The questions we should ask, then, are: (a) should CS majors be required
to spend a lot of time becoming really good programmers? and (b) are we
providing students with the assistance and access to the tools and
information they need to accomplish their goals with the minimal doses
of inevitable pain that are required?
Note: although last year's CS 370 lecture notes are ALL available to you up
front, I generally revise each lecture's notes, making additions,
corrections and adaptations to this year's homeworks, the night before each
lecture. The best time to print hard copies of the lecture notes is one
day at a time, right before the lecture is given.
void * means "pointer that points at nothing", or "pointer that points
at anything". You need to cast it to what you are really pointing at,
as in:
union lexval *l = (union lexval *)malloc(sizeof(union lexval));
Note the stupid duplication of type information; no language is perfect!
Anyhow, always cast your mallocs. The program may work without the cast,
but you need to fix every warning, so you don't accidentally let a serious
one through.
Recursive Descent Parsing
Perhaps the simplest parsing method, for a large subset of context free
grammars, is called recursive descent. It is simple because the algorithm
closely follows the production rules of nonterminal symbols.
- Write 1 procedure per nonterminal rule
- Within each procedure, a) match terminals at appropriate positions,
and b) call procedures for non-terminals.
- Pitfalls:
- left recursion is FATAL
- must distinguish between several
production rules, or potentially, one has to
try all of them via backtracking.
Recursive Descent Parsing Example #1
Consider the grammar we gave above. There will be functions for
E, T, and F. The function for F() is the "easiest" in some sense: based
on a single token it can decide which production rule to use. The
parsing functions return 0 (failed to parse) if the nonterminal in
question cannot be derived from the tokens at the current point.
A nonzero return value of N would indicate success in parsing using
production rule #N.
int F()
{
int t = yylex();
if (t == IDENT) return 6;
else if (t == LP) {
if (E() && (yylex()==RP) return 5;
}
return 0;
}
Comment #1: if F() is in the middle of a larger parse of E() or T(), F()
may succeed, but the subsequent parsing may fail. The parse may have
to backtrack, which would mean we'd have to be able to put
tokens back for later parsing. Add a memory (say, a gigantic array or
link list for example) of already-parsed tokens
to the lexical analyzer, plus backtracking logic to E() or T() as needed.
The call to F() may get repeated following a different production rule
for a higher nonterminal.
Comment #2: in a real compiler we need more than "yes it parsed" or
"no it didn't": we need a parse tree if it succeeds, and we need a
useful error message if it didn't.
Question: for E() and T(), how do we know which production rule to try?
Option A: just blindly try each one in turn.
Option B: look at the first (current) token, only try those rules that
start with that token (1 character lookahead). If you are lucky, that
one character will uniquely select a production rule. If that is always
true through the whole grammar, no backtracking is needed.
Question: how do we know which rules start with whatever token we are
looking at? Can anyone suggest a solution, or are we stuck?
lecture #10 began here
Announcements
- Homework #3 minor extension
- Midterm exam: Thursday March 16
- The first midterm exam will cover lexical analysis and syntax analysis
Removing Left Recursion
E -> E + T | T
T -> T * F | F
F -> ( E ) | ident
We can remove the left recursion by introducing new nonterminals
and new production rules.
E -> T E'
E' -> + T E' | ε
T -> F T'
T' -> * F T' | ε
F -> ( E ) | ident
Getting rid of such immediate left recursion is not enough, one must
get rid of indirect left recursion, where two or more nonterminals are
mutually left-recursive.
One can rewrite any CFG to remove left recursion (Algorithm 4.1).
for i := 1 to n do
for j := 1 to i-1 do begin
replace each Ai -> Aj gamma with productions
Ai -> delta1gamma | delta2gamma
end
eliminate immediate left recursion
Removing Left Recursion, part 2
Left recursion can be broken into three cases
case 1: trivial
A : A α | β
The recursion must always terminate by A finally deriving β so you
can rewrite it to the equivalent
A : &beta A'
A' : &alpha A' | ε
Example:
E : E op T | T
can be rewritten
E : T E'
E' : op T E' | ε
case 2: non-trivial, but immediate
In the more general case, there may be multiple recursive productions
and/or multiple non-recursive productions.
A : A α1 | A α2 | ... | β1 | β2
As in the trivial case, you get rid of left-recursing A and introduce an A'
A : β1 A' | β2 A' | ...
A' : α1 A' | α2 A' | ... | ε
case 3: mutual recursion
- Order the nonterminals in some order 1 to N.
- Rewrite production rules to eliminate all
nonterminals in leftmost positions that refer to a "previous" nonterminal.
When finished, all productions' right hand symbols start with a terminal
or a nonterminal that is numbered equal or higher than the nonterminal
no the left hand side.
- Eliminate the direct left recusion as per cases 1-2.
Left Recursion Versus Right Recursion: When does it Matter?
A student came to me once with what they described as an operator precedence
problem where 5-4+3 was computing the wrong value (-2 instead of 4). What
it really was, was an associativity problem due to the grammar:
E : T + E | T - E | T
The problem here is that right recursion is forcing right associativity, but
normal arithmetic requires left associativity. Several solutions are:
(a) rewrite the grammar to be left recursive, or (b) rewrite the grammar
with more nonterminals to force the correct precedence/associativity,
or (c) if using YACC or Bison, there are "cheat codes" we will discuss later
to allow it to be majorly ambiguous and specify associativity separately
(look for %left and %right in YACC manuals).
Recursive Descent Parsing Example #2
The grammar
S -> A B C
A -> a A
A -> ε
B -> b
C -> c
maps to pseudocode like the following. (:= is an assignment operator)
procedure S()
if A() & B() & C() then succeed # matched S, we win
end
procedure A()
if yychar == a then { # use production 2
yychar := scan()
return A()
}
else
succeed # production rule 3, match ε
end
procedure B()
if yychar == b then {
yychar := scan()
succeed
}
else fail
end
procedure C()
if yychar == c then {
yychar := scan()
succeed
}
else fail
end
Backtracking?
Could your current token begin more than one of your possible production rules?
Try all of them, remember and reset state for each try.
S -> cAd
A -> ab
A -> a
Left factoring can often solve such problems:
S -> cAd
A -> a A'
A'-> b
A'-> (ε)
One can also perform left factoring to reduce or
eliminate the lookahead or backtracking needed to tell which production rule
to use. If the end result has no lookahead or backtracking needed, the
resulting CFG can be solved by a "predictive parser" and coded easily in a
conventional language. If backtracking is needed, a recursive descent
parser takes more work to implement, but is still feasible.
As a more concrete example:
S -> if E then S
S -> if E then S1 else S2
can be factored to:
S -> if E then S S'
S'-> else S2 | ε
Some More Parsing Theory
Automatic techniques for constructing parsers start with computing some
basic functions for symbols in the grammar. These functions are useful
in understanding both recursive descent and bottom-up LR parsers.
First(a)
First(a) is the set of terminals that begin strings derived from a,
which can include ε.
- First(X) starts with the empty set.
- if X is a terminal, First(X) is {X}.
- if X -> ε is a production, add ε to First(X).
- if X is a non-terminal and X -> Y1 Y2 ... Yk is a production,
add First(Y1) to First(X).
for (i = 1; if Yi can derive ε; i++)
add First(Yi+1) to First(X)
First(a) examples
by the way, this stuff is all in section 4.3 in your text.
Last time we looked at an example with E, T, and F, and + and *.
The first-set computation was not too exciting and we need more
examples.
stmt : if-stmt | OTHER
if-stmt: IF LP expr RP stmt else-part
else-part: ELSE stmt | ε
expr: IDENT | INTLIT
What are the First() sets of each nonterminal?
Follow(A)
Follow(A) for nonterminal A is the set of terminals that can appear
immediately to the right of A in some sentential form S -> aAxB...
To compute Follow, apply these rules to all nonterminals in the grammar:
- Add $ to Follow(S)
- if A -> aBb then add First(b) - ε to Follow(B)
- if A -> aB or A -> aBb where ε is in First(b), then add
Follow(A) to Follow(B).
On resizing arrays in C
The sval attribute in homework #2 is a perfect example of a problem which a
BCS major might not be expected to manage, but a CS major should be able to
do by the time they graduate. This is not to encourage any of you to consider
BCS, but rather, to encourage you to learn how to solve problems like these.
The problem can be summarized as: step through yytext, copying each piece
out to sval, removing doublequotes and plusses between the pieces, and
evaluating CHR$() constants.
Space allocated with malloc() can be increased in size by realloc().
realloc() is awesome. But, it COPIES and MOVES the old chunk of
space you had to the new, resized chunk of space, and frees the old
space, so you had better not have any other pointers pointing at
that space if you realloc(), and you have to update your pointer to
point at the new location realloc() returns.
i = 0; j = 0;
while (yytext[i] != '\0') {
if (yytext[i] == '\"') {
/* copy string into sval */
i++;
while (yytext[i] != '\"') {
sval[j++] = yytext[i++];
}
}
else if ((yytext[i] == 'C') || (yytext[i] == 'c')) {
/* handle CHR$(...) */
i += 5;
k = atoi(yytext + i);
sval[j++] = k; /* might check for 0-255 */
while (yytext[i] != ')') i++;
}
/* else we can just skip it */
i++;
}
sval[j] = '\0'; /* NUL-terminate our string */
There is one more problem: how do we allocate memory for sval, and how big
should it be?
- Solution #1: sval = malloc(strlen(yytext)+1) is very safe, but wastes
space.
- Solution #2: you could malloc a small amount and grow the array as
needed.
sval = strdup("");
...
sval = appendstring(sval, yytext[i]); /* instead of sval[j++] = yytext[i] */
where the function appendstring could be:
char *appendstring(char *s, char c)
{
i = strlen(s);
s = realloc(s, i+2);
s[i] = c;
s[i+1] = '\0';
return s;
}
Note: it is very inefficient to grow your array one character at
a time; in real life people grow arrays in large chunks at a time.
- Solution #3: use solution one and then shrink your array when you
find out how big it actually needs to be.
sval = malloc(strlen(yytext)+1);
/* ... do the code copying into sval; be sure to NUL-terminate */
sval = realloc(sval, strlen(sval)+1);
lecture #11 began here
YACC
YACC ("yet another compiler compiler") is a popular tool which originated at
AT&T Bell Labs. YACC takes a context free grammar as input, and generates a
parser as output. Several independent, compatible implementations (AT&T
yacc, Berkeley yacc, GNU Bison) for C exist, as well as many implementations
for other popular languages.
YACC files end in .y and take the form
declarations
%%
grammar
%%
subroutines
The declarations section defines the terminal symbols (tokens) and
nonterminal symbols. The most useful declarations are:
- %token a
- declares terminal symbol a; YACC can generate a set of #define's
that map these symbols onto integers, in a y.tab.h file. Note: don't
#include your y.tab.h file from your grammar .y file, YACC generates the
same definitions and declarations directly in the .c file, and including
the .tab.h file will cause duplication errors.
- %start A
- specifies the start symbol for the grammar (defaults to nonterminal
on left side of the first production rule).
The grammar gives the production rules, interspersed with program code
fragments called semantic actions that let the programmer do what's
desired when the grammar productions are reduced. They follow the
syntax
A : body ;
Where body is a sequence of 0 or more terminals, nonterminals, or semantic
actions (code, in curly braces) separated by spaces. As a notational
convenience, multiple production rules may be grouped together using the
vertical bar (|).
Bottom Up Parsing
Bottom up parsers start from the sequence of terminal symbols and work
their way back up to the start symbol by repeatedly replacing grammar
rules' right hand sides by the corresponding non-terminal. This is
the reverse of the derivation process, and is called "reduction".
Example. For the grammar
(1) S->aABe
(2) A->Abc
(3) A->b
(4) B->d
the string "abbcde" can be parsed bottom-up by the following reduction
steps:
abbcde
aAbcde
aAde
aABe
S
Handles
Definition: a handle is a substring that
- matches a right hand side of a production rule in the grammar and
- whose reduction to the nonterminal on the left hand side of that
grammar rule is a step along the reverse of a rightmost derivation.
Shift Reduce Parsing
A shift-reduce parser performs its parsing using the following structure
Stack Input
$ w$
At each step, the parser performs one of the following actions.
- Shift one symbol from the input onto the parse stack
- Reduce one handle on the top of the parse stack. The symbols
from the right hand side of a grammar rule are popped of the
stack, and the nonterminal symbol is pushed on the stack in their place.
- Accept is the operation performed when the start symbol is alone
on the parse stack and the input is empty.
- Error actions occur when no successful parse is possible.
The YACC Value Stack
- YACC's parse stack contains only "states"
- YACC maintains a parallel set of values
- $ is used in semantic actions to name elements on the value stack
- $$ denotes the value associated with the LHS (nonterminal) symbol
- $n denotes the value associated with RHS symbol at position n.
- Value stack typically used to construct the parse tree
- Typical rule with semantic action: A : b C d { $$ = tree(R,3,$1,$2,$3); }
- The default value stack is an array of integers
- The value stack can hold arbitrary values in an array of unions
- The union type is declared with %union and is named YYSTYPE
Getting Lex and Yacc to talk
YACC uses a global variable named yylval, of type YYSTYPE, to receive
lexical information from the scanner. Whatever is in this variable
each time yylex() returns to the parser will get copied over to the
top of the value stack when the token is shifted onto the parse stack.
You can either declare that struct token may appear in the %union,
and put a mixture of struct node and struct token on the value stack,
or you can allocate a "leaf" tree node, and point it at your struct
token. Or you can use a tree type that allows tokens to include
their lexical information directly in the tree nodes. If you have
more than one %union type possible, be prepared to see type conflicts
and to declare the types of all your nonterminals.
Getting all this straight takes some time; you can plan on it. Your best
bet is to draw pictures of how you want the trees to look, and then make the
code match the pictures. No pictures == "Dr. J will ask to see your
pictures and not be able to help if you can't describe your trees."
Declaring value stack types for terminal and nonterminal symbols
Unless you are going to use the default (integer) value stack, you will
have to declare the types of the elements on the value stack. Actually,
you do this by declaring which
union member is to be used for each terminal and nonterminal in the
grammar.
Example: in the cocogram.y that I gave you we could add a %union declaration
with a union member named treenode:
%union {
nodeptr treenode;
}
This will produce a compile error if you haven't declared a nodeptr type
using a typedef, but that is another story. To declare that a nonterminal
uses this union member, write something like:
%type < treenode > function_definition
Terminal symbols use %token to perform the corresponding declaration.
If you had a second %union member (say struct token *tokenptr) you
might write:
%token < tokenptr > SEMICOL
Announcements
Midterm Exam is coming up, March 16. Midterm review March 14.
Three more lectures before that.
LR vs. LL vs. LR(0) vs. LR(1) vs. LALR(1)
The first char ("L") means input tokens are read from the left
(left to right). The second char ("R" or "L") means parsing
finds the rightmost, or leftmost, derivation. Relevant
if there is ambiguity in the grammar. (0) or (1) or (k) after
the main lettering indicates how many lookahead characters are
used. (0) means you only look at the parse stack, (1) means you
use the current token in deciding what to do, shift or reduce.
(k) means you look at the next k tokens before deciding what
to do at the current position.
LR Parsers
LR denotes a class of bottom up parsers that is capable of handling virtually
all programming language constructs. LR is efficient; it runs in linear time
with no backtracking needed. The class of languages handled by LR is a proper
superset of the class of languages handled by top down "predictive parsers".
LR parsing detects an error as soon as it is possible to do so. Generally
building an LR parser is too big and complicated a job to do by hand, we use
tools to generate LR parsers.
The LR parsing algorithm is given below.
ip = first symbol of input
repeat {
s = state on top of parse stack
a = *ip
case action[s,a] of {
SHIFT s': { push(a); push(s') }
REDUCE A->beta: {
pop 2*|beta| symbols; s' = new state on top
push A
push goto(s', A)
}
ACCEPT: return 0 /* success */
ERROR: { error("syntax error", s, a); halt }
}
}
Constructing SLR Parsing Tables:
Note: in Spring 2006 this material is FYI but you will not be
examined on it.
Definition: An LR(0) item of a grammar G is a production
of G with a dot at some position of the RHS.
Example: The production A->aAb gives the items:
A -> . a A b
A -> a . A b
A -> a A . b
A -> a A b .
Note: A production A-> ε generates
only one item:
A -> .
Intuition: an item A-> α . β denotes:
- α - we have already seen a string
derivable from α
- β - we hope to see a string derivable
from β
Functions on Sets of Items
Closure: if I is a set of items for a grammar G, then closure(I)
is the set of items constructed as follows:
- Every item in I is in closure(I).
- If A->α . Bβ
is in closure(I) and B->γ
is a production, then add B-> .γ
to closure(I).
These two rules are applied repeatedly until no new items can
be added.
Intuition: If A -> α . B β is in
closure(I) then we hope to see a string derivable from B in the
input. So if B-> γ is a production,
we should hope to see a string derivable from γ.
Hence, B->.γ is in closure(I).
Goto: if I is a set of items and X is a grammar symbol, then goto(I,X)
is defined to be:
goto(I,X) = closure({[A->αX.β] | [A->α.Xβ]
is in I})
Intuition:
- [A->α.Xβ]
is in I => we've seen a string derivable
from α; we hope to see a string derivable
from Xβ.
- Now suppose we see a string derivable from X
- Then, we should "goto" a state where we've seen
a string derivable from αX, and where
we hope to see a string derivable from β.
The item corresponding to this is [A->αX.β]
- Example: Consider the grammar
E -> E+T | T
T -> T*F | F
F -> (E) | id
Let I = {[E -> E . + T]} then:
goto(I,+) = closure({[E -> E+.T]})
= closure({[E -> E+.T], [E -> .T*F], [T -> .F]})
= closure({[E -> E+.T], [E -> .T*F], [T -> .F], [F-> .(E)], [F -> .id]})
= { [E -> E + .T],[T -> .T * F],[T -> .F],[F -> .(E)],[F -> .id]}
The Sets of Items Construction
- Given a grammar G with start symbol S, construct the augmented
grammar by adding a special production S'->S where S' does
not appear in G.
- Algorithm for constructing the canonical collection of LR(0)
items for an augmented grammar G':
begin
C := { closure({[S' -> .S]}) };
repeat
for each set of items I in C:
for each grammar symbol X:
if goto(I,X) != 0 and goto(I,X) is not in C then
add goto(I,X) to C;
until no new sets of items can be added to C;
return C;
end
Valid Items: an item A -> β
1. β 2
is valid for a viable prefix α
β 1 if
there is a derivation:
S' =>*rm αAω =>*rmα β1β 2ω
Suppose A -> β1.β 2 is valid for αβ1,
and αB1 is on the parsing
stack
- if β2 != ε,
we should shift
- if β2 = ε,
A -> β1 is the handle,
and we should reduce by this production
Note: two valid items may tell us to do different things for the
same viable prefix. Some of these conflicts can be resolved using
lookahead on the input string.
Constructing an SLR Parsing Table
- Given a grammar G, construct the augmented grammar by adding
the production S' -> S.
- Construct C = {I0, I1, … In},
the set of sets of LR(0) items for G'.
- State I is constructed from Ii, with parsing action
determined as follows:
- [A -> α.aB] is in
Ii, where a is a terminal; goto(Ii,a) = Ij
: set action[i,a] = "shift j"
- [A -> α.] is in
Ii : set action[i,a] to "reduce A -> x"
for all a e FOLLOW(A), where A != S'
- [S' -> S] is in Ii :
set action[i,$] to "accept"
- goto transitions constructed as follows: for all non-terminals:
if goto(Ii, A) = Ij, then goto[i,A] = j
- All entries not defined by (3) & (4) are made "error".
If there are any multiply defined entries, grammar is not SLR.
- Initial state S0 of parser: that constructed from
I0 or [S' -> S]
Example:
S -> aABe FIRST(S) = {a} FOLLOW(S) = {$}
A -> Abc FIRST{A} = {b} FOLLOW(A) = {b,d}
A -> b FIRST{B} = {d} FOLLOW{B} = {e}
B -> d FIRST{S'}= {a} FOLLOW{S'}= {$}
I0 = closure([S'->.S]
= closure([S'->.S],[S->.aABe])
goto(I0,S) = closure([S'->S.]) = I1
goto(I0,a) = closure([S->a.Abe])
= closure([S->a.Abe],[A->.Abc],[A->.b]) = I2
goto(I2,A) = closure([S->aA.Be],[A->A.bc])
= closure([S->aA.Be],[A->A.bc],[B->.d]) = I3
goto(I2,B) = closure([A->b.]) = I4
goto(I3,B) = closure([S->aAB.e]) = I5
goto(I3,b) = closure([A->Ab.c]) = I6
goto(I3,d) = closure([B->d.]) = I7
goto(I5,e) = closure([S->aABe.]) = I8
goto(I6,c) = closure([A->Abc.]) = I9
lecture #14 began here
On Tree Traversals
Trees are classic data structures. Trees have nodes and edges, so they are
a special case of graphs. Tree edges are directional, with roles "parent"
and "child" attributed to the source and destination of the edge.
A tree has the property that every node has zero or one parent. A node
with no parents is called a root. A node with no children is called a leaf.
A node that is neither a root nor a leaf is an "internal node". Trees have
a size (total # of nodes), a height (maximum count of nodes from root to a leaf),
and an "arity" (maximum number of children in any one node).
Parse trees are k-ary, where there is a
variable number of children bounded by a value k determined by the grammar.
You may wish to consult your old data structures book, or look at some books
from the library, to learn more about trees if you are not totally
comfortable with them.
#include <stdarg.h>
struct tree {
short label; /* what production rule this came from */
short nkids; /* how many children it really has */
struct tree *child[1]; /* array of children, size varies 0..k */
};
struct tree *alctree(int label, int nkids, ...)
{
int i;
va_list ap;
struct tree *ptr = malloc(sizeof(struct tree) +
(nkids-1)*sizeof(struct tree *));
if (ptr == NULL) {fprintf(stderr, "alctree out of memory\n"); exit(1); }
ptr->label = label;
ptr->nkids = nkids;
va_start(ap, nkids);
for(i=0; i < nkids; i++)
ptr->child[i] = va_arg(ap, struct tree *);
va_end(ap);
return ptr;
}
Besides a function to allocate trees, you need to write one or more recursive
functions to visit each node in the tree, either top to bottom (preorder),
or bottom to top (postorder). You might do many different traversals on the
tree in order to write a whole compiler: check types, generate machine-
independent intermediate code, analyze the code to make it shorter, etc.
You can write 4 or more different traversal functions, or you can write
1 traversal function that does different work at each node, determined by
passing in a function pointer, to be called for each node.
void postorder(struct tree *t, void (*f)(struct tree *))
{
/* postorder means visit each child, then do work at the parent */
int i;
if (t == NULL) return;
/* visit each child */
for (i=0; i < t-> nkids; i++)
postorder(t->child[i], f);
/* do work at parent */
f(t);
}
You would then be free to write as many little helper functions as you
want, for different tree traversals, for example:
void printer(struct tree *t)
{
if (t == NULL) return;
printf("%p: %d, %d children\n", t, t->label, t->nkids);
}
Semantic Analysis
Semantic ("meaning") analysis refers to a phase of compilation in which the
input program is studied in order to determine what operations are to be
carried out. The two primary components of a classic semantic analysis
phase are variable reference analysis and type checking. These components
both rely on an underlying symbol table.
What we have at the start of semantic analysis is a syntax tree that
corresponds to the source program as parsed using the context free grammar.
Semantic information is added by annotating grammar symbols with
semantic attributes, which are defined by semantic rules.
A semantic rule is a specification of how to calculate a semantic attribute
that is to be added to the parse tree.
So the input is a syntax tree...and the output is the same tree, only
"fatter" in the sense that nodes carry more information.
Another output of semantic analysis are error messages detecting many
types of semantic errors.
Two typical examples of semantic analysis include:
- variable reference analysis
- the compiler must determine, for each use of a variable, which
variable declaration corresponds to that use. This depends on
the semantics of the source language being translated.
- type checking
- the compiler must determine, for each operation in the source code,
the types of the operands and resulting value, if any.
Notations used in semantic analysis:
- syntax-directed definitions
- high-level (declarative) specifications of semantic rules
- translation schemes
- semantic rules and the order in which they get evaluated
In practice, attributes get stored in parse tree nodes, and the
semantic rules are evaluated either (a) during parsing (for easy rules) or
(b) during one or more (sub)tree traversals.
Two Types of Attributes:
- synthesized
- attributes computed from information contained within one's children.
These are generally easy to compute, even on-the-fly during parsing.
- inherited
- attributes computed from information obtained from one's parent or siblings
These are generally harder to compute. Compilers may be able to jump
through hoops to compute some inherited attributes during parsing,
but depending on the semantic rules this may not be possible in general.
Compilers resort to tree traversals to move semantic information around
the tree to where it will be used.
Attribute Examples
Isconst and Value
Not all expressions have constant values; the ones that do may allow
various optimizations.
| CFG | Semantic Rule
|
|
E1 : E2 + T
|
E1.isconst = E2.isconst && T.isconst
if (E1.isconst)
E1.value = E2.value + T.value
|
|
E : T
|
E.isconst = T.isconst
if (E.isconst)
E.value = T.value
|
|
T : T * F
|
T1.isconst = T2.isconst && F.isconst
if (T1.isconst)
T1.value = T2.value * F.value
|
|
T : F
|
T.isconst = F.isconst
if (T.isconst)
T.value = F.value
|
|
F : ( E )
|
F.isconst = E.isconst
if (F.isconst)
F.value = E.value
|
|
F : ident
|
F.isconst = FALSE
|
|
F : intlit
|
F.isconst = TRUE
F.value = intlit.ival
|
|
lecture #15 began here
Questions from the board and from the floor
Symbol Table Module
Symbol tables are used to resolve names within name spaces. Symbol
tables are generally organized hierarchically according to the
scope rules of the language. Although initially concerned with simply
storing the names of various that are visible in each scope, symbol
tables take on additional roles in the remaining phases of the compiler.
In semantic analysis, they store type information. And for code generation,
they store memory addresses and sizes of variables.
- mktable(parent)
- creates a new symbol table, whose scope is local to (or inside) parent
- enter(table, symbolname, type, offset)
- insert a symbol into a table
- lookup(table, symbolname)
- lookup a symbol in a table; returns structure pointer including type and offset. lookup operations are often chained together progressively from most local scope on out to global scope.
- addwidth(table)
- sums the widths of all entries in the table. ("widths" = #bytes, sum of
widths = #bytes needed for an "activation record" or "global data section").
Worry not about this method until code generation you wish to implement.
- enterproc(table, name, newtable)
- enters the local scope of the named procedure
Variable Reference Analysis
The simplest use of a symbol table would check:
- for each variable, has it been declared? (undeclared error)
- for each declaration, is it already declared? (redeclared error)
Reading Tree Leaves
In order to work with your tree, you must be able to tell, preferably
trivially easily, which nodes are tree leaves and which are internal nodes,
and for the leaves, how to access the lexical attributes.
Options:
- encode in the parent what the types of children are
- encode in each child what its own type is (better)
How do you do option #2 here?
Perhaps the best approach to all this is to unify the tokens and parse tree
nodes with something like the following, where perhaps an nkids value of -1
is treated as a flag that tells the reader to use
lexical information instead of pointers to children:
struct node {
int code; /* terminal or nonterminal symbol */
int nkids;
union {
struct token { ... } leaf;
struct node *kids[9];
}u;
} ;
There are actually nonterminal symbols with 0 children (nonterminal with
a righthand side with 0 symbols) so you don't necessarily want to use
an nkids of 0 is your flag to say that you are a leaf.
Type Checking
Perhaps the primary component of semantic analysis in many traditional
compilers consists of the type checker. In order to check types, one first
must have a representation of those types (a type system) and then one must
implement comparison and composition operators on those types using the
semantic rules of the source language being compiled. Lastly, type checking
will involve adding (mostly-) synthesized attributes through those parts of
the language grammar that involve expressions and values.
Type Systems
Types are defined recursively according to rules defined by the source
language being compiled. A type system might start with rules like:
- Base types (int, char, etc.) are types
- Named types (via typedef, etc.) are types
- Types composed using other types are types, for example:
- array(T, indices) is a type. In some
languages indices always start with 0, so array(T, size) works.
- T1 x T2 is a type (specifying, more or
less, the tuple or sequence T1 followed by T2;
x is a so-called cross-product operator).
- record((f1 x T1) x (f2 x T2) x ... x (fn x Tn)) is a type
- in languages with pointers, pointer(T) is a type
- (T1 x ... Tn) -> Tn+1 is a
type denoting a function mapping parameter types to a return type
- In some language type expressions may contain variables whose values
are types.
In addition, a type system includes rules for assigning these types
to the various parts of the program; usually this will be performed
using attributes assigned to grammar symbols.
lecture #16 began here
Midterm Exam Review
The Midterm will cover lexical analysis, finite automatas, context free
grammars, syntax analysis, and parsing. Sample problems:
- Write a regular expression for numeric quantities of U.S. money
that start with a dollar sign, followed by one or more digits.
Require a comma between every three digits, as in $7,321,212.
Also, allow but do not require a decimal point followed by two
digits at the end, as in $5.99
- Use Thompson's construction to write a non-deterministic finite
automaton for the following regular expression, an abstraction
of the expression used for real number literal values in C.
(d+pd*|d*pd+)(ed+)?
- Write a regular expression, or explain why you can't write a
regular expression, for Modula-2 comments which use (* *) as
their boundaries. Unlike C, Modula-2 comments may be nested,
as in (* this is a (* nested *) comment *)
- Write a context free grammar for the subset of C expressions
that include identifiers and function calls with parameters.
Parameters may themselves be function calls, as in f(g(x)),
or h(a,b,i(j(k,l)))
- What are the FIRST(E) and FOLLOW(T) in the grammar:
E : E + T | T
T : T * F | F
F : ( E ) | ident
- What is the ε-closure(move({2,4},b)) in the following NFA?
That is, suppose you might be in either state 2 or 4 at the time
you see a symbol b: what NFA states might you find yourself in
after consuming b?
(automata to be written on the board)
Q: What else is likely to appear on the midterm?
A: questions that allow you to demonstrate that you know the difference
between an DFA and an NFA, questions about lex and flex and tokens
and lexical attributes, questions about context free grammars:
ambiguity, factoring, removing left recursion, etc.
On the mysterious TYPE_NAME
The C language typedef construct is an example where all the beautiful
theory we've used up to this point breaks down. Once a typedef is
introduced (which can first be recognized at the syntax level), certain
identifiers should be legal type names instead of identifiers. To make
things worse, they are still legal variable names: the lexical analyzer
has to know whether the syntactic context needs a type name or an
identifier at each point in which it runs into one of these names. This
sort of feedback from syntax or semantic analysis back into lexical
analysis is not un-doable but it requires extensions added by hand to
the machine generated lexical and syntax analyzer code.
typedef int foo;
foo x; /* a normal use of typedef... */
foo foo; /* try this on gcc! is it a legal global? */
void main() { foo foo; } /* what about this ? */
370-C does not support typedef's and without working typedef's the
TYPE_NAME token simply will never occur. Typedef's are fair game for
extra credit points.
Representing C (C++, Java, etc.) Types
The type system is represented using data structures in the compiler's
implementation language.
In the symbol table and in the parse tree attributes used in type checking,
there is a need to represent and compare source language types. You might
start by trying to assign a numeric code to each type, kind of like the
integers used to denote each terminal symbol and each production rule of the
grammar. But what about arrays? What about structs? There are an infinite
number of types; any attempt to enumerate them will fail. Instead, you
should create a new data type to explicitly represent type information.
This might look something like the following:
struct c_type {
int base_type; /* 1 = int, 2=float, ... */
union {
struct array {
int size;
struct c_type *elemtype;
} a;
struct ctype *p;
struct struc {
char *label;
struct field **f;
} s;
} u;
}
struct field {
char *name;
struct ctype *elemtype;
}
Given this representation, how would you initialize a variable to
represent each of the following types:
int [10][20]
struct foo { int x; char *s; }
Example Semantic Rules for Type Checking
| grammar rule | semantic rule
|
| E1 : E2 PLUS E3
| E1.type = check_types(PLUS, E2.type, E3.type)
|
Where check_types() returns a (struct c_type *) value. One of the values
it should be able to return is Error. The operator (PLUS) is included in
the check types function because behavior may depend on the operator --
the result type for array subscripting works different than the result
type for the arithmetic operators, which may work different (in some
languages) than the result type for logical operators that return booleans.
Type Promotion and Type Equivalence
When is it legal to perform an assignment x = y? When x and y are
identical types, sure. Many languages such as C have automatic
promotion rules for scalar types such as shorts and longs.
The results of type checking may include not just a type attribute,
they may include a type conversion, which is best represented by
inserting a new node in the tree to denote the promoted value.
Example:
int x;
long y;
y = y + x;
For records/structures, some languages use name equivalence, while
others use structure equivalence. Features like typedef complicate
matters. If you have a new type name MY_INT that is defined to be
an int, is it compatible to pass as a parameter to a function that
expects regular int's? Object-oriented languages also get interesting
during type checking, since subclasses usually are allowed anyplace
their superclass would be allowed.
Implementing Structs
- storing and retrieving structs by their label -- the struct label is
how structs are identified. You do not have to do typedefs and such.
The labels can be keys in a separate hash table, similar to the global
symbol table. You can put them in the global symbol table so long as
you can tell the difference between them and variable names.
- You have to store fieldnames and their types, from where the struct is
declared. You could use a hash table for each struct, but a link list
is OK as an alternative.
- You have to use the struct information to check the validity of each
dot operator like in rec.foo. To do this you'll have to lookup rec
in the symbol table, where you store rec's type. rec's type must be
a struct type for the dot to be legal, and that struct type should
include a hash table or link list that gives the names and types of
the fields -- where you can lookup the name foo to find its type.
lecture #17 began here
Run-time Environments
How does a compiler (or a linker) compute the addresses for the various
instructions and references to data that appear in the program source code?
To generate code for it, the compiler has to "lay out" the data as it will
be used at runtime, deciding how big things are, and where they will go.
- Relationship between source code names and data objects during execution
- Procedure activations
- Memory management and layout
- Library functions
lecture #18 began here
Announcements
-
Affinity Research Group Workshop this Saturday, 9-3 in SH 124.
Extra credit: 20 points will be added to your midterm exam grade
for attending and providing sincere attention at this workshop.
Lunch is also provided.
- HW#5 is available
Scopes and Bindings
Variables may be declared explicitly or implicitly in some languages
Scope rules for each language determine how to go from names to declarations.
Each use of a variable name must be associated with a declaration.
This is generally done via a symbol table. In most compiled languages
it happens at compile time (in contrast, for example ,with LISP).
Environment and State
Environment maps source code names onto storage addresses (at compile time),
while state maps storage addresses into values (at runtime). Environment
relies on binding rules and is used in code generation; state operations
are loads/stores into memory, as well as allocations and deallocations.
Environment is concerned with scope rules, state is concerned with things
like the lifetimes of variables.
Runtime Memory Regions
Operating systems vary in terms of how the organize program memory
for runtime execution, but a typical scheme looks like this:
| code
|
|---|
| static data
|
|---|
| stack (grows down)
|
|---|
| heap (may grow up, from bottom of address space)
|
The code section may be read-only, and shared among multiple instances
of a program. Dynamic loading may introduce multiple code regions, which
may not be contiguous, and some of them may be shared by different programs.
The static data area may consist of two sections, one for "initialized data",
and one section for uninitialized (i.e. all zero's at the beginning).
Some OS'es place the heap at the very end of the address space, with a big
hole so either the stack or the heap may grow arbitrarily large. Other OS'es
fix the stack size and place the heap above the stack and grow it down.
Questions to ask about a language, before writing its code generator
- May procedures be recursive? (Duh, all modern languages...)
- What happens to locals when a procedure returns? (Lazy deallocation rare)
- May a procedure refer to non-local, non-global names?
(Pascal-style nested procedures, and object field names)
- How are parameters passed? (Many styles possible, different
declarations for each (Pascal), rules hardwired by type (C)?)
- May procedures be passed as parameters? (Not too awful)
- May procedures be return values? (Adds complexity for non-local names)
- May storage be allocated dynamically (Duh, all modern languages...
but some languages do it with syntax (new) others with library (malloc))
- Must storage by deallocated explicitly (garbage collector?)
Activation Records
Activation records organize the stack, one record per method/function call.
| return value
|
| parameter
|
| ...
|
| parameter
|
| previous frame pointer (FP)
|
| saved registers
|
| ...
|
| FP--> | saved PC
|
| local
|
| ...
|
| local
|
| temporaries
|
| SP--> | ...
|
At any given instant, the live activation records form a chain and
follow a stack discipline. Over the lifetime of the program, this
information (if saved) would form a gigantic tree. If you remember
prior execution up to a current point, you have a big tree in which
its rightmost edge are live activation records, and the non-rightmost
tree nodes are an execution history of prior calls.
"Modern" Runtime Systems
The preceding discussion has been mainly about traditional languages such as
C. Object-oriented programs might be much the same, only every activation
record has an associated object instance; they need one extra "register" in
the activation record. In practice, modern OO runtime systems have many
more differences than this, and other more exotic language features imply
substantial differences in runtime systems. Here are a few examples of
features found in runtimes such as the Java Virtual Machine and .Net CLR.
Goal-directed programs have an activation tree each instant, due to
suspended activations that may be resumed for additional results. The
lifetime view is a sort of multidimensional tree, with three types of nodes.
Having Trouble Debugging?
To save yourself on the semester project in this class, you really do have
to learn gdb and/or ddd as well as you can. Sometimes it can help you
find your bug in seconds where you would have spent hours without it. But
only if you take the time to read the manual and learn the debugger.
To work on segmentation faults: recompile all .c files with -g and run your
program inside gdb to the point of the segmentation fault. Type the gdb
"where" command. Print the values of variables on the line mentioned in the
debugger as the point of failure. If it is inside a C library function, use
the "up" command until you are back in your own code, and then print the
values of all variables mentioned on that line.
There is one more tool you should know about, which is useful for certain
kinds of bugs, primarily subtle memory violations. It is called electric
fence. To use electric fence you add
/home/uni1/jeffery/ef/ElectricFence-2.1/libefence.a
to the line in your makefile that links your object files together to
form an executable.
lecture #19 began here
Need Help with Type Checking?
- Implement the C Type Representation given in lecture #16.
- Read the Book
- What OPERATIONS (functions) do you need, in order to check
whether types are correct? What parameters will they take?
Intermediate Code Generation
Goal: list of machine-independent instructions for each procedure/method
in the program. Basic data layout of all variables.
Can be formulated as syntax-directed translation
- add new attributes where necessary, e.g. for expression E we might have
- E.place
- the name that holds the value of E
- E.code
- the sequence of intermediate code statements evaluating E.
- new helper functions, e.g.
newtemp()
- returns a new temporary variable each time it is called
newlabel()
- returns a new label each time it is called
- actions that generate intermediate code formulated as semantic rules
| Production | Semantic Rules |
|---|
| S -> id ASN E | S.code = E.code || gen(ASN, id.place, E.place)
|
| E -> E1 PLUS E2 | E.place = newtemp();
E.code = E1.code || E2.code || gen(PLUS,E.place,E1.place,E2.place);
|
| E -> E1 MUL E2 | E.place = newtemp();
E.code = E1.code || E2.code || gen(MUL,E.place,E1.place,E2.place);
|
| E -> MINUS E1 | E.place = newtemp();
E.code = E1.code || gen(NEG,E.place,E1.place);
|
| E -> LP E1 RP | E.place = E1.place;
E.code = E1.code;
|
| E -> IDENT | E.place = id.place;
E.code = emptylist();
|
Three-Address Code
Basic idea: break down source language expressions into simple pieces that:
- translate easily into real machine code
- form a linearized representation of a syntax tree
- allow us to check our own work to this point
- allow machine independent code optimizations to be performed
- increase the portability of the compiler
Instruction set:
| mnemonic | C equivalent | description
|
|---|
| ADD, SUB,MUL,DIV | x := y op z | store result of binary operation on y and z to x
|
|---|
| NEG | x := op y | store result of unary operation on y to x
|
|---|
| ASN | x := y | store y to x
|
|---|
| ADDR | x := &y | store address of y to x
|
|---|
| LCONT | x := *y | store contents pointed to by y to x
|
|---|
| SCONT | *x := y | store y to location pointed to by x
|
|---|
| GOTO | goto L | unconditional jump to L
|
|---|
| BLESS,... | if x rop y then goto L | binary conditional jump to L
|
|---|
| BIF | if x then goto L | unary conditional jump to L
|
|---|
| BNIF | if !x then goto L | unary negative conditional jump to L
|
|---|
| PARM | param x | store x as a parameter
|
|---|
| CALL | call p,n,x | call procedure p with n parameters, store result in x
|
|---|
| RET | return x | return from procedure, use x as the result
|
|---|
Declarations (Pseudo instructions):
These declarations list size units as "bytes"; in a uniform-size environment
offsets and counts could be given in units of "slots", where a slot (4 bytes
on 32-bit machines) holds anything.
| global x,n1,n2 | declare a global named x at offset n1 having n2 bytes of space
|
|---|
| proc x,n1,n2 | declare a procedure named x with n1 bytes of parameter space and n2 bytes of local variable space
|
|---|
| local x,n | declare a local named x at offset n from the procedure frame
|
|---|
| label Ln | designate that label Ln refers to the next instruction
|
|---|
| end | declare the end of the current procedure
|
|---|
TAC Adaptations for Object Oriented Code
| x := y field z | lookup field named z within y, store address to x
|
|---|
| class x,n1,n2 | declare a class named x with n1 bytes of class variables and n2 bytes of class method pointers
|
|---|
| field x,n | declare a field named x at offset n in the class frame
|
|---|
| new x | create a new instance of class name x
|
|---|
Variable Allocation and Access Issues
Given a variable name, how do we compute its address?
- globals
- easy, symbol table lookup
- locals
- easy, symbol table gives offset in (current) activation record
- objects
- easy, symbol table gives offset in object, activation record has
pointer to object in a standard location
- locals in some enclosing block/method/procedure
- ugh. Pascal, Ada, and friends offer their own unique kind of pain.
Q: does the current block support recursion? Example: for procedures
the answer would be yes; for nested { { } } blocks in C the answer
would be no.
- if no recursion, just count back some number of frame pointers based
on source code nesting
- if recursion, you need an extra pointer field in activation record
to keep track of the "static link", follow static link back some
# of times to find a name defined in an enclosing scope
Sizing up your Regions and Activation Records
Add a size field to every symbol table entry. Many types are not required
for your C370 project but we might want to discuss them anyhow.
- The size of integers is 4 (for x86; varies by CPU).
- The size of reals is... ? (for x86; varies by CPU).
- The size of strings is... <= 256? You could allocate static
256 character arrays in the global area, but better to do them as a
descriptor consisting of a length and a pointer.
- The size of arrays is (sizeof (struct descrip)) * the number of elements? Do we know an array size?
- Are arrays all int, or all real, or can they be mixed?
(in BASIC and other dynamic languages, they can be mixed!)
- Are there arrays of strings? -- yes
- what about sizes of structs?
You do this sizing up once for each scope. The size of each scope is the
sum of the sizes of symbols in its symbol table.
Run Time Type Information
Some languages would need the type information around at runtime; for
example, dynamic object-oriented languages. Its almost the case that one
just writes the type information, or symbol table information that includes
type information, into the generated code in this case, but perhaps one
wants to attach it to the actual values held at runtime.
struct descrip {
short type;
short size;
union {
char *string;
int ival;
float rval;
struct descrip *array;
/* ... for other types */
} value;
};
Compute the Offset of Each Variable
Add an address field to every symbol table entry.
The address contains a region plus an offset in that region.
No two variables may occupy the same memory at the same time.
Locals and Parameters are not Contiguous
For each function you need either to manage two separate regions
for locals and for parameters, or else you need to track where
in that region the split between locals and parameters will be.
Basic Blocks
Basic blocks are defined to be sequence of 1+ instructions in which
there are no jumps into or out of the middle. In the most extreme
case, every instruction is a basic block. Start from that perspective
and then lump adjacent instructions together if nothing can come between
them.
What are the basic blocks in the following 3-address code?
("read" is a 3-address code to read in an integer.)
read x
t1 = x > 0
if t1 == 0 goto L1
fact = 1
label L2
t2 = fact * x
fact = t2
t3 = x - 1
x = t3
t4 = x == 0
if t4 == 0 goto L2
t5 = addr const:0
param t5 ; "%d\n"
param fact
call p,2
label L1
halt
Basic blocks are often used in order to talk about
specific types of optimizations that rely on basic blocks. So if they are
used for optimization, why did I introduce basic blocks? You can view
every basic block as a hamburger; it will be a lot easier to eat if you
sandwich it inside a pair of labels (first and follow)!
Intermediate Code for Control Flow
Code for control flow (if-then, switches, and loops) consists of
code to test conditions, and the use of goto instructions and
labels to route execution to the correct code. Each chunk of code
that is executed together (no jumps into or out of it) is called
a basic block. The basic blocks are nodes in a control flow graph,
where goto instructions, as well as falling through from one basic block
to another, are edges connecting basic blocks.
Depending on your source language's semantic rules for things like
"short-circuit" evaluation for boolean operators, the operators
like || and && might be similar to + and * (non-short-circuit) or
they might be more like if-then code.
A general technique for implementing control flow code is to add
new attributes to tree nodes to hold labels that denote the
possible targets of jumps. The labels in question are sort of
analogous to FIRST and FOLLOW; for any given list of instructions
corresponding to a given tree node,
we might want a .first attribute to hold the label for the beginning
of the list, and a .follow attribute to hold the label for the next
instruction that comes after the list of instructions. The .first
attribute can be easily synthesized. The .follow attribute must be
inherited from a sibling.
The labels have to actually be allocated and attached to instructions
at appropriate nodes in the tree corresponding to grammar production
rules that govern control flow. An instruction in the middle of a
basic block need neither a first nor a follow.
| C code | Attribute Manipulations
|
|---|
| S->if E then S1 | E.true = newlabel();
E.false = S.follow;
S1.follow = S.follow;
S.code = E.code || gen(LABEL, E.true)||
S1.code
|
| S->if E then S1 else S2
| E.true = newlabel();
E.false = newlabel();
S1.follow = S.follow;
S2.follow = S.follow;
S.code = E.code || gen(LABEL, E.true)||
S1.code || gen(GOTO, S.follow) ||
gen(LABEL, E.false) || S2.code
|
Exercise: OK, so what does a while loop look like?
lecture #20 began here
Announcement
Co-op positions available for fall 2006 at Los Alamos
National Laboratory-in the Computing, Telecommunications, and
Networking Division.
LANL is seeking outstanding SOPHOMORE, JUNIOR AND NON-
GRADUATING SENIOR LEVEL Computer Science majors to work in
the areas of networking, desktop support, high performance
computing or software engineering. Positions are available
for the fall 2006 semester. MUST HAVE A GPA OF 3.0 OR HIGHER.
To request a referral go to www.nmsu.edu/pment, click on "Co-
op Job Listings", Job #86 or call the co-op office at 646-
4115. LANL is requiring a cover letter to also be sent,
please send that via email at coop@nmsu.edu in the subject
line put attn: LANL cover letter.
Co-op Office
646-4115
More on Generating Code for Boolean Expressions
Last time we started to look at code generation for control structures
such as if's and while's. Of course, before we can see the big
picture on these we have to understand how to generate code for the
boolean expressions that control these constructs.
Comparing Regular and Short Circuit Control Flow
Different languages have different semantics for booleans; for example
Pascal treats them as identical to arithmetic operators, while the
C family of languages (and many ) others specify "short-circuit"
evaluation in which operands are not evaluated once the answer to
the boolean result is known. Some ("kitchen-sink" design) languages
have two sets of boolean operators: short circuit and non-short-circuit.
(Does anyone know a language that has both?)
Implementation techniques for these alternatives include:
- treat boolean operators same as arithmetic operators, evaluate
each and every one into temporary variable locations.
- add extra attributes to keep track of code locations that are
targets of jumps. The attributes store link lists of those instructions
that are targets to backpatch once a destination label is known.
Boolean expressions' results evaluate to jump instructions and program
counter values (where you get to in the code implies what the boolean
expression results were).
- one could change the machine execution model so it implicity routes
control from expression failure to the appropriate location. In
order to do this one would
- mark boundaries of code in which failure propagates
- maintain a stack of such marked "expression frames"
Non-short Circuit Example
a<b || c<d && e<f
translates into
100: if a<b goto 103
t1 = 0
goto 104
103: t1 = 1
104: if c<d goto 107
t2 = 0
goto 108
107: t2 = 1
108: if e<f goto 111
t3 = 0
goto 112
111: t3 = 1
112: t4 = t2 AND t3
t5 = t1 OR t4
Short-Circuit Example
a<b || c<d && e<f
translates into
if a<b goto L1
if c<d goto L2
goto L3
L2: if e<f goto L1
L3: t = 0
goto L4
L1: t = 1
L4: ...
Note: L3 might instead be the target E.false; L1 might instead be E.true;
no computation of a 0 or 1 into t might be needed at all.
While Loops
So, a while loop, like an if-then, would have attributes similar to:
| C code | Attribute Manipulations
|
|---|
| S->while E do S1 | E.true = newlabel();
E.false = S.follow;
S1.follow = E.first;
S.code = gen(LABEL, E.first) ||
E.code || gen(LABEL, E.true)||
S1.code ||
gen(GOTO, E.first)
|
C for-loops are trivially transformed into while loops, so they pose no new
code generation issues.
lecture #21 began here
Intermediate Code Generation Examples
Consider the following small program. It would be fair game as input
to your compiler project. In order to show blow-by-blow what the code
generation process looks like, we need to construct the syntax tree and
do the semantic analysis steps.
void main()
{
int i;
i = 0;
while (i < 20)
i = i * i + 1;
print(i);
}
This code has the following syntax tree

Intermediate Code Generation Example (cont'd)
Here is an example C progrma to compile:
i = 0;
if (i >= 20) goto L50;
i = i * i + 1;
goto 20;
print(i);
This program corresponds to the following syntax tree, which a
successful homework #5 would build. Note that it has a height of
approximately 10, and a maximum arity of approximately 4. Also: your
exact tree might have more nodes, or slightly fewer; as long as the
information and general shape is there, such variations are not a problem.
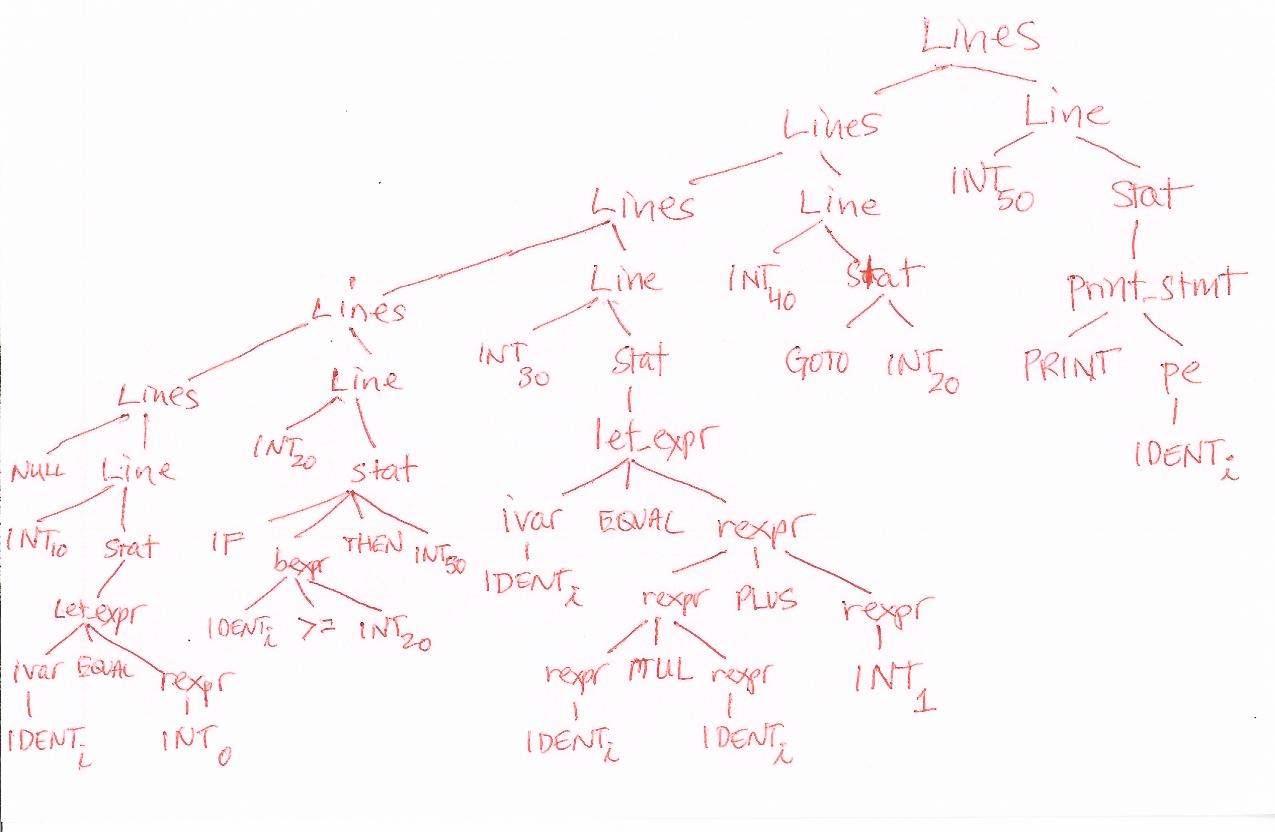 A syntax tree, with attributes obtained from lexical and semantic
analysis, needs to be shown here.
During semantic analysis, it is discovered that "print" has not been
defined, so let it be:
A syntax tree, with attributes obtained from lexical and semantic
analysis, needs to be shown here.
During semantic analysis, it is discovered that "print" has not been
defined, so let it be:
void print(int i) { }
The code for the boolean conditional expression controlling the while
loop is a list of length 1, containing the instruction t0 = i < 20,
or more formally
| opcode | dest | src1 | src2 |
|---|
| LT | t0 | i | 20 |
The actual C representation of addresses dest, src1, and src2 is probably as a
pair, so the
picture of this intermediate code instruction really looks something like this:
| opcode | dest | src1 | src2 |
|---|
| LT | local
t0.offset | local
i.offset | const
20 |
Regions are expressed with a simple integer encoding like:
global=1, local=2, const=3.
Note that address values in all regions are offsets from the start of the
region, except for region "const", which
stores the actual value of a single integer as its offset.
| opcode | dest | src1 | src2 |
|---|
| MUL | local
t1.offset | local
i.offset | local
i.offset |
lecture #22 began here
Comments on Trees and Attributes
The main problem in semantic analysis and intermediate code generation is to
Move Information Around the Tree. Moving information up the tree is kind of
easy and follows the pattern we used to build the tree in the first place.
To move the information down the tree, needed for HW4, you write tree
traversal functions. The tree traversal is NOT a "blind" traversal that does
the same thing at each node. It has a switch statement on what grammar rule
was used to build each node, and often does different work depending on what
nonterminal and what grammar rule a given node represents.
Traversal code example
The following code sample illustrates a code generation tree traversal.
Note the gigantic switch statement. In class a student asked the question
of whether the link lists might grow longish, and if one is usually appending
instructions on to the end, wouldn't a naive link list do a terrible
O(n2) job. To which the answer was: yes, and it would be good
to use a smarter data structure, such as one which stores both the head
and the tail of each list.
void codegen(nodeptr t)
{
int i, j;
if (t==NULL) return;
/*
* this is a post-order traversal, so visit children first
*/
for(i=0;i<t->nkids;i++)
codegen(t->child[i]);
/*
* back from children, consider what we have to do with
* this node. The main thing we have to do, one way or
* another, is assign t->code
*/
switch (t->label) {
case PLUS: {
t->code = concat(t->child[0].code, t->child[1].code);
g = gen(PLUS, t->address,
t->child[0].address, t->child[1].address);
t->code = concat(t->code, g);
break;
}
/* ... really, we need a bazillion cases, perhaps one for each
* production rule (in the worst case)
*/
default:
/* default is: concatenate our children's code */
t->code = NULL;
for(i=0;i<t->nkids;i++)
t->code = concat(t->code, t->child[i].code);
}
}
Code generation examples
Let us build one operator at a time. You should implement your
code generation the same way, simplest expressions first.
Zero operators.
if (x) S
translates into
if x != 0 goto L1
goto L2
label L1
...code for S
label L2
or if you are being fancy
if x == b goto L1
...code for S
label L1
I may do this without comment in later examples, to keep them short.
One relational operator.
if (a < b) S
translates into
if i >= b goto L1
...code for S
label L1
One boolean operator.
if (a < b && c > d) S
translates into
if (a < b)
if (c > d)
...code for S
which if we expand it
if i >= b goto L1
if c <= d goto L2
...code for S
label L2
label L1
by mechanical means, we may wind up with lots of labels for the same
target, this is OK.
if (a < b || c > d) S
translates into
if (a < b) ...code for S
if (c > d) ...code for S
but its unacceptable to duplicate the code for S! It might be huge!
Generate labels for boolean-true-yes-we-do-this-thing, not just for
boolean-false-we-skip-this-thing.
if a < b goto L1
if c > d goto L2
goto L3
label L2
label L1
...code for S
label L3
Array subscripting!
So far, we have only said, if we passed an array as a parameter we'd have to
pass its address. 3-address instructions have an "implicit dereferencing
semantics" which say all addresses' values are fetched / stored by default.
So when you say t1 := x + y, t1 gets values at addresses x and y, not the
addresses. Once we recognize arrays are basically a pointer type, we need
3-address instructions to deal with pointers.
now, what about arrays? reading an array value: x = a[i]. Draw the
picture. Consider the machine uses byte-addressing, not word-addressing.
t0 := addr a
t1 := i * 4
t2 := plus t0 t1
t3 := deref t2
x := t3
What about writing an array value?
Debugging Miscellany
Prior experience suggests if you are having trouble debugging, check:
- makefile .h dependencies!
- if you do not list makefile dependencies for important .h files,
you may get coredumps!
- traversing multiple times by accident?
- at least in my version, I found it easy to accidentally re-traverse
portions of the tree. this usually had a bad effect.
- bad grammar?
- our sample grammar was adapted from good sources, but don't assume its
impossible that it could have a flaw or that you might have messed it up.
lecture #23 began here
Remind me to come back to HW #6 before the end of
today's lecture.
Final Code
Goal: execute the program we have been translating, somehow.
Alternatives:
- interpret the source code
- we could have build an interpreter instead of a compiler, in which the
source code was kept in string or token form, and re-parsed every
execution. Early BASIC's did this, but it is Really Slow.
- interpret the parse tree
- we could have written an interpreter that executes the program
by walking around on the tree doing traversals of various subtrees.
This is still slow, but successfully used by many "scripting languages".
- interpret the 3-address code
- we could interpret the link-list or a more compact binary representation
of the intermediate code
- translate into VM instructions
- popular virtual machines such as JVM or .Net allow execution from an
instruction set that is often higher level than hardware, may be
independent of the underlying hardware, and may be oriented toward
supporting the specific language features of our source language.
For example, there are various BASIC virtual machines out there.
- translate into "native" instructions
- "native" generally means hardware instructions.
In mainstream compilers,
final code generation takes a linear sequence of 3-address intermediate
code instructions, and translates each 3-address instruction into one or
more native instructions.
The big issues in code generation are (a) instruction selection, and (b)
register allocation and assignment.
Collecting Information Necessary for Final Code Generation
- a top-down approach to learning your native target code is to
study a reference work supplied by the chip manufacturer, such
as the Intel 80386 Programmer's Reference Manual
- a bottom-up approach to learning your native target code is to
study an existing compiler's native code. For example, running
"gcc -S foo.c" will compile foo.c into a human-readable native
assembler code equivalent foo.s file which you can examine.
By systematically studying .s files for various toy C programs
you can learn native instructions corresponding to each C construct,
including ones equivalent to the various 3-address instructions.
Instruction Selection
The hardware may have many difference sequences of instructions to
accomplish a given task. Instruction selection must choose a particular
sequence. At issue: how many registers to use, whether a special
case instruction is available, and what addressing mode(s) to use. Given
a choice among equivalent/alternaive sequences, the decision on which
sequence of instructions to use is based on estimates or measurements of
which sequence executes the fastest. This is usually determined by the
number of memory references incurred during execution, including the
memory references for the instructions themselves. Simply picking the
shortest sequence of instructions is often a good approximation of the
optimal result, since fewer instructions usually translates into fewer
memory references.
Register Allocation and Assignment
Accessing values in registers is much much faster than accessing main memory.
Register allocation denotes the selection of which variables will go
into registers. Register assignment is the determination of exactly
which register to place a given variable. The goal of these operations
is generally to minimize the total number of memory accesses required
by the program.
In the Old Days, there were Load-Store hardware architectures in which
only one (accumulator) register was present. On such an architecture,
register allocation and assignment is not needed; the compiler has few
options about how it uses the accumulator register. Traditional x86
16-bit architecture was only a little better than a load-store architecture,
with 4 registers instead of 1. At the other extreme, Recent History has
included CPU's with 32 or more general purpose registers. On such systems,
high quality compiler register allocation and assignment makes a huge
difference in program execution speed. Unfortunately, optimal register
allocation and assignment is NP-complete, so compilers must settle for
doing a "good" job.
Discussion of Tree Traversals that perform Semantic Tests.
Suppose we have a grammar rule
AssignStmt : Var EQU Expr.
We might extend the C semantic action for that rule with
extra code after building our parse tree node:
AssignStmt : Var EQU Expr { $$ = alctree(..., $1, $2, $3);
lvalue($1);
rvalue($3);
}
lvalue() and rvalue() are mini-tree traversals for the lefthand side
and righthand side of an assignment statement. Their missions are to
propagate information from the parent, namely, inherited attributes
that tell nodes whether their values are being assigned to (initialized)
or being read from.
void lvalue(struct tree *t)
{
if (t->label == IDENT) {
struct symtabentry *ste = lookup(t->u.token.name);
ste->lvalue = 1;
}
for (i=0; inkids; i++) {
lvalue(t->child[i]);
}
}
void rvalue(struct tree *t)
{
if (t->label == IDENT) {
struct symtabentry *ste = lookup(t->u.token.name);
if (ste->lvalue == 0) warn("possible use before assignment");
}
for (i=0; inkids; i++) {
lvalue(t->child[i]);
}
}
What is different about real life as opposed to this toy example
In real life, you should build a flow graph, and propagate these
variable definition and use attributes using the flow graph instead
of the syntax tree. For example, if the program starts by calling
a subroutine at the bottom of code which initializes all the
variables, the flow graph will not be fooled into generating warnings
like you would if you just started at the top of the code and checked
whether for each variable, assignments appear earlier in the source
code than the uses of that variable.
lecture #24 began here
Runtime Systems
Every compiler (including yours) needs a runtime system. A runtime system
is the set of library functions and possibly global variables maintained by
the language on behalf of a running program. You use one all the time; in C
it functions like printf(), plus perhaps internal compiler-generated calls
to do things the processor doesn't do in hardware.
So you need a runtime system; potentially, this might be as big or bigger a
job than writing the compiler. Languages vary from assembler (no runtime
system) and C (small runtime system, mostly C with some assembler) on up to
Java (large runtime system, mostly Java with some C) and in even higher level
languages the compiler may evaporate and the runtime system become gigantic.
The Unicon language has a relatively trivial compiler and gigantic virtual
machine and runtime system. Other scripting languages might have no compiler
at all, doing everything (even lexing and parsing) in the runtime system.
For your project: whether you generate C or X86 or Java, you'll need a plan
for what to do about a runtime system. And, in principle, I am not opposed
to helping with this part. But the compiler and runtime system have to fit
together; if I write part of the BASIC runtime system for you, or we write
it together, we have to agree on things such as: what the types of
parameters and return values must look like.
So, what belongs in a Color BASIC runtime system? Anything not covered
by a three address instruction. Looking at cocogram.y:
- INPUT/PRINT
- READ/DATA
- CLEAR
- CLOAD/CSAVE/SKIPF
- CLS
- SET/RESET
- SOUND
- CHR$, LEFT$, MID$, RIGHT$, INKEY$
- ASC, INT, JOYSTK, LEN, PEEK, RND, VAL
- DIM
- string +, string compares
What would a runtime system function look like? It would take in and
pass out BASIC values, represented as C structs. You would then link
this code in to your generated C or assembler code (if you generated
Java code, you would have to deal with the Java Native Interface or
else write these functions in Java).
void PRINT(struct descrip *d)
{
switch (d->type) {
case INTEGER: printf("%d",d->value.ival); break;
case REAL: printf("%f",d->value.rval); break;
case STRING: printf("%*s",d->size,d->value.string); break;
case ARRAY: printf("cannot print arrays"); break; /* can't get here */
default: printf("PRINT: internal error, type %d\n", d->type);
}
}
Now, let's look at the "whole" runtime system:
More on Memory Management in the BASIC Runtime System
Arrays are interesting. They can be used without being declared or DIM'ed.
They can only be DIM'ed once. If you use them before they are DIM'ed, they
are implicitly DIM'ed to size 11 and can't be re-DIM'ed.
What do variables A, A(), A$, and A$() look like in memory? How does our
runtime system make it so?
Let's take a look at DIM, in libc.c. This DIM is for arrays of numbers.
How would you handle arrays of strings?
Can you implement STRCAT for your BASIC runtime system?
What other BASIC statements, operators, or functions allocate memory?
How would we avoid memory "leaks"?
Final Project comments
- We have a week of classes more, plus a couple weekends, before your
final project (HW#7) is due.
- Really, really, test your turnin, by "turning your .tar in to
yourself": unpacking in a separate directly, and verifying that it builds
and runs correctly in a separate subdirectory. Turnins that do not
compile and run due to missing files, etc. may receive a 0.
- You are invited and encouraged, but not required, to make an appointment
to demo your compiler with me during Finals week. The purpose is to
make sure you get credit for those parts which you can show me are
working (as opposed to me testing your program independently and
somehow missing the parts that work).
- Student assignments which have "impossible similarity" to each other
may result in a 0 for the assignment or an "F" for the course.
Impossible similarity means: beyond a reasonable doubt, substantial
code other than sample code fragments provided in lecture or lab notes,
has been shared or copied.
STRCAT
So, what does your STRCAT look like? Here's one.
GOSUBs
Our 3-address instruction set has call and return instructions, but basic
is less structured than regular procedural languages; you can GOSUB to any
line number you want. You can't use a variable to GOSUB to line number X,
but in principle every line number could be the target of a procedure call.
If you use the "call" (3-address) instruction to do GOSUB, your native code
will have to make a clear distinction between BASIC call's and calls to
runtime system (built-in) functions. Perhaps it is best to implement BASIC
GOSUB by pushing a "param" (the next instruction following the GOSUB) and
a "goto". The BASIC RETURN is then a "pop" followed by a "goto". What,
we don't have a "pop" 3-address instruction? We do now... the name of
"param" should probably be "push" anyhow.
Come to think of it, we've been talking about doing a call to a built-in
function such as PRINT, but that PRINT function we wrote is C code; it
doesn't do a 3-address "ret" instruction, hmmm. How are we going to
generate the native code for the 3-address "call" instruction?
It may include an assembler call instruction, but it may also involve
instructions to handle the interface between BASIC and C.
lecture #25 began here
Register Allocation and Assignment (cont'd)
When the number of variables in use at a given time exceeds the number
of registers available (the common case), some variables may be used
directly from memory if the instruction set supports memory-based operations.
When an instruction set does not support memory-based operations, all
variables must be loaded into a register in order to perform arithmetic
or logic using them.
Even if an instruction set does support memory-based operations, most
compilers will want to load load a value into a register while it is
being used, and then spill it back out to main memory when the register
is needed for another purpose. The task of minimizing memory accesses
becomes the task of minimizing register loads and spills.
Some Code Generation Examples
Reusing a Register
Consider the statement:
a = a+b+c+d+e+f+g+a+c+e;
Our naive three address code generator would generate a
lot of temporary variables here, when really one big number is being added.
How many registers does the expression need? Some variables
are referenced once, some twice. GCC generates:
movl b, %eax
addl a, %eax
addl c, %eax
addl d, %eax
addl e, %eax
addl f, %eax
addl g, %eax
addl a, %eax
addl c, %eax
addl e, %eax
movl %eax, a
Now consider
a = (a+b)*(c+d)*(e+f)*(g+a)*(c+e);
How many registers are needed here?
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
imull %eax, %edx
movl f, %eax
addl e, %eax
imull %eax, %edx
movl a, %eax
addl g, %eax
imull %eax, %edx
movl e, %eax
addl c, %eax
imull %edx, %eax
movl %eax, a
And now this:
a = ((a+b)*(c+d))+((e+f)*(g+a))+(c*e);
which compiles to
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
movl %edx, %ecx
imull %eax, %ecx
movl f, %eax
movl e, %edx
addl %eax, %edx
movl a, %eax
addl g, %eax
imull %edx, %eax
leal (%eax,%ecx), %edx
movl c, %eax
imull e, %eax
leal (%eax,%edx), %eax
movl %eax, a
Lastly (for now) consider:
a = ((a+b)*(c+d))+(((e+f)*(g+a))/(c*e));
The division instruction adds new wrinkles. It operates on an implicit
register accumulator which is twice as many bits as the number you divide
by, meaning 64 bits (two registers) to divide by a 32-bit number. Note
in this code that gcc would rather spill than use %ebx. %ebx is either
being used implicitly or is reserved by the compiler for some (probably
good) reason. %edi and %esi are similarly ignored.
movl b, %eax
movl a, %edx
addl %eax, %edx
movl d, %eax
addl c, %eax
movl %edx, %ecx
imull %eax, %ecx
movl f, %eax
movl e, %edx
addl %eax, %edx
movl a, %eax
addl g, %eax
imull %eax, %edx
movl c, %eax
imull e, %eax
movl %eax, -4(%ebp)
movl %edx, %eax
cltd
idivl -4(%ebp)
movl %eax, -4(%ebp)
movl -4(%ebp), %edx
leal (%edx,%ecx), %eax
movl %eax, a
Code Generation for Virtual Machines
A virtual machine architecture such as the JVM changes the "final" code
generation somewhat. We have seen several changes, some of which
simplify final code generation and some of which complicate things.
- no registers, simplified addressing
- a virtual machine may omit a register model and avoid complex
addressing modes for different types of variables
- uni-size or descriptor-based values
- if all variables are "the same size", some of the details of
memory management are simplified. In Java most values occupy
a standard "slot" size, although some values occupy two slots.
In Icon and Unicon, all values are stored using a same-size descriptor.
- runtime type system
- requiring type information at runtime may complicate the
code generation task since type information must be present
in generated code. For example in Java method invocation and
field access instructions must encode class information.
Just for fun, let's compare the generated code for java with that X86
native code we were just looking at:
iload_1
iload_2
iadd
iload_3
iload 4
iadd
imul
iload 5
iload 6
iadd
iload 7
iload_1
iadd
imul
iload_3
iload 5
imul
idiv
iadd
istore_1
lecture #26 began here
A Shallow Introduction to Code Optimization
There are major classes of optimization that can significantly speedup
a compiler's generated code. Usually you speed up code by doing the
work with fewer instructions and by avoiding unnecessary memory reads
and writes. You can also speed up code by rewriting it with fewer gotos.
Peephole Optimization
Peephole optimizations look at the native code through a small, moving
window for specific patterns that can be simplified. These are some of the
easiest optimizations because they potentially don't require any analysis
of other parts of the program in order to tell when they may be applied.
Although some of these are stupid and you wouldn't think they'd come up,
the simple code generation algorithm we presented earlier is quite stupid
and does all sorts of obvious bad things that we can avoid.
| name
| sample
| optimized as
|
| redundant load or store
|
MOVE R0,a
MOVE a,R0
|
MOVE R0,a
|
| dead code
|
#define debug 0
...
if (debug) printf("ugh");
|
| control flow simplification
|
if a < b goto L1
...
L1: goto L2
|
if a < b goto L2
...
L1: goto L2
|
| algebraic simplification
|
x = x * 1;
|
| strength reduction
|
x = y * 16;
|
x = y << 4;
|
Constant Folding
Constant folding is performing arithmetic at compile-time when the values
are known. This includes simple expressions such as 2+3, but with more
analysis
some variables' values may be known constants for some of their uses.
x = 7;
...
y = x+5;
Common Subexpression Elimination
Code that redundantly computes the same value occurs fairly frequently,
both explicitly because programmers wrote the code that way, and implicitly
in the implementation of certain language features.
Explicit:
(a+b)*i + (a+b)/j;
The (a+b) is a common subexpression that you should not have to compute twice.
Implicit:
x = a[i]; a[i] = a[j]; a[j] = x;
Every array subscript requires an addition operation to compute the memory
address; but do we have to compute the location for a[i] and a[j] twice in
this code?
Loop Unrolling
Gotos are expensive (do you know why?). If you know a loop will
execute at least (or exactly) 3 times, it may be faster to copy the
loop body those three times than to do a goto. Removing gotos
simplifies code, allowing other optimizations.
for(i=0; i<3; i++) {
x += i * i;
y += x * x;
}
|
x += 0 * 0;
y += x * x;
x += 1 * 1;
y += x * x;
x += 2 * 2;
y += x * x;
|
y += x * x;
x += 1;
y += x * x;
x += 4;
y += x * x;
|
Hoisting Loop Invariants
for (i=0; i<strlen(s); i++)
s[i] = tolower(s[i]);
|
t_0 = strlen(s);
for (i=0; i<t_0; i++)
s[i] = tolower(s[i]);
|
Interprocedural Optimization
Considering memory references across procedure call boundaries;
for example, one might pass a parameter in a register if both
the caller and callee generated code knows about it.
argument culling
when the value of a specific parameter is a constant, a custom version
of a called procedure can be generated, in which the parameter is
eliminated, and the constant is used directly (may allow additional
constant folding).
f(x,r,s,1);
int f(int x, float y, char *z, int n)
{
switch (n) {
case 1:
do_A; break;
case 2:
do_B; break;
...
}
}
|
f_1(x,r,s);
int f_1(int x, float y, char *z)
{
do_A;
}
int f_2(int x, float y, char *z)
{
do_B;
}
...
|
Final Exam Review
The final exam is comprehensive, but with a strong emphasis on "back end"
compiler issues: symbol tables, semantic analysis, and code generation.
- Review your lexical analysis, regular expressions, and finite automata.
- Review your syntax analysis, CFG's, and parsing.
- If a parser discovers a syntax error, how can it report what line
number that error occurs on? If semantic analysis discovers a
semantic error (or probable semantic error), how can it report what
line number that error occurs on?
- What are symbol tables?
- What are symbol tables used for? What information is stored there?
- How does information get into a symbol table?
- How many symbol tables does a compiler need?
- What is "semantic analysis"?
- What does "semantic analysis" accomplish? What are its side effects?
- What are the primary activities of a compiler's semantic analyzer?
- What are memory regions, and why does a compiler care?
- What memory regions are there, and how do they affect code generation?
- What does code generation do, anyhow?
- What kinds of code generation are there?
- Why do (almost all) compilers use an "intermediate code"? What does
intermediate code look like? How is it different from final code?












