps but isn't a cure-all
- Run-time errors that have &null values because of surprise failure
- if's are needed to check for failure...in a large percent of expressions
- Computational accidents because of surprise generators
- some things were never meant to be backtracked-into.
- the language is slow
- from time to time I get help from students interested in fixing this
- the IDE is immature
- many Bothan spies died to bring you this IDE.
OOP Lessons from the Unicon Class Libraries
The unicon distribution is basically an Icon with an extensively modified VM,
plus a uni/ directory that looks like
3d/ guidemos/ iyacc/ Makefile progs/ ulex/ unidoc/
CVS/ ide/ lib/ native/ shell/ unicon/ util/
gui/ ivib/ makedefs parser/ udb/ unidep/ xml/
We can't cover all the libraries in a single lecture, but we can learn
about objects from some of the highlights.
Extra Credit Unicon
Some folks have asked for extra Unicon work, either for extra credit, or for
your own reasons. I am willing to entertain proposals, and it is always
true that I am looking for Unicon talent. Here are some stray ideas:
- Re-do an earlier HW in Unicon, possibly cooler (Unicon- or Vandal-themed?).
- Write a program that, given the name of a built-in function foo,
reads in http://unicon.org/utr/utr8.html, finds the anchor for foo, and prints
out the header information for that function, e.g.
"write(s|f, ...) : string|file"
- Write a Unicon program that, given an input program source file foo.icn,
draws its procedure call graph, the graph that shows which procedure calls
which.
- Write a Unicon program that, given an input program source file foo.icn,
detects and complains if the program contains an every loop that obviously
should be a while loop, or a while loop that obviously should be an every loop.
- Write a program of your own devising that lets you play with one or more
of:
- user-defined generators
- classes
- graphics and GUI's
- networking
- threads
- Write a Unicon program that has some real-world value to someone.
Such an exercise should not be undertaken at the expense of any current or
future 210 homework, but may be awarded extra credit proportional to its
size and features.
Unicon Scope Rules
1. Local overrides global
2. If you have classes, and member functions, where do they fit?
3. If you don't have to declare variables, are they local, or global, or class?
4. By the way, there exists dynamic scope versus static scope.
global x
class C ( x, y)
method g()
write(x)
end
method f()
(let x
g()
)
end
end
Semantics
Semantics, as you may recall, means is the study of what something means.
Attributes
It is tempting to use the heavily-overloaded term attributes when
talking about
semantic properties that a compiler or interpreter would know about a name in
order to apply its meaning in terms of code. When we talk about lexical
analysis we have lexical attributes, when we talk about syntax we have
syntactic attributes (which can build on or make use of lexical attributes),
and when we talk about semantics, we have semantic attributes (which can
build on or make use of lexical and syntactic attributes).
Cheesey example:
double f(int n)
{
...
}
In order for any code elsewhere in the program to use f correctly,
it had better know what attributes?
- its name, f
- the fact that it is not a variable
- the fact that it is a function
- its number of parameters and their types
- its return type
So for example, if the input included somewhere later in the program
x = f('\007');
The compiler can check whether this call to f() makes sense.
It can check that the # of parameters is correct, generate code that promotes
the character parameter to an integer, check that the variable x is
compatible with return type double, and generate code for any
conversion that is required in assigning a double to x.
Environment and State
Environment maps source code names onto storage addresses (at compile time),
while state maps storage addresses into values (at runtime). Environment
relies on binding rules and is used in code generation; state operations
are loads/stores into memory, as well as allocations and deallocations.
Environment is concerned with scope rules, state is concerned with things
like the lifetimes of variables.
|
| --(scope)-->
|
| --(binding)-->
|
| --(state)-->
|
|
| ---------- | ---------------- | (environment) | ------------------ | ------------
|
Scopes and Bindings
Variables may be declared explicitly or implicitly in some languages
Scope rules for each language determine how to go from names to declarations.
Each use of a variable name must be associated with a declaration.
This is generally done via a symbol table. In most compiled languages
it happens at compile time, but interpreters will build and maintain
a symbol table while the program runs.
A few comments about Nested Blocks
Different languages vary as to how they do nesting of blocks and variable
declarations. Semantics has to map names to addresses, and
it can be confusing especially when the name name is "live" with different
memory locations at the same time ... in different scopes.
- some languages don't allow nesting at all
- algol-based languages generally nest syntactically, usually at the
function level.
- C-like languages don't allow functions to nest, but do allow local
blocks
- some major languages nest blocks at runtime (e.g. Lisp). This can
lead to some wild and woolly situations.
- in modern languages, classes and packages/namespaces matter; can they nest? (depends on the language)
Symbol Tables
Symbol tables are used to resolve names within name spaces. Symbol
tables are generally organized hierarchically according to the
scope rules of the language. Although initially concerned with simply
storing the names of various that are visible in each scope, symbol
tables take on additional roles in the remaining phases of the compiler.
In semantic analysis, they store type information. And for code generation,
they store memory addresses and sizes of variables.
Runtime Memory Regions
Operating systems vary in terms of how the organize program memory
for runtime execution, but a typical scheme looks like this:
| code
|
|---|
| static data
|
|---|
| stack (grows down)
|
|---|
| heap (may grow up, from bottom of address space)
|
|---|
The code section is usually read-only, and shared among multiple instances
of a program. Dynamic loading may introduce multiple code regions, which
may not be contiguous, and some of them may be shared by different programs.
The static data area may consist of two sections, one for "initialized data",
and one section for uninitialized (i.e. all zero's at the beginning).
Some OS'es place the heap at the very end of the address space, with a big
hole so either the stack or the heap may grow arbitrarily large. Other OS'es
fix the stack size and place the heap above the stack and grow it down.
Much CPU architecture has included sophisticated support for making the
stack as fast as possible, and more generally, for making repeated and
sequential memory accesses as fast as possible. This sort of ideally
fits C and Pascal (i.e. traditional "structured" imperative programming)
and performs pathologically poorly on Lisp (functional) and OOP
languages that exhibit poor locality of reference, exaggerating the
already extreme speed differences between medium-level languages and
very high level languages. Hardware that eschews caches in favor of
"more cores" are not as biased.
Allocation and Variable Lifetimes
Since around 80% of the time spent debugging programs written in systems
programming languages is spend debuging memory management problems, and
since around 67% of total software development costs are spent in debugging
and software maintenance, it can be argued that understanding memory
allocation and variable lifetimes is the single most important thing for
you to master as you move past the "novice" level of programming skill.
Activation Records
Activation records organize the stack, one record per method/function call.
| return value
|
| parameter
|
| ...
|
| parameter
|
| previous frame pointer (FP)
|
| saved registers
|
| ...
|
| FP--> | saved PC
|
| local
|
| ...
|
| local
|
| temporaries
|
| SP--> | ...
|
At any given instant, the live activation records form a chain and
follow a stack discipline. Over the lifetime of the program, this
information (if saved) would form a gigantic tree. If you remember
prior execution up to a current point, you have a big tree in which
its rightmost edge are live activation records, and the non-rightmost
tree nodes are an execution history of prior calls.
Garbage Collection
Automatic storage management plays a prominent role
in most modern languages; it is one of the single most important features
that makes programming easier.
The Basic problem in garbage collection: given a piece of memory, are there
any pointers to it? (And if so, where exactly are all of them please).
Approaches:
- reference counting
- traversal of known pointers (marking)
- copying (2 heaps approach)
- compacting (mark and sweep)
- generational
- conservative collection
Supplemental Comments on Imperative Programming
Imperative programming is programming a computer by means of explicit
instructions. Assembler language uses imperative programming, as do C,
C++, and most other popular languages.
One way to think of imperative programming is that it is any programming
in which the programmer determines the control flow of execution. This
might be using goto's or loops and conditionals or function calls.
It contrasts with declarative programming, where the programmer specifies
what the program ought to do, but does not determine the control flow.
Def: a program is structured if the flow of control through
the program is evident from the syntactic structure of the program
text. "evident" means single-entry/single-exit.
Common constructs in imperative programming include:
- sequences of statements; compound statements
- selection statements
- looping statements
- function call and return
Assertions, invariants, preconditions, and postconditions
The problem with imperative programming is: you know you told the computer
to do something, but how do you know that you told it to do what you want?
In particular, people write code that behaves differently than they intend
all the time. We reason about program correctness by inserting logical
assertions into our code; these may be annotations or actual checks at
runtime to verify that expected conditions are true.
Curly brackets {expr} are often used to enclose assertions, especially among
former Pascal programmers; another common convention is assert(expr), which
is a macro available in many C compilers.
A precondition is an assertion before a statement executes, that defines
the expected state. It defines requirements that must be true in order
for the statement to do what it intends. A postcondition is an assertion
after a statement executes that describes what the statement has caused
to become true. An invariant is an assertion of things that do not change
during the execution of a statement. An invariant is particularly useful
with loop statements.
while x >= y do
{ x >= y if we get here }
x := x - y
suppose {x >= 0 and y > 0} is true. Then we can further say
{ x >= y > 0} inside the loop. After the assignment, a different
assertion holds:
{ x >= 0 and y > 0}
while x >= y do
{ y >= 0 and x >= y }
x := x - y
{ x >= 0 and y > 0 }
While these kinds of assertions can allow you to prove certain things about
program behavior, they only allow you to prove that program behavior
corresponds to requirements if requirements are defined in terms of formal
logic. There is a certain difficulty in scaling up this approach to handle
real-world software systems and requirements, but there is certainly a great
need for every technique that helps programmers write correct programs.
lecture 36
Announcements
- HW#5 (Java) is posted.
Bring your questions to a discussion about it
next class.
- I would like more participation for this
unit; please ask and answer more questions!
Java
One popular representative modern object-oriented language is Java.
- Compared to C++ or Unicon's OOP, Java attempts to be more pure,
even when it hurts.
- All code is in classes, even when it makes no sense
- No multiple inheritance, even when it would make sense
- Java is not are pure OO as SmallTalk -- it has non-object scalar
types, and a non-object array type.
You don't add two numbers by sending the first number a message.
Reading Assignment
- Read Webber Chapter 13.
- Read and "do" the
Java Tutorials Trails, Covering the Basics #1-4 and #6: Getting Started,
Learning the Java Language, Essential Java Classes, Collections,
and Deployment.
Compiling and Running Java Locally on cs-210.cs.uidaho.edu
Add the following to your ~/.profile, and/or your ~/.bashrc file. They
specify the sizes of Java's heap memory region. By default Java asks for
a size that fails on some CS instructional machines!
alias java="java -Xmx20m -Xms10m"
alias javac="javac -J-Xmx20m"
These aliases should be placed in your ~/.profile or possibly ~/.bashrc file.
You may have to "source" the file that you place them in order for the current
shell session to see those aliases, but in subsequent logins they should just
be there for you automatically since shells autoload such commands.
Once you have your aliases setup,
compile with "javac hello.java" and run with "java hello"
Example #0
This example hello.java is
tailored to show you a couple things Webber might not:
random numbers from java.util and the command
line arguments passed into main().
lecture 37
I am gonna try to do a little bit of my own lecture material, plus a bit of
Webber every day.
Things to Learn About Java Today
-
javac -Xlint helps by being extra picky,
reports more warnings
- "static" methods are our first Bad Java Habit
- Java is Schizophrenic: each class can have it own main() !?
Only one gets
invoked when you run Java, based on which class name is given then
- C is 80% language and 20% libraries. While the Java language is only
somewhat (33%?) larger than C, Java is 20% language and 80% libraries.
As these fake and made-up numbers clearly prove, the learning curve
and time investment needed to learn Java is much larger compared with C.
But sure, Java is "easier" conceptually.
- Java is the "COBOL" of modern enterprise computing, LOL.
- Can't do anything in Java without packages. Start with java.lang and
java.util. Probably have to survey them, learn details on demand.
- This means Java needs a good IDE far more than C or C++ do.
- do you know the term "method" yet? In C++ it is a "member function"
- Unlike C++ with its public: private: protected:, in Java you don't use
a colon and do mark every single variable's/method's visibility. Ugh.
- Modern Java has "type parameters". They are in
<brackets> and are used heavily in collection classes
in order to provide polymorphism while checking all types and compile
time.
- Modern Java has "lambdas", sort of. Instead of being anonymous
functions that can be stored in variables or passed as parameters,
since Java has nothing but classes, it fakes lambdas using anonymous
classes with just one function in them. LOL.
Java is an Almost-SmallTalk?
A few languages (mainly SmallTalk) have aimed to be "pure OO", meaning that
everything down to basic integers and characters are objects. Most languages
don't go that far -- Java for example has built-in types like "int" and
constructs like arrays, but then very quickly you are forced to use
system classes, and encouraged to organize your own code with classes.
So, it isn't about whether you will use classes a lot in Java, like it would
be in C++. It is: how are you going to map your application domain onto a
set of (built-in system, or new written-by-you) classes? For many problems,
this is a natural fit, but for other problems it is silly and awkward.
When to OOP?
When you use a language where OOP is optional, go OOP under two (2)
circumstances:
- your application domain maps naturally onto a set of classes, or
- your problem is so large that you will have trouble wrapping your
brain around the whole thing.
In other words: OOP becomes more and more useful as your program size
grows.
An Example of Bad OOP in Java
- A Lisp HW in Java
- Sure you can use Java to write recursive Lisp functions. But if your
class is a set of unrelated functions that do not share state, it is pretty
bad OOP.
Webber's Java Slides
We got through slides 1-26.
lecture 38
Java Concepts (and APIs) to Learn Today
These topics feel like they are "out of order", but they are presented
because you may need them sooner than you think, in your homework. Part
of Java's imperfection is that in order to do basic things in Java you need
various advanced concepts.
- System.getenv()
- Basics of exception handling
- reading line-oriented input with BufferedReader
IO: the next steps
Exception Basics
Webber's Java Slides
lecture 39
Mailbag
-
I am currently trying to compile and run my Java program using javac and java, but it is throwing the following error message,
Error occurred during initialization of VM
Could not allocate metaspace: 1073741824 bytes
Is there any way to fix this?
- Java is trying to ask for a billion-and-some bytes, and failing.
With a platform issue, I will want to know what machine and OS you are
trying; I'll guess maybe it is cs-210.cs.uidaho.edu.
If the following do not help, let me know:
alias java="java -Xmx20m -Xms10m"
alias javac="javac -J-Xmx20m"
Another Look at the 3 Pillars of Object Orientation
What does it mean to think object-orientedly?
As a young computer scientist, I read and believed that object-orientation
consisted of:
encapsulation + polymorphism + inheritance
Each of these terms is important to this course.
- encapsulation
- closely related to information hiding,
this is the idea
that access to a set of related data can be protected and controlled,
so as to avoid bugs and ensure consistency between different bits of
data.
This concept has been mathematically expressed in the notion of an
Abstract Data Type (ADT), which is a set of values and a set of
rules (operations) for manipulating those values.
In programming languages, it is provided by a class or module construct.
- polymorphism
- Literally meaning "many shapes" or more loosely "shape changing",
this idea is that if you write an algorithm in terms of a set of
abstract operations, that algorithm can work on different data types.
It occurs in some languages as templates (C++), generics (Ada),
interfaces (Java), by passing functions as parameters (C),
or simply going with a flexible, dynamic type system (Lisp).
- inheritance
- By analogy to biological inheritance of traits or genes, inheritance
is when you define a class in terms of an existing class.
Encapsulation
Write functions (a la functional programming) around collections of related
data. By convention or language construct, hide/protect that (private)
data behind a set of public interface functions.
This is the single
most important principle of OOP. It is more than just saying "class" a few
times in each program. It is usually well-supported in any OO language.
The potential abuse comes from the encumbrance of too much required syntax
which distracts programmers from the actual problems they need to solve.
Algorithms written to use an encapsulated object and access it only via its
interface functions will not mind if you totally rewrite its innards to fix
it, make it faster, etc.
Polymorphism
Algorithms written to use an encapsulated object and access it only via its
interface functions will not mind if you totally substitute other types of
objects, including unrelated objects that implement the same interface.
Dynamic OOP languages usually support this well. Static OOP languages usually
support polymorphism somewhat awkwardly, as is the case of C++ templates.
Inheritance
The major difference between OO languages and other languages with strong
information hiding encapsulation is inheritance. Inheritance can mean:
starting with generic code, and augmenting it gradually with special cases
and extra details. There is abstract vs. concrete inheritance, and
parent-centric vs. child-centric inheritance. There is multiple inheritance.
The above concepts are important and useful. They are what object-oriented
programming languages typically try to directly support. However, they do
not tell the whole story, and programmers who stop there often write bad
OO code.
Webber's Java Slides
lecture 40
Announcements
- Reading assignment: Webber book page 15 and 17
- Final exam announcement: instead of a final exam at the scheduled
time of Tuesday May 12 from 8-10am, the final will be a take-home final.
It will be posted by 5:00pm on Monday May 11 and due by 11:59pm on
Tuesday May 12, e.g. you will have approximately 31 hours to do it.
It will be open book and open notes. There will be a review on Friday
May 8.
- Friday's lecture will be delivered from on the road. If, heaven forbid,
my internet were to fail, your mission would be to spend that hour
working forward on Java through self study.
- Friday's office hours will be cancelled. I will be reading e-mail from
the road, and will accept and schedule appointment requests, but they
may need to be in the evening or next week.
lecture 41
We finished Chapter 15 and started Chapter 17.
lecture 42
Welcome to Dead Week
Two more lectures, plus a final exam review day!
Object-oriented Thinking: Design-centric Viewpoint
The best way to think object-orientedly is to think of the computer
program as modeling some application domain. The model of the application
domain is the heart of the software design for any program that
you write, so the best way to think object-orientedly is from a software
engineering perspective, constructing the pieces that the customer needs
in order for this program to solve their problems.
- simulate entities
object-oriented code models "entities" -- things or ideas that must
be approximated in some application domain. Entities could be cars
or monsters or bank accounts or employees or ...
- add controllers
controllers are objects that implement rules, coordinate and enforce
consistency between entities, and so forth. They usually define the
tasks that users of the software will perform, and what steps are
needed to accomplish them.
- add boundary classes
boundary classes are objects that govern interactions between the
software and external entities: human users, files, network databases, etc.
- let objects be anthropomorphic
Anthropomorphism is when you see human-like traits in your objects.
You can often program objects more effectively if you think of them
like intelligent agents that have motivations, wants, needs and limitations.
- do method acting
Sometimes a good way to understand how to program your objects is to put
yourself in their shoes, and ask yourself to "be" network handler, or the
scrollbar, or whatever.
- make objects self-centered
Object-oriented code is most effective when it is written as close to the
data as possible. For example, if in my function I am calling function after
function on another object, maybe dozens of times, perhaps I should have
asked that object to do all that work for me -- by writing a method over in
that object's class.
- write abstract data types
Especially for application domain entities, it really makes sense
to characterize their behavior. It is not just: what are its functions?
It is: what sequence of function calls make sense for this kind of object?
- design first!
The biggest mistake OO programmers make is to start coding, without first
planning what you are going to do.
Back to Webber
lecture 43
CS 210 Java Exceptions Example: Hammurabi
A previous semester's CS 210 homework assignment was to use Java to write
the classic resource simulation program called Hammurabi, with local
extensions described below.
Hammurabi in a Nutshell
Hammurabi, the Babylonian king, is a visionary who advances western
civilization by introducing one of the earliest written codes of Law.
Hammurabi is also tyrant who wants to grow his
population to the largest possible size in order to be the most
powerful ruler on earth. In ancient mesopotamia there is a lot of
fertile land due to the annual flooding, but there are no defendable
borders and the only safety lies in numbers (of spears). To make
more people, you have to grow more food, which means you have to
plant more land, which takes more seed grain. And by the way, the
harvest yield varies from year to year, ranging from 0 to enormous.
But the more grain you store, the higher percentage of stored grain
is lost each year (rats, corruption, whatever).
The Hammurabi
simulation must report on current population and grain and land
holdings, and then ask Hammurabi each year:
- how many bushels to feed the people
- how many bushels of grain to plant for the next year
- how many acres of land to buy or sell @ 20 bushels per acre
Hammurabi: the Java Code
Sample code at
http://www.roseindia.net/java/java-tips/oop/q-hammurabi/q-pr-hammurabi-1.shtml was given as a starting point; its open source source files
were locally copied at
What to Learn About Java from the Hamurabi Code
There is some substantially interesting code there. What Java can we
learn from it?
- Code by delta (Δ refers to change)
- Whether you call it extension, modification, generalization, or filling
in the blanks, lots of Java programs are written by modifying existing
classes. Sometimes that means writing subclasses.
How much inheritance have you done so far in your programming?
- Object creation and method invocation
- Have you gotten the basic OO syntax of Java yet?
Is it any different from C++ so far? if so, how so?
- Wrapper Classes
- Java deals with its impurity by providing wrappers for non-class builtin
types. Java programmers should
know the basics of Integer, Double, Float, Short,
Long, Character, Boolean, Void, and Byte. Start with
the parse*() methods, e.g. Integer.parseInt(s)
- Did we say "No preprocessor"?
- Constant names get awkward:
private final static int POUND_DEFINE_WAS_SO_COOL = 1;
- Getters and setters = lame-o-OO
- But I guess setters are the ones that really bug me.
And I can live with them so long as they are controlled.
- Know how to (use) "swing"?
- javax.swing is a graphical user interface library. Most Java
applications might be written using this class library, unless they
are applets, or are written in JOGL or something like that.
- Graphical interface
- In order to run swing programs, you almost have to either install and
run Java on a local computer, or run on Linux machines in the lab. It is
possible run swing and other graphic programs on wormulon, but only if you
install an "X Window server" program on your local machine, and have an SSH
connection that does "X11 port forwarding". And that can be slow, especially
if you are not on campus. Avoid
using wormulon this way unless you have good reason.
- Who/what is JOptionPane?
- Minimally you should know its showInputDialog()
and showMessageDialog() methods.
Java Tips from the Past
- Don't use an object instance to invoke a static method.
- It would be more object-oriented to not use static methods at all, but
if you must use a static method, it is
CLASS.mystaticmethod(), not
instance.mystaticmethod()
- Do use templated collection typenames in constructors (after "new")
- ArrayList<String> names = new ArrayList<String>();
Using a Class to Make "Swing" Optional
When I first compiled and tried to run the hamurabi from roseindia.net,
I originally got:
> java hamurabi
Exception in thread "main" java.awt.HeadlessException:
No X11 DISPLAY variable was set, but this program performed an operation which requires it.
... long java runtime exception stack trace ...
- Hammurabi on Linux Java needs X Windows to run,
- IF your local machine (PC, Mac, etc) has the X11 X Windows "display
server" software running,
"ssh -X" or a similar option in your ssh client will let most
ssh remote hosts run graphics on your local machine.
If no X11 were available, what would a person do? Options include:
- Rewrite the game code to just use the console, skip the GUI
dialogs.
- Run locally, instead of running on the machine where we turn code in.
- Modify the game to ask whether a GUI is available, and use the console
when no GUI will work.
Option #3 has more options.
- Try and detect whether graphics are present, without using them, in order
to avoid the exception in the example.
- Just go ahead and try to use graphics, and if they fail, handle the
exception and enable the fallback.
At first I checked if the DISPLAY environment variable was set; if it
isn't, then we should use the console:
if (System.getenv("DISPLAY") == null) // ... use console
but that is not exactly portable -- on MS Windows no DISPLAY is needed.
So a better solution is to use an exception handler to catch that
fatal error we saw earlier, and revert to console IO:
use_swing = true;
try {
JOptionPane.showMessageDialog(null,
"Minister says we are swinging");
} catch (Exception e) {
System.out.println("Minister says we are using the console.");
use_swing = false;
}
Using Exceptions in OO Design
The try...catch statement allows Java to gracefully
recover from a runtime error and fall back to using the console when Swing
is not available. Where to put this code?
- not the Emperor (hamurabi class),
- nor the kingdom...
- it belongs in a boundary class that talks to the
human user, and it plays the role of the "prime minister" or perhaps
"interior minister" who talks to the emperor (the human user) each year.
At this point, our object-oriented version of Hammurabi looks like
the following picture:
----------we got this far in Spring 2020 before we ran out of time-------
About Inheritance
OOP experts will tell you that there are different kinds of inheritance:
abstract inheritance and concrete inheritance.
- abstract inheritance
- inheritance of a public interface, which is to say, a set of methods
with matching/compatible signatures. Abstract inheritance
is exactly that (sub)part of inheritance necessary for
polymorphism to work. This is the kind of inheritance
that says "if it looks like a duck, and walks like a duck, and
quacks like a duck, it is duck"
- A signature
- Is a function's prototype information: name, number and type of
parameters, and return type
- concrete inheritance
- concrete inheritance consists of inheriting actual code. This is
the kind of inheritance that says "a mallard is a kind of duck with
the following additional traits and behavior". While you might be
thinking and writing code about mallards right now, the more code you
manage to place in the duck class, or possibly a bird class above it,
instead of the mallard class, the
more "code sharing" you will see if you have many different kinds of
ducks or other kinds of birds later on.
Interfaces
Java has an explicit construct for abstract inheritance: Interfaces. From
the Java Tutorials we see:
interface Bicycle {
void changeCadence(int newValue); // wheel revolutions/minute
void changeGear(int newValue);
void speedUp(int increment);
void applyBrakes(int decrement);
}
This contains you no code. All it enables is that various classes can now
be declared to implement the interface as follows:
class ACMEBicycle implements Bicycle {
// remainder of this class
// implemented as before
}
This let's you write code that takes parameters of type Bicycle.
Such code will be inherently polymorphic, working with any classes that
implement the Bicycle interface.
Concrete Inheritance
Java has a limited, simple form of concrete inheritance. Suppose you have a
nice generic bicycle class implemented:
public class Bicycle {
public int cadence, gear, speed;
public Bicycle(int startCadence, int startSpeed, int startGear) {
gear = startGear; cadence = startCadence; speed = startSpeed; }
public void setCadence(int newValue) { cadence = newValue; }
public void setGear(int newValue) { gear = newValue; }
public void applyBrake(int decrement) { speed -= decrement; }
public void speedUp(int increment) { speed += increment; }
}
For any number of customized, specialty bicycles, you might want to start
by saying "they behave just like a regular bike, except ..." and then give
some changes. In Java you declare such a subclass with the extends
reserved word:
public class MountainBike extends Bicycle {
public int seatHeight; // subclass adds one field
// overrides constructor, calls superclass constructor
public MountainBike(int startHeight, int startCadence,
int startSpeed, int startGear) {
super(startCadence, startSpeed, startGear);
seatHeight = startHeight;
}
public void setHeight(int newValue) { // subclass adds one method
seatHeight = newValue;
}
}
Two ways to check whether your Bicycle is a mountain bike
-
MountainBike mb = (MountainBike)b;
-
if (b instanceof MountainBike) ...
But note that usually if you were going to say:
if (b instanceof MountainBike) b.doMountainyStuff()
else if (b instanceof RacingBike) b.doRacingStuff()
...
you'd be more object-oriented, and more efficient, to be defining a method
doStuff and having each class override it, so you can just say
b.doStuff()
Arrays Example
Have you seen this syntax enough to be familiar with it yet?
int[] anArray;
anArray = new int[10];
Note: an array's size is permanently decided at construction time!
If you want a growable array, look to class Vector.
Also, be sure you can recognize (and write) code like:
int[] anArray = {100, 200, 300, 400, 500, 600, 700, 800, 900, 1000};
Arrays are not objects, but they have (at least) one field: anArray.length
gives the array's size.
Strings versus arrays of char
Strings really are not arrays of char. Consider this example:
public class hello {
public static void main(String[]args){
String s = "Niagara. O roar again!";
char c = s[9];
System.out.println("10th char of "+s+" is "+c);
}
}
You have to say s.charAt(9) instead of s[9].
More on the Java String class
Be sure you know at least this much:
- static method String.valueOf(x)
- overloaded 9 times, produces string representation of x
- static method String.format(formatstr, objs...)
- returns a formatted string, a la printf
- s.length()
- s.indexOf(c) and s1.indexOf(s2), lastIndexOf
- similar to strchr, strstr
- s1.compareTo(s2) and s1.compareToIgnoreCase(s2)
- + and s1.concat(s2)
- s.matches(String regex)
Note: Java was arguably the first major language to be Unicode-based.
How does this impact the string type?
Java Trails Commentary
Do the required online reading of the
Trails Covering the Basics!
Be sure you know about:
- JavaDoc
- Know what /** */ comments are for, and be able to give examples.
- JavaBeans
- This component technology seems to be famous or important. For what?
- applets
- What are applets, and how do I write one?
- NetBeans
- What is NetBeans good for?
- Java's byte vs. char types
- What is the difference? What's with those '\uffff'-style char literals?
JavaDoc
Who it is for: large scale software system builders.
What it does: write out a collection of webpages to help "navigate" your
Java class libraries.
Big success, inspired numerous copycats!!
Writing Doc Comments [from Oracle documentation]
A doc comment is written in HTML and must precede a class, field, constructor or method declaration. It is made up of two parts -- a description followed by block tags. In this example, the block tags are @param, @return, and @see.
/**
* Returns an Image object that can then be painted on the screen.
* The url argument must specify an absolute {@link URL}. The name
* argument is a specifier that is relative to the url argument.
*
* This method always returns immediately, whether or not the
* image exists. When this applet attempts to draw the image on
* the screen, the data will be loaded. The graphics primitives
* that draw the image will incrementally paint on the screen.
*
* @param url an absolute URL giving the base location of the image
* @param name the location of the image, relative to the url argument
* @return the image at the specified URL
* @see Image
*/
public Image getImage(URL url, String name) {
try {
return getImage(new URL(url, name));
} catch (MalformedURLException e) {
return null;
}
}
printf / Math
Note the %n, which may write out \n, \r, or \r\n depending on which platform
you are on. The Math class methods are static; the System.out methods are
not.
public class BasicMathDemo {
public static void main(String[] args) {
double a = -191.635, b = 43.74;
int c = 16, d = 45;
double degrees = 45.0, radians = Math.toRadians(degrees);
System.out.printf("The absolute value of %.3f is %.3f%n",
a, Math.abs(a));
System.out.printf("The ceiling of %.2f is %.0f%n",
b, Math.ceil(b));
System.out.format("The cosine of %.1f degrees is %.4f%n",
degrees, Math.cos(radians));
}
}
To get at the Math static functions without having to say "Math." all the time,
use "import static":
import static java.lang.Math.*;
public class BMD {
public static void main(String[]args)
{
System.out.printf("Hello, world %.3f%n", ceil(3.14159));
}
}
Note however from stackoverflow:
If you overuse the static import feature, it can make your program
unreadable and unmaintainable.
More on Exceptions
Three kinds:
- checked
- probably recoverable. catch-or-specify required
- error
- you can catch it, but you probably can't recover. problem outside the app.
- runtime
- you can catch it, but you probably can't recover. problem inside the app,
i.e. a bug that needs to be fixed.
Observation Regarding Exceptions
-
You can catch more than one type of exception on a single try block; it is
a bit like a switch statement, or more accurately, like a series of "else-if"
tests.
- The types of exceptions must either be mutually exclusive,
or else work their way from more-specific-first to more-general.
- You can explicitly throw
(cause) your own exceptions, including new kinds that you define
yourself.
- "throw" is followed by "new" applied to the constructor
for the type of exception.
try {
out = new PrintWriter(new FileWriter("OutFile.txt"));
for (int i = 0; i < SIZE; i++) {
out.println("Value at: " + i + " = " + list.get(i));
}
} catch (FileNotFoundException e) {
System.err.println("FileNotFoundException: " + e.getMessage());
throw new SampleException(e);
} catch (IOException e) {
System.err.println("Caught IOException: " + e.getMessage());
}
By the way, if you don't handle an exception (no "catch"),
you can still use a try { } block to document that you know
an exception may occur there.
Also, a finally clause will execute at the end of a try
block whether an exception is handled or not.
static String readFirstLineFromFileWithFinallyBlock(String path)
throws IOException {
BufferedReader br = new BufferedReader(new FileReader(path));
try {
return br.readLine();
} finally {
if (br != null) br.close();
}
}
JAR files
java archive file format bundles multiple files (usually .class files) into
a single archive. They are really ZIP files, but the jar command-line
program uses commands similar to the classic UNIX tar(1) command.
Unlike C/C++,
Java does not have a "linker" that resolves symbols at "link time" to produce
an executable. Symbols are resolved at "load time" which is generally the
first time that a class is needed/used, often during program
startup/initialization. This can mean that Java programs are slower to start
than native code executables, but it does provide a certain flexibility.
Since Java does not have a linker, JAR files are the closest approximation
that it has: a Jar archive can bundle a collection of .class files as one
big file that can be run directly by the java VM (using the -jar option).
To build a JAR that will
run as a program, you specify the options "cfe", the name of which class'
main() function to use at startup, and the set of class files:
jar cfe foo.jar foo foo.class bar.class baz.class
java -jar foo.jar
The options cfe stand for "create" a "file" with an "entrypoint".
Separate Compilation and Make
You might have seen the world-famous and ultra-fabulous "make" tool already.
If you already know it, awesome. In any case, "make" is an example
of the declarative programming paradigm.
Consider this example makefile:
hello.jar: hello.class
jar cfe hello.jar hello hello.class
run: hello.jar
java -jar hello.jar
hello.class: hello.java
javac hello.java
What it defines are build rules for building a set of
files, and a dependency graph of files that combine
to form a whole program.
Concurrency
- Java features excellent concurrency support
- concurrency == the practice of doing two or more things at once.
- How much do you know about processes and threads so far?
- This subject is, in general, outside the scope of this course, but
you should see the basics of what Java provides.
- Basic issues you should look for in ANY concurrency facilities are
- how to get more than one computation to happen at once
- how to communicate/combine data between computations
- how to synchronize/coordinate computations
Threads
A thread is a computation, with a set of CPU registers and an execution
stack on which to evaluate expressions, call methods, etc.
In Java, threads can be created for any Runnable class, which
must implement a public void method named run().
public class HelloRunnable implements Runnable {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String args[]) throws InterruptedException {
Thread t;
HelloRunnable r = new HelloRunnable();
(t = new Thread(r)).start();
// can use r to "talk" to the child thread via class variables...
t.join();
}
}
Easy Synchronization
Synchronization means: forcing concurrent threads to take turns, and
wait for each other to finish. Imagine trying to talk at the same time
as someone you are with.
public synchronized void increment() {
c++;
}
Communication
Threads are in the same address space so they can can "talk" by just
storing values in variables that each other can see. Examples would
be static variables, and class fields in instances that both threads
know about (how would both threads know about an instance???).
The main kicker is to avoid race conditions, where two threads get
inconsistent information by writing to the same variable at the same
time. How to avoid that? Synchronization.
CLASSPATH
The -cp command line argument (to java) or
CLASSPATH environment variable specifies a list of directories and/or
.jar files in which to search for user class files. In large/complex Java
applications, it is often Very difficult to keep this straight.
Collections
Compared with more dynamic languages, Java has to spend a fair amount of
work to provide full compile-time type safety and reasonable polymorphism.
The organization of its "collections framework" reflects that challenge.
They use template classes a lot to allow types like "collection of X" but
are not great at handling "collection of mixed stuff" codes. You can
declare an ArrayList containing Object elements...
- Interfaces
- There is a whole hierarchy of collection interfaces algorithms code for.
- Implementations
- A set of reusable data structures
- Algorithms
- Searching, sorting, etc.
Per the Oracle docs:
Typical is to declare via:
abstracttype<elem> var = new concretetype<elem>(...);
The actual Collection base interface mainly defines size(), isEmpty(),
contains(o), iterator(), plus the ability to convert
to/from other collections and/or arrays. They usually also have
add(o) and remove() operation(s) of some kind.
Iterating
Iterable classes have an iterator() method that returns an object Iterator()
that sort of keeps track of where they are in the original object and let's
you walk through its elements. Mainly Iterators provide a next() method to
get the next element, and a hasNext() to say whether they are done or not.
I now have it on good authority that iterators can be used aggressively to
implement full Unicon-style generators and goal-directed evaluation; they
are just more long-winded and cumbersome to write.
Lists
Ordered collections know how to: sort, shuffle, reverse, rotate, swap,
replaceAll, fill, copy, binarySearch... kind of obviously related to
Lisp lists, but several implementations available with different performance
strengths and weaknesses.
Maps
Hash tables are one of the most important types in any "high level" language.
Notice that in order to initialize this "word frequency counter", you first
do a m.get(), and if it is null you start the count at 1.
Otherwise, you increment the count.
import java.util.*;
public class Freq {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<String, Integer>();
// Initialize frequency table from command line
for (String a : args) {
Integer freq = m.get(a);
m.put(a, (freq == null) ? 1 : freq + 1);
}
System.out.println(m.size() + " distinct words:");
System.out.println(m);
}
}
Introspection
"to look inside oneself" -- really in programming languages, it is the
ability of an object to describe itself at runtime. C++ has the concept
of "runtime type information" which is similar. In Java, any object
can be asked its getClass() method, which returns a Class object that
can cough up its fields, methods, etc. Consider the following example
from http://www.cs.grinnell.edu/~rebelsky/Courses/CS223/2004F/Handouts/introspection.html
public static void summarize(Object o) throws Exception
{
Class c = o.getClass();
System.out.println("Class: " + c.getName());
Method[] methods = c.getMethods();
System.out.println(" Methods: ");
for (int i = 0; i < methods.length; i++) {
System.out.print(" " + methods[i].toString());
if (methods[i].getDeclaringClass() != c)
System.out.println(" (inherited from " +
methods[i].getDeclaringClass().getName() + ")");
else
System.out.println();
}
} // summarize(String)
JavaBeans
Just so you all have heard a bit about them, JavaBeans are reusable software
components. They are just classes that follow a few conventions.
- They use
getters and setters to allow their states to be manipulated externally, e.g.
via GUI IDE.
- They must be either "Serializable" or "Externalizable": in order for the
bean to survive across multiple Java VM instances or program runs, it must
know how to write itself to disk in either a proprietary Java format or in
an XML format. Among other things, they must have a no-argument constructor.
Applets
An Applet is a Java program that will run in a web browser.
import javax.swing.JApplet;
import javax.swing.SwingUtilities;
import javax.swing.JLabel;
public class HelloWorld extends JApplet {
//Called when this applet is loaded into the browser.
public void init() {
//Execute a job on the event-dispatching thread; creating this applet's GUI.
try {
SwingUtilities.invokeAndWait(new Runnable() {
public void run() {
JLabel lbl = new JLabel("Hello World");
add(lbl);
}
});
} catch (Exception e) {
System.err.println("createGUI didn't complete successfully");
}
}
}
In addition to the init() method, many applets will have start() and stop()
methods to do any additional computation (such as launching/killing threads)
other than responding to GUI clicks.
To deply an applet, compile the code and package it as a JAR file. Then in
your web page you write
<applet code=AppletClassName.class
archive="JarFileName.jar"
width=width height=height>
</applet>
lecture 44
Final Exam Review
- Review language paradigms
- Know what imperative, functional, declarative, object-oriented, and
goal-directed languages are about.
- Flex
-
- What paradigm? How pure an example of that paradigm are Flex+Bison?
- Know regular expressions, including operators and precedence
- each symbol s is a regex that matches itself
- re1 re2 (concatenate) is regex
- re1 | re2 (alternate) is regex
- re1 * (Kleene star) is regex
- ( re1 ) is a regex
- . matches any one character except newline [^\n]
- What are Flex's rules for deciding which rule to use
when they overlap?
- What is Flex's general syntax?
- What is the public interface of Flex-generated lexical
analyzers to programs such as Bison parsers?
- Bison
-
- Know context free grammars, and common special cases.
- What are terminals and non-terminals? How can you tell whether a
symbol is terminal or non-terminal?
- production rules: NT -> ω where ω is 0 or more terminals and nonterminals
- What are Bison's rules for decide which rule to use
when they overlap?]
- what is more powerful about Bison than Flex?
- What are Bison conflicts and how does one solve them?
- What is Bison's public interface? How does a C/C++ program call
a Bison-generated parser?
- ML (1 2 3)
-
- What paradigm does ML represent?
- General syntax and program structure. What does a program look like?
- Know what are atoms
- basic ML: "scalar" or primitive values
- null, numbers, bool... Are strings scalar?
- Define tuples. How are they different from "arrays" in C/C++/Java?
- Give the mathematical definition of lists
- nil is a list of length 0
- if L is a list, anything :: L is a list
- Practice recursing on numbers, lists, ... anything else?
- What are the most common expressions in ML?
| Lists | Operators | Keywords | Control | Declaration
|
|---|
[] :: @
hd tl
| + - * /
div mod
~ ^
| andalso orelse
| if then else
case of ...
| fun vs. fn
let
val
|
- Patterns! this is a whole can of worms!
- patterns in parameter lists
- tuples, lists, and conses of patterns
- functions with multiple bodies that match different parameter patterns
- "Higher order functions" and Currying
- Unicon
-
- Java
-
- Know Java's general syntax. What does a program look like?
- What about Java is different from C++?
- Know Java's built-in types and rules for type checking.
- How do you write/create new types in Java?
- Know basics of I/O, like how to open a named file and read from it.
- Know the basics of arrays vs. Container classes
- For example, know ArrayList and HashMap